This article is contributed. See the original author and article here.
Overview
In the world of Artificial Intelligence and Machine Learning, data quality is paramount in ensuring our models and algorithms perform correctly. By leveraging the power of Spark on Azure Synapse, we can perform detailed data validation at a tremendous scale for your data science workloads.
What is Azure Synapse?
Azure Synapse is a Data Analytics Service that provides tools for end-to-end processing of data within Azure. The Azure Synapse Studio provides an interface for developing and deploying data extraction, transformation, and loading workflows within your environment. All of these workflows are built on scalable cloud infrastructure and can handle tremendous amounts of data if needed. For data validation within Azure Synapse, we will be using Apache Spark as the processing engine. Apache Spark is an industry-standard tool that has been integrated into Azure Synapse in the form of a SparkPool, this is an on-demand Spark engine that can be used to perform complex processes of your data.
Pre-requisites
Without getting into too much detail, the main requirements you will need for running this code is an Azure Synapse Workspace and a data set on which you would like to perform some validations loaded to Azure Storage. The technique shown here provides a starting point for performing these types of data validations within your own use case.
For demonstration purposes, I have loaded a data set of hard drive sensor data (link below) to an Azure Storage account and linked the storage account in Synapse (https://docs.microsoft.com/en-us/azure/synapse-analytics/get-started)

I have also set up a SparkPool (link) for developing in PySpark Notebooks within Azure Synapse, I can read the data by connecting to the data source and using some simple PySpark commands:
from pyspark.sql.functions import input_file_name
import os
df = spark.read.load('abfss://[container]@[storage_account].dfs.core.windows.net/[path]/*.csv', format='csv', header=True).withColumn('file', input_file_name())
display(df)

One key part to take note of is the command .withColumn(‘file’, input_file_name()), this adds a column to your dataset named file with the name of the source data file. Very helpful when trying to find malformed rows.
Let’s start validating
After loading the data you can begin by calculating some high-level statistics for simple validations.
df_desc = df.describe()
display(df_desc)

the describe() function calculates simple statistics (mean, standard deviation, min, max) that can be compared across data sets to make sure values are in the expected range. This is a built-in data function that can be used on any data. You can save these data sets back to your data lake for downstream processes using:
df_desc.write.parquet("[path][file].parquet")
But we can get much more complex by using spark queries to further validate the data.
We can count how many rows were contained in each file using this code:
validation_count_by_date = df.groupBy('file','date').count()

This count can be useful in ensuring each file contains a complete dataset. If file sizes are outside of the expected range, it may mean that the file is either incomplete or contains excess data.
Furthermore, we can even look at the specific values within the data at a row-level granularity. The code below uses the named columns “file” and “date” to the group missing values across all files in your data set. Missing values are defined as Null or NaN values in the dataset.
from pyspark.sql.functions import isnull, isnan, when, count, col
cols = [count(when(isnan(c) | col(c).isNull(), c)).alias(c) if c not in ['file', 'date'] else count(col(c)).alias('count_{}'.format(c)) for c in df.columns]
missing_by_file = df.groupBy('file', 'date').agg(*cols)
display(missing_by_file)

Don’t be intimidated by the above code. I am essentially using some python loops to generate a list of columns cols, and then using the * (star) operator to pass those columns to the select function. I encourage you to try running these commands on your data to become familiar with the power of python.
We can go a step further in calculating the ratio of missing values for each column within a file:
missing_by_file_pct = missing_by_file.select(['date', 'file', *[(col(c)/col('count_file')).alias('{}_pct'.format(c)) for c in df.columns]])
display(missing_by_file_pct)

Now instead of looking at total values, we can identify incomplete data by looking at the percentage of filled-in values in a file. Again, this technique accompanied by business rules can be very powerful in validating raw data sources and ensuring data quality in a scalable method.
Up until this point, I have only defined the column names of “file” and “date”, all other columns have been derived from the source file header/schema so there is no need to maintain column lists as part of the validation rules. If you do require checking for specific values within a file, you can easily extend these examples such as this:
from pyspark.sql.functions import countDistinct
validation_modelcount_by_date = df.groupBy('file','date').agg(countDistinct('model'))
display(validation_modelcount_by_date)

The query above identifies all the distinct values for the column “model” which are present in each file. As you can see the count of distinct models varies slightly from file to file, we can establish an acceptable range fairly easily by looking at this data.
How can I use this in my processes?
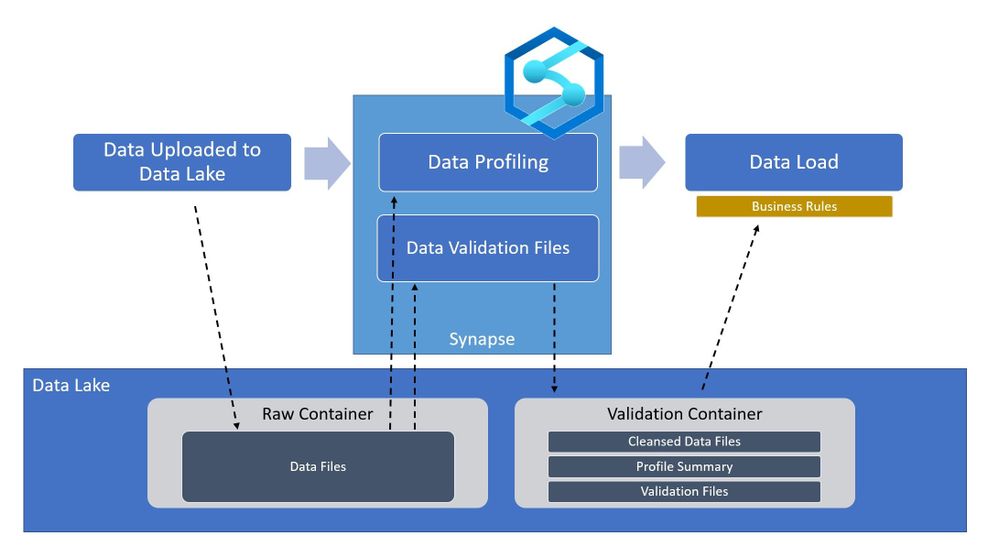
Going back to the high-level architecture diagram shown at the beginning of the blog. This technique can be applied during the ingestion of your data to certify whether the raw files are qualified to be in the data lake. By using Synapse Spark we can perform the row-level checks fast and efficiently, and output the results back into the data lake. Downstream processes such as Machine Learning Models and/or Business Applications can then read the validation data to determine whether or not to use the raw data without having to re-validate it. With Azure Synapse and Spark, you can perform powerful validations on very large data sources with minimal coding effort.
Data reference: Backblaze Hard Drive Stats
Github Link: AzureSynapseDataValidation/Validation-Sample.ipynb
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments