This article is contributed. See the original author and article here.
In this series on DevOps for Data Science, I explained what DevOps is, and given you lots of resources to go learn more about it. Now we can get to the details of implementing DevOps in your Data Science Projects .
Consider that the standard Software Development Lifecycle (SDLC) with Data Science algorithms or API’s added in looks something like this:
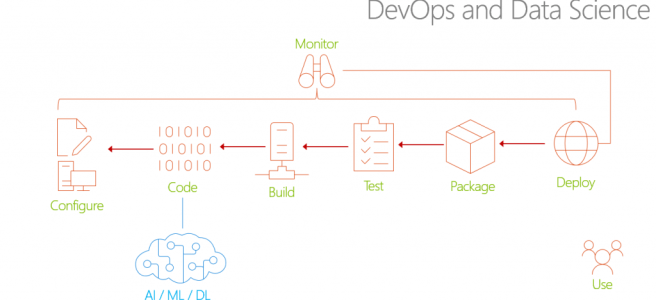
In traditional DevOps, each phase of the SDLC is aware of the “downstream” phases – that’s the People (discussions and meetings), Process (procedures and frameworks), and Products (Tools and software) part of DevOps. Also note that Monitoring is not just monitoring the performance of the end-released applications, it’s also now monitoring the SDLC itself. All of this awareness is the “Shift-Left” mentality, essential to DevOps for Data Science.
But let’s dig into that a bit. The “Configure” phase is easy enough to think about for the Data Science team. They want to be involved in the design of the solution anyway, so that they ensure the right questions are being asked, the right data is available (or can be obtained), and all the rest of the project parameters. And of course the Data Science team is part of the “Code” phase, so that’s just built-in.
But “build”? What does that even mean to the Data Scientist? Testing? How does one build a unit test, functional test, security test, and other tests, into a Data Science algorithm? And how do you use Continuous Integration (CI) and Continuous Delivery (CD) into a Data Science deployment? Packaging, Deployment – these are all things that a Data Scientist doesn’t normally have to consider in their day-to-day work.
Not to worry – we’ll get to all these phases. In fact, many shops still struggle with DevOps, even where there are no Data Science aspects. What I have found that helps the most is not to try and do everything at once. Develop a “Maturity Model” that you can aspire to, and take it one step at a time. Let that settle into your regular SDLC, and then move on.
For Data Science, I find this progression works best – taking these one step at a time, and building on the previous step – the entire series is listed here that I’ll develop in this series – updated links to follow as I write them:
- Infrastructure as Code (IaC)
- Continuous Integration (CI) and Automated Testing
- Continuous Delivery (CD)
- Release Management (RM)
- Application Performance Monitoring
- Load Testing and Auto-Scale
In the articles in this series that follows, I’ll help you implement each of these in turn.
(If you’d like to implement DevOps, Microsoft has a site to assist. You can even get a free offering for Open-Source and other projects: https://azure.microsoft.com/en-us/pricing/details/devops/azure-devops-services/ )
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments