This article is contributed. See the original author and article here.
Introduction
For-each loop is a common construct in many languages, allowing collections of items to be processed the same way. Within Logic Apps, for-each loops offer a way to process each item of a collection in parallel – using a fan-out / fan-in approach that, in theory, speeds up the execution of a workflow.
But for-each loop in Logic Apps, in both Consumption and Standard skus, has been a performance pain point because of how they are executed under the hood. To provide resiliency and distributed execution at scale, performance end up being sacrificed, as a lot of execution metadata must be stored and retrieved from Azure Storage, which adds network and I/O latency, plus extra compute cost, thanks to serialization/deserialization.
With stateless workflows, an opportunity to improve the performance of for-each loop arises. As stateless workflows run in-memory and are treated as atomic items, the resiliency and distribution requirements can be removed – this removes a dependency on Azure Storage to store the state of each action, which removes both I/O and networking latency, while also removing most of the serialization/deserialization costs.
The original for-each loop code was shared between stateful and stateless workflows. But as performance on stateless was not scaling we rethought the way we execute for-each loop in the context of a Stateless workflow. Those changes almost doubled the performance of for-each loop within the context of stateless, as we were able to achieve a 91% speedup in our benchmark scenario.
Benchmark
In order to compare the performance of a stateless workflow before and after the code changes, we used a familiar scenario – which we used for our previous performance benchmark blogpost, modifying it slightly to process a batch of messages using a for-each loop instead of the split-on technique we used previously. You can find the modified workflow definitions here.
We deployed the same workflow to two Logic Apps – one which used the previous binaries and another running the optimized binaries – and used a payload of 100 messages in an array delivered by a single POST request. The for-each loop turned this into 100 iterations, executing with a concurrency limit of 10. We then measured the time it took for each Logic App to complete all 100 iterations. The total execution time can be found below:
Batch Execution (100 messages) | Total execution time (seconds) |
Previous binaries | 30.91 |
Optimized binaries | 16.24 |
As per results above we confirmed that the optimized app took 47.6% less time to execute, which means 90.7% execution speedup.
Analysis
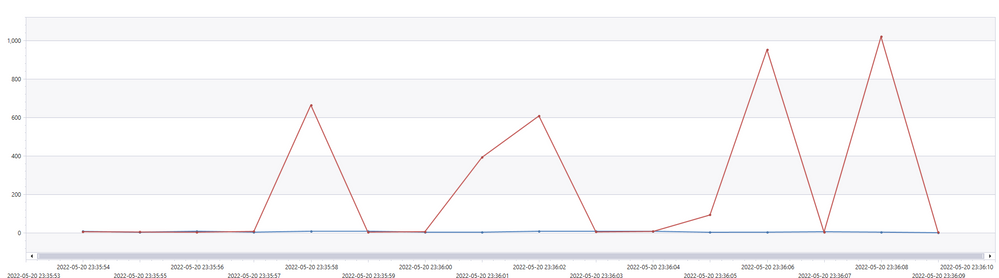
Two interesting graphs are that of execution delay and jobs per second.
Execution delay is the time difference between when a job was scheduled to be executed and when it was actually executed. Lower is better.
Red = unoptimized
Blue = optimized
From the graph, we see that the unoptimized execution experienced spikes in executing delay. This was due to a synchronization mechanism that we used to wait for a distributed batches of for-each repetition to complete. We were able to optimize that delay away.
Jobs per second is another metric that we looked at because under the hood, all workflows are translated into a sequence of jobs. Higher is better.

Red = unoptimized
Blue = optimized
We can see that the optimized version remains higher and steadier, meaning that compute resources were more efficiently utilized.
What about Stateful workflows?
As Stateful workflows still run in a distributed manner like Consumption workflows, this optimization is not directly applicable. To maximize the performance of a for-each loop in Stateful, the most important factor is to make sure the app is scaling out enough to handle the workload.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments