This article is contributed. See the original author and article here.
This post is part of a multi-part series titled “Patterns with Azure Databricks”. Each highlighted pattern holds true to 3 principles for modern data analytics:
- A Data Lake to store all data, with a curated layer in an open-source format. The format should support ACID transactions for reliability and should also be optimized for efficient queries.
- A foundational compute layer built on open standards. The foundational compute Layer should support most core use cases for the Data Lake. This includes ETL, stream processing, data science and ML, and SQL analytics on the data lake. Standardizing on a foundational compute service provides consistency across the majority of use cases. Being built on open standards ensures rapid innovation and a non-locking, future-proof architecture.
- Easy integration for additional and/or new use cases. No single service can do everything. There are always going to be new or additional use cases that aren’t best handled by the foundational compute layer. Both the open, curated data lake and the foundational compute layer should provide easy integration with other services to tackle these specialized use cases.
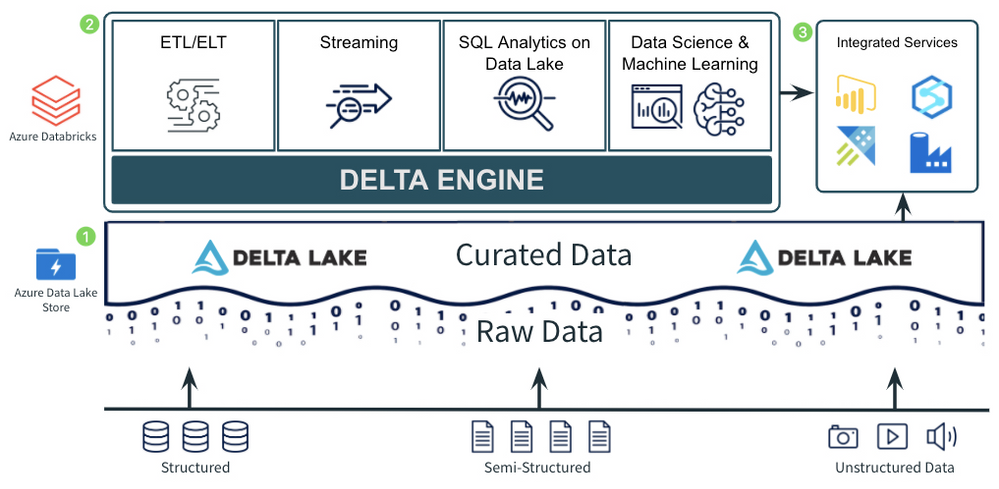
Pattern for Ingestion, ETL, and Stream Processing
Companies need to ingest data in any format, of any size, and at any speed into the cloud in a consistent and repeatable way. Once that data is ingested into the cloud, it needs to be moved into the open, curated data lake, where it can be processed further to be used by high value use cases such as SQL analytics, BI, reporting, and data science and machine learning.

The diagram above demonstrates a common pattern used by many companies to ingest and process data of all types, sizes, and speed into a curated data lake. Let’s look at the 3 major components of the pattern:
- There are several great tools in Azure for ingesting raw data from external sources into the cloud. Azure Data Factory provides the standard for importing data on a schedule or trigger from almost any data source and landing it in its raw format into Azure Data Lake Storage/Blob Storage. Other services such as Azure IoT Hub and Azure Event Hubs provide fully managed services for real time ingestion. Using a mix of Azure Data Factory and Azure IoT/Event Hubs should allow a company to get data of just about any type, size, and speed into Azure.
- After landing the raw data into Azure, companies typically move it into the raw, or Bronze, layer of the curated data lake. This usually means just taking the data in its raw, source format, and converting it to the open, transactional Delta Lake format where it can be more efficiently and reliably queried and processed. Ingesting the data into the Bronze curated layer can be done in a number of ways including:
- Basic, open Apache Spark APIs in Azure Databricks for reading streaming events from Event/IoT Hubs and then writing those events or raw files to the Delta Lake format.
- The COPY INTO command to easily copy data from a source file/directory directly into Delta Lake.
- The Azure Databricks Auto Loader to efficiently grab files as they arrive in the data lake and write them to the Delta Lake format.
- The Azure Data Factory Copy Activity which supports copying data from any of its supported formats into the Delta Lake format.
- After the raw data has been ingested to the Bronze layer, companies perform additional ETL and stream processing tasks to filter, clean, transform, join, and aggregate the data into more curated Silver and Gold datasets. Using Azure Databricks as the foundational service for these processing tasks provides companies with a single, consistent compute engine (the Delta Engine) built on open standards with support for programming languages they are already familiar with (SQL, Python, R, Scala). It also provides them with repeatable DevOps processes and ephemeral compute clusters sized to their individual workloads.



The ingestion, ETL, and stream processing pattern discussed above has been used successfully with many different companies across many different industries and verticals. It also holds true to the 3 principles discussed for modern data analytics: 1) using an open, curated data lake for all data (Delta Lake), 2) using a foundational compute layer built on open standards for the core ETL and stream processing (Azure Databricks), and 3) using easy integrations with other services like Azure Data Factory and IoT/Event Hubs which specialize in ingesting data into the cloud.
If you are interested learning more about Azure Databricks, attend an event, and check back soon for additional blogs in the “Patterns with Azure Databricks” series.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments