This article is contributed. See the original author and article here.
| Before implementing data extraction from SAP systems please always verify your licensing agreement. |
After five episodes of going through basic data extraction scenarios, we finally can deep dive into a more advanced topic. I already explained how crucial is extraction optimization. The created Synapse Pipeline can use client-side paging to chunk a large request into several smaller ones. In the last episode, we focused on data filtering to copy only the required information. Both solutions improve the performance and reliability of the extraction, but a full data copy is not always an answer. It is not uncommon to have millions or even billions of records in the largest tables. A daily extraction job to copy everything is pretty much impossible in such scenarios. It would take too much time and cause performance challenges on SAP application servers. Multiple extractions every day could cause even more problems.
So what can we do to ensure our data in the lake is almost up-to-date? The solution, at least in theory, is quite simple. We should only extract new and changed records in the system. Such an approach highly limits the amount of data to process, which decreases the duration of the copy job and it allows more frequent updates.
INTRODUCTION TO DELTA EXTRACTION
There is a GitHub repository with source code for each episode. Learn more: https://github.com/BJarkowski/synapse-pipelines-sap-odata-public |
A post about processing only new and changed data, also known as a delta or incremental extraction, was the most requested by you. I received multiple comments and even private messages asking to provide some guidance in this area. OData services have some great features to support delta extraction. That’s one of the reasons why, despite my concerns about using OData protocol for large amounts of data, I decided to write the whole blog series.
As always, please let me start with a short introduction. Extracting only changed and new information is not a new topic. Whenever we work with a large dataset, processing only a subset of information guarantees better performance and reliability. Having to copy only a couple hundred records instead of millions always makes a difference. The main problem is, however, how to select the right data.
As always, there is no single solution. Which is the right one depends on your requirements and technical possibilities. One of the most common approaches uses the date and time of last change to identify new and changed records since the last extraction. Another way of ensuring we have updated data is using triggers to record and send changes after they occur. The second approach is quite common in real-time data replication scenarios.
An important point of consideration is which system defines which are new and changed information. Using the client software, which in our case is Azure Synapse, gives us full control over what we request and copy. At the same time, we are limited to what is available at the source. If the OData service doesn’t expose a field with the timestamp of the last update, it will be nearly impossible to track changes. And unfortunately, that’s a common problem. Always work closely with your functional experts as they may know a solution. Depending on the use case, you may be able to use other fields as well – for example, posting or document date. You could also try finding another data source as it may contain a date to support delta extraction. To be honest, it doesn’t even have to be a date – using a posting period can also give good results. Of course, the number of records to process each time will be larger, but still, it is just a tiny piece of all data stored in the database. One of the common misconceptions is that you always have to fetch only new and updated records. That’s not true – you can always copy more records (for example, extract documents from the current month) and then use processing in Synapse to consolidate multiple extracts. While not perfect, such a solution often helps when the information about the last changes is unavailable.
The SAP system can also help us in identifying delta changes. It offers a set of data extractors and CDS views that out-of-the-box manages delta information, and they expose us only the data we need. That’s quite handy, as we can use pre-built processes instead of designing a pipeline to compare timestamps. Under the hood, they also often use the information about the last change. But in newer SAP releases, they also utilize the SLT framework to track changes.
While asking the SAP system to manage delta information is tempting, I would like to show you both scenarios. Therefore I will cover the delta extraction in two blog posts. In today’s episode, I’ll show you how to extract changes using timestamps stored in the metadata store. You already know how to implement filtering, so we will use that knowledge today. The solution we’ll design today is just one of many. As I mentioned earlier, there are many field types you could use. It may happen that the pipeline we create today requires some further tweaks to fulfil your use case. But I’m sure you’ll have enough knowledge to make the necessary changes on your own.
DELTA EXTRACTION USING TIMESTAMP
With OData services, we can use a wide range of query parameters to limit the data we receive. Last week I published a blog about filtering, that allows us to only extract information for a particular company code or sales organization. We can use the same approach to limit the data based on a timestamp field – ideally containing information about last changes, but creation date or posting date can also be useful.
Let’s take the API_SALES_ORDER_SRV as an example, as we worked with that service previously. The entity set A_SalesOrder exposes us Sales Order header information. It contains CreationDate field which holds the timestamp of when was the document initially created as well as the LastChangeDateTime which provides information about last changes. While that’s not always the case for other OData services, the LastChangeDateTime field is updated even if the document was just created and never edited.

In today’s post, I’ll show you what changes are required to deal with similar OData services. But there are other OData services, like the API_BUSINESS_PARTNER, that require further adjustment. Let’s take a look at a sample payload:

This OData service makes things difficult. There is no single field for the timestamp, and the last update date and time are stored in two separate fields. That makes things slightly more complex – instead of filtering using a single value, we need to use two of them. If you’d like to use the pipeline to work with such OData services, you’ll have to make additional changes on your own.
In theory, there is also a field ETag that looks useful. But in fact, this field is used to manage editing concurrency, and some SAP cloud products already prohibit filtering using the ETag value.
There is also the third type of OData service, which doesn’t expose any form of date or time information. An infamous example is the A_SalesOrderItem in the API_SALES_ORDER. If you have to process sales order line items, it’s better to find another data source, like an extractor or CDS views – next week, I will describe how to use them.
But to be fully honest with you – there are two possible workarounds. After extracting header information, you could create a list of processed sales order numbers, which then becomes a filter when selecting line items. The second potential workaround, which is not available in Synapse so far, is using the $expand query parameter. It asks SAP to include additional information in the response, like the partner information or… line items. I’ll keep an eye on new features in Synapse Pipelines, and I let you know when this parameter is fully supported.
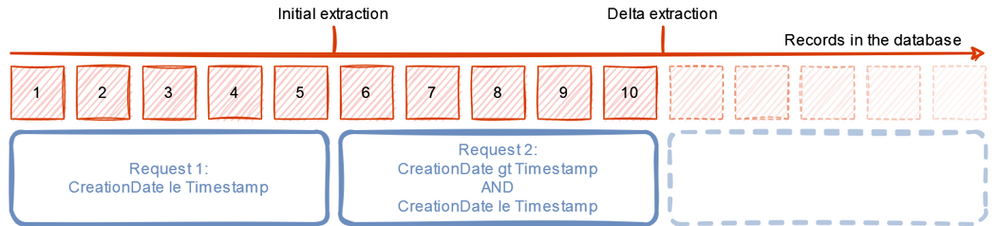
Before we make changes to the pipeline, let’s think about how the delta extraction should work. We need three additional parameters – the first one to mark we want to use delta extraction with the OData source. In the second and third parameters, we will keep the timestamp information together with the field name where it can be found in the OData source.
During the runtime, the pipeline should initially send a request to the service to retrieve the high watermark, which is the timestamp of the last change. We can do this by using Lookup activity and a couple of query parameters. The Copy Data activity will then only process orders, with the timestamp being between the value stored in the metadata store and read from the OData service. Once the extraction finishes, we have to update the metadata store with the new high watermark.
Initially, I considered implementing the above changes to the same child pipeline we’ve used so far, but finally, I decided to create a separate one to increase visibility. All OData services where the delta extraction is not required will still use the old pipeline. I will add a Switch activity in the master pipeline, that based on the value read from the metadata store, will trigger the original or delta-enabled pipeline.
IMPLEMENTATION
Let’s start making the required changes by modifying the metadata store. We need three additional fields:
- ExtractionType – which can take Full or Delta values
- Watermark – to store the timestamp value
- WatermarkField – to store the field name of the timestamp, for example, LastChangeDateTime
I have also updated my list of OData services to include two that we can consider for delta extraction (sales orders and products) and two without a timestamp field we could use.
OData service | Entity | ExtractionType | WatermarkField |
API_SALES_ORDER_SRV | A_SalesOrder | Delta | LastChangeDateTime |
API_BUSINESS_PARTNER | A_BusinessPartner | Full | |
API_COMPANYCODE_SRV | A_CompanyCode | Full | |
API_PRODUCT_SRV | A_Product | Delta | LastChangeDateTime |

Having new fields defined in the metadata store allows us to focus now on the pipeline. Open Synapse Studio and clone the existing child pipeline. Then define two parameters: Watermark and WatermarkField. As the ExtractionType property will only be used in the metadata pipeline, we don’t have to define it here.

Now we have to modify the metadata pipeline, that it triggers the correct processing depending on the content of the ExtractionType field. Open it, and enter the ForEach loop. Add the Switch activity and reference the ExtractionType in the Expression field to evaluate which pipeline to run. Then add a new Case with the value “Delta”.

The Switch activity executes the expression and maps the outcome to one of Case groups. If it can’t find a match it will process the Default group.
Move the existing Execute Pipeline activity to the default group. You don’t have to make any changes to the list of parameters.

Expand the delta group and add a new Execture Pipeline activity that triggers the delta-enabled pipeline. Set the Invoked pipeline and expand the existing list of parameters with Watermark and WatermarkField.

With the above changes, the Switch activity triggers the correct pipeline based on the value stored in the ExtractionType field. We can now proceed with the required improvements to the delta-enabled pipeline.
I want to keep the existing functionality that allows using the client-side paging as well as filtering out unnecessary data. While delta extraction reduces the amount of data in subsequent runs, we still have to ensure robust processing of the initial data extraction that copies all records. We have to update all expressions, and keeping the existing functionality means some of them can get quite lengthy.
Let’s start with an easy change. Before we check the number of records, we have to read the high watermark figure from the OData service to correctly pass the filtering to all subsequent activities. Add a new Lookup activity and reference the OData dataset. Provide the following expressions:
ODataURL: @concat(pipeline().parameters.URL, pipeline().parameters.ODataService, '/')
Entity: @pipeline().parameters.Entity
In the query field, we provide the selection criteria. To read the latest timestamp, I’m sorting the whole dataset using the $orderby parameter. We also have to maintain all filtering rules defined in the metadata store. I came up with the following query:
@if(empty(pipeline().parameters.Filter), concat('?$select=', pipeline().parameters.WatermarkField, '&$top=1&$orderby=', pipeline().parameters.WatermarkField, ' desc'), concat('?$filter=', pipeline().parameters.Filter, '&$select=', pipeline().parameters.WatermarkField, '&$top=1&$orderby=', pipeline().parameters.WatermarkField, ' desc'))

To make the timestamp value easily accessible, I decided to assign it to a variable. We haven’t used any variables so far. They are very similar to parameters, but unlike them, we can modify variables values during the runtime. Which perfectly suits our case.
In the pipeline settings, open the Variables tab and create a new one of type String.

Add the Set Variable activity and create a connection from the lookup. To read the value from the output of the previous action I’m using the following query:
@activity('l_high_watermark').output.firstRow[pipeline().parameters.WatermarkField]
As the timestamp field name is not static, but instead we read it from the metadata store, I’m using square brackets to reference it as part of the expressions (that’s quite a cool feature of ADF).

Having the high watermark value assigned to a variable, we can modify the Lookup responsible for reading the record count. We need to add functionality to count only records between the last replication and the high watermark value stored in the variable. We also have to keep in mind, that during the initial replication, the Watermark field in the metadata store is empty – which adds a little bit of complexity. I use the following expression:
@if(empty(pipeline().parameters.Filter), concat('?$filter=', if(empty(pipeline().parameters.Watermark), '', concat(pipeline().parameters.WatermarkField, ' gt datetimeoffset''', formatDateTime(pipeline().parameters.Watermark, 'yyyy-MM-ddThh:ss:sZ'), ''' and ')), pipeline().parameters.WatermarkField, ' le datetimeoffset''', formatDateTime(variables('v_watermark'), 'yyyy-MM-ddThh:ss:sZ'),''''), concat('?$filter=', pipeline().parameters.Filter, if(empty(pipeline().parameters.Watermark), '', concat(' and ', pipeline().parameters.WatermarkField, ' gt datetimeoffset''', formatDateTime(pipeline().parameters.Watermark, 'yyyy-MM-ddThh:ss:sZ'))), ''' and ', pipeline().parameters.WatermarkField, ' le datetimeoffset''', formatDateTime(variables('v_watermark'), 'yyyy-MM-ddThh:ss:sZ'),''''))

Now it’s time to edit the query in the Copy Activity. I had to admit I was a bit scared of this one, as there are quite a few cases. We may or may not have filters or selection defined. It may be the first extraction, where we only have to pass the high watermark, or it may be a subsequent one that requires both timestamps. Finally, after a while, I wrote the following expression that I think addresses all cases.
@concat('$top=',pipeline().parameters.Batch, '&$skip=',string(mul(int(item()), int(pipeline().parameters.Batch))), if(empty(pipeline().parameters.Filter), concat('&$filter=', if(empty(pipeline().parameters.Watermark), '', concat(pipeline().parameters.WatermarkField, ' gt datetimeoffset''', formatDateTime(pipeline().parameters.Watermark, 'yyyy-MM-ddThh:ss:sZ'),'''', ' and ')), pipeline().parameters.WatermarkField, ' le datetimeoffset''', formatDateTime(variables('v_watermark'), 'yyyy-MM-ddThh:ss:sZ'),''''), concat('&$filter=', pipeline().parameters.Filter, if(empty(pipeline().parameters.Watermark), '', concat(' and ', pipeline().parameters.WatermarkField, ' gt datetimeoffset''', formatDateTime(pipeline().parameters.Watermark, 'yyyy-MM-ddThh:ss:sZ'),'''')), ' and ', pipeline().parameters.WatermarkField, ' le datetimeoffset''', formatDateTime(variables('v_watermark'), 'yyyy-MM-ddThh:ss:sZ'),'''')), if(empty(pipeline().parameters.Select), '', concat('&$select=',pipeline().parameters.Select)))

Great! We’re pretty much done!
We just have to update the metadata store with the high watermark value read from the OData service. I will use the Copy Data activity to do it.

The source and sink stores should refer to the same metadata table dataset, which we use to read content from the store. I will use a query to select the entry to edit based on the OData service name and the Entity.
@concat('PartitionKey eq ''', pipeline().parameters.ODataService, ''' and RowKey eq ''', pipeline().parameters.Entity, '''')
Then, in the Additional Columns I define the high watermark value, which we will map to the target column.
@variables('v_watermark')

Set the Insert Type to Merge on the Sink tab. That’s important – if you leave it to Replace, the whole entry in the table will be recreated, which means we’ll lose part of the data. Change the fields Partition Key Value Selection and Row Key Value Selection to PartitionKey and RowKey respectively.

Open the Mapping tab. The goal here is to reference the PartitionKey and RowKey fields to define the record that requires updating and then use the Additional Column HighWatermark to update the destination field Watermark.

That’s it! We can start testing!
EXECUTION AND MONITORING
To verify the pipeline works fine, I will run two tests. In the first one, as the watermark value for all OData services is empty, I’m expecting to see all data landing in the lake. Then I’ll edit a couple of sales orders that should be extracted in the second run. I won’t make any changes to materials.
3.. 2.. 1.. Go!

Green status is always good. Let’s check the number of records extracted.

So that looks good. I use tight filtering on the Business Partner which explains why only a single record was processed. A quick look at the metadata table and I can see that the watermark field was updated correctly:

Now I’m going to edit a couple of sales orders and then I’ll trigger the pipeline. Let’s see how many records we extract.

It worked well. Let’s look at the metadata store table:

The high watermark for the Entity A_SalesOrder was updated with the last change timestamp. So everything works correctly.
As always I hope you enjoyed this episode! I showed you how you can implement the delta extraction for OData services using Synapse Pipelines and metadata store to identify records that require processing. It’s not a perfect solution. We need to have the timestamp information and heavy scripting is required. But it works. In the next episode, I’ll show you how to convince your SAP system to manage the delta for you – which is much better approach!
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments