This article is contributed. See the original author and article here.
In the article “Azure Sentinel correlation rules: Active Lists out; make_list() in,” I presented a rule that detects a number of sign-in failures to Azure AD, alongside a sign-in success to AWS from the same IP address. An inherent challenge with the rule was that the time window is defined by rule execution: if the rule is executed every hour, and an attack is split across two rule executions, no alert will be triggered.
In this blog post, we will see how to modify this rule to analyze a sliding time window, and therefore work across rule execution boundaries. While enhancing the rule time window support, we will also add support for delayed events.
This post of part of a series of blog posts on writing rules in Azure Sentinel:
- Azure Sentinel correlation rules using lists
- Azure Sentinel correlation rules using the join operator
- Implementing Lookups in Azure Sentinel
- Approximate, partial and combined lookups
- Handling sliding windows in Azure Sentinel rules (this post)
Defining the sliding window
Let start with defining the time variables for the detection:
let rule_frequency = 1h; // how often is the rule executed
let max_session = 24h; // the maximum length of a detected session
let aad_delay = 1h; // the maximum delay we anticipate for events for each source
let aws_delay = 1h;
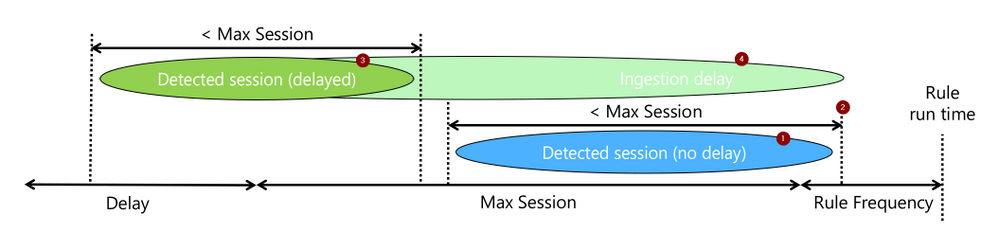
The rule attempts to detect a sequence of events (1), let’s call them a session, that took less than “max_session” and of which the last occurred within the current rule run (2). When events are expected to be delayed, we will still look for such a session (3), but require that the last event was ingested (4) within the current rule run.

The rest is just the mechanics of how to do the above.
Filtering the relevant AAD events
The rule logic itself starts, as did the simpler version, with filtering Azure AD Sign-in failures. However, if the original version did not explicitly filter on time, this one adds a time condition (green). The time condition go back as much as needed to capture sessions that ended at the beginning of the current run window, even if delayed.
let signin_threshold = 5;
let suspicious_signins =
SigninLogs
| where TimeGenerated > ago (max_session + rule_frequency + aad_delay)
| where ResultType !in ("0", "50125", "50140")
| where IPAddress != "127.0.0.1"
Identifying AAD failure sessions
Next comes the KQL magic that makes sliding windows detection easy:
- The operator row_window_session (green) searches for sessions: sequences of events no longer than max_session. It adds to each event a field, aad_first_time, which includes the time of the first event in the session and would be the same for all events in the session.
- To prepare the data for row_window_session, we sorted (red) as the operator expected sorted input. In this case, we sort by IP address, in addition to time, to ensure sessions are specific to a source IP address.
- Lastly, we analyze using the operator summarize (blue), the data we need from each session: its length and indicative timestamps.
| sort by IPAddress, TimeGenerated asc
| extend aad_first_time = row_window_session (TimeGenerated, max_session, max_session, IPAddress != prev(IPAddress))
| summarize session_count = count(), aad_last_time = max(TimeGenerated), aad_last_ingest=max(ingestion_time()) by aad_first_time , IPAddress
Filtering only relevant sessions
Once we have sessions, we need to check if indeed indicate a detection:
- Was the session count above the detection threshold? (red)
- Did the session end within the latest rule execution, adjusted to an ingestion delay? (blue)
The last line, project-rename, is just makeup. It renames IPAddress to make it easy to identify it as the AAD failure session IP address. This comes in handy after the join when multiple tables add their fields to the result set.
| where session_count >= signin_threshold
| where aad_last_time > ago (rule_frequency + aad_delay)
| project-rename aad_ip_address = IPAddress;
Note that unlike the simpler version, the result of this query part is a table and not a list, and we will use the join operator to correlate it to the AWS events. Why? We need to keep the timestamps and test them after the “join.” It would also help us provide more data to the analyst.
Want to stop here? the general aggregation case
While the rule we explore correlates sign-in failures on Azure with a successful sign-in on AWS, the more common form is simple aggregation. i.e., detection more than X events in a time window. The section we already covered address such a general use case, with the following small modifications:
- Remote the line “let suspicious_signins =“, and the semicolon at the end to make this the primary query in the rule.
- Add the line “| where aad_last_ingest > ago(rule_frequency)” to ensure the session included a new, just ingested, event and therefore was not yet reported on.
Matching the sessions to a successful AWS login event
After finding successful AWS logins (red), we match them on IP addresses to the sessions we identified earlier on using join (blue). For matches, implying we have a session of Azure failures and a successful AWS login for the same address, we test the following:
- Was any of the events ingested in the latest rule execution window (green)? This ensures the detected attack included new information and was not reported yet. This is the primary means used to support delayed events while avoiding duplicate alerting.
- Was the successful AWS event with the time window of the session? (blue). This a simple to implement choice, but not the only one. Other options can also be implemented, such as the AWS success happening after the Azure failure session. Those will require changing this time condition line and may also require extending other timeframes in the query.
The “project-rename” and “extend” operators (orange), are again cosmetic only and makes the AWS fields easy to use and identify in the joined table.
AWSCloudTrail
| where TimeGenerated > ago(max_session + rule_frequency + delay)
| where EventName == "ConsoleLogin"
| extend LoginResult = tostring(parse_json(ResponseElements).ConsoleLogin)
| where LoginResult == "Success"
| project-rename aws_time = TimeGenerated, aws_ip_address = SourceIpAddress
| extend aws_ingest_time = ingestion_time()
| join suspicious_signins on $left. aws_ip_address == $right.aad_ip_address
| where max_of(aws_ingest_time, aad_last_ingest) > ago(rule_frequency)
| where aws_time between (aad_first_time ..aad_last_time)
That’s it. The rest would be just result and entity preparation.
Rule Settings
An analytics rule is not just a query. There are several parameters that you need to set to make it work. The two critical ones are:
- -“Run query every” is the rule execution frequency and should be set to, as expected to “rule_frequency”.
- “Lookup data from the last,” or the rule’s lookback time, has to be at least as long as the most extended time condition in the rule. This would be max_session + rule_frequency + the longer of the delays, aad_delay, and aws_delay.
Also, you should configure alert aggregation based on the source IP address. A sliding window-based rule will alert when new events are extending an existing session. While it is possible to suppress such alerting, it adds information, so generating an alert that will be grouped to the same incidents is the best practice. Aggregation should be by IP address and aad_first_time, to which you should allocate one of the unused entities.
Summary
Aggregation rules and more advanced relations-based rules require careful consideration of time window management to avoid missing alerts or duplicate alerting. This article provides a recipe that should help you implement such rules correctly using a sliding window analysis.
I hope you found it useful!
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments