This article is contributed. See the original author and article here.
Data Protection for SAP Solutions
Introduction
Data protection is key criteria for all customers. You need to find an optimal way to protect against data loss or data inconsistencies caused by hardware or software defects, accidentally deletion of data, external and internal data fraud.
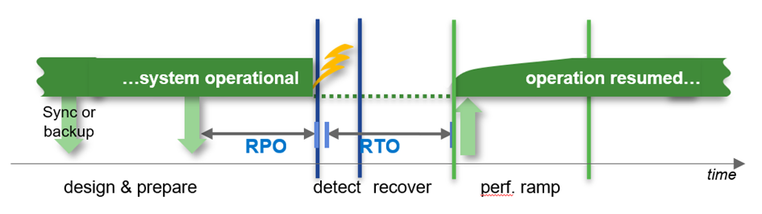
Other important criteria are the architecture around high availability and disaster recovery to fulfill the requirements around RPO in a typical HA case (usually RPO=0) or in a disaster recovery case (usually RPO!=0).
How soon is the system required to be back in “normal” operations after an HA or DR situation.
Recovery times can be in a wide range depending on the ways to recover the data. E.g. the times can be short if you could use Snapshots or a clone from a Snapshot or it could take hours to bring back the data to the file system (Streaming backup/recovery) before we even can start the database recovery process.
The main question is “what is your requirement?”
What is nice to have and what is really required in cases of high availability and disaster recovery?
Backup Runtime with different HANA Database Sizes
Database size on file system
Backup throughput: 250MB/s

For very large databases the backup process will take many hours if you are using streaming based backup. With snapshot based backups it could take only a minute, regardless of the size of the database. Remember, a Snapshot, at least with Azure NetApp Files, remains in the same volume where your data is. Therefore, consider offloading (at least) one Snapshot a day using e.g. ANF backup to a ANF backup Vault.
SAP HANA on Azure NetApp Files – Data protection with BlueXP backup and recovery (microsoft.com)
Restore and recovery times of a 4TB HANA database

- Database size: 4TB on file system
- Restore throughput: 250MB/s
- Log backups: 50% of db size per day
- Read troughput during db start: 1000MB/s
- Throughput during recovery: 250MB/s
Conclusion:
For smaller databases it can be absolutely sufficient to use streaming backups to fulfil your requirements. For larger or very large databases getting to low RTO times with streaming backups can be difficult. Since it can take hours to restore the data to the original location. This could enlarge the RTO significantly. Although, specifically for the high availability case, we would recommend using HSR (HANA System Replication) to reach an acceptable RTO. But even than the failing system may need to be rebuild or recovered which might take many hours. To reduce the time for a complete system rebuild, customers are using Snapshot based backup/restore scenarios to lower the RTO significantly.
Azure Backup (Streaming Backup)
Azure Backup delivers these key benefits:
- Offload on-premises backup – Azure Backup offers a simple solution for backing up your on-premises resources to the cloud. Get short and long-term backup without the need to deploy complex on-premises backup solutions.
- Back up Azure IaaS VMs – Azure Backup provides independent and isolated backups to guard against accidental destruction of original data. Backups are stored in a Recovery Services vault with built-in management of recovery points. Configuration and scalability are simple, backups are optimized, and you can easily restore as needed.
- Scale easily – Azure Backup uses the underlying power and unlimited scale of the Azure cloud to deliver high-availability with no maintenance or monitoring overhead.
- Get unlimited data transfer – Azure Backup doesn’t limit the amount of inbound or outbound data you transfer, or charge for the data that’s transferred. Outbound data refers to data transferred from a Recovery Services vault during a restore operation. If you perform an offline initial backup using the Azure Import/Export service to import large amounts of data, there’s a cost associated with inbound data. Learn more.
- Keep data secure – Azure Backup provides solutions for securing data in transit and at rest.
- Centralized monitoring and management – Azure Backup provides built-in monitoring and alerting capabilities in a Recovery Services vault. These capabilities are available without any additional management infrastructure. You can also increase the scale of your monitoring and reporting by using Azure Monitor.
- Get app-consistent backups – An application-consistent backup means a recovery point has all required data to restore the backup copy. Azure Backup provides application-consistent backups, which ensure additional fixes aren’t required to restore the data. Restoring application-consistent data reduces the restoration time, allowing you to quickly return to a running state.
- Retain short and long-term data – You can use Recovery Services vaults for short-term and long-term data retention.
- Automatic storage management – Hybrid environments often require heterogeneous storage – some on-premises and some in the cloud. With Azure Backup, there’s no cost for using on-premises storage devices. Azure Backup automatically allocates and manages backup storage, and it uses a pay-as-you-use model. So, you only pay for the storage you consume. Learn more about pricing.
- Multiple storage options – Azure Backup offers three types of replication to keep your storage/data highly available.
- Locally redundant storage (LRS) replicates your data three times (it creates three copies of your data) in a storage scale unit in a datacenter. All copies of the data exist within the same region. LRS is a low-cost option for protecting your data from local hardware failures.
- Geo-redundant storage (GRS) is the default and recommended replication option. GRS replicates your data to a secondary region (hundreds of miles away from the primary location of the source data). GRS costs more than LRS, but GRS provides a higher level of durability for your data, even if there’s a regional outage.
- Zone-redundant storage (ZRS) replicates your data in availability zones, guaranteeing data residency and resiliency in the same region. ZRS has no downtime. So your critical workloads that require data residency, and must have no downtime, can be backed up in ZRS.
What is Azure Backup? – Azure Backup | Microsoft Learn
SAP HANA Backup support matrix – Azure Backup | Microsoft Learn
ANF how does a SnapShot work
How Azure NetApp Files snapshots work | Microsoft Learn
What volume snapshots are
An Azure NetApp Files snapshot is a point-in-time file system (volume) image. It is ideal to serve as an online backup. You can use a snapshot to create a new volume (clone), restore a file, or revert a volume. In specific application data stored on Azure NetApp Files volumes, extra steps might be required to ensure application consistency.
Low-overhead snapshots are made possible by the unique features of the underlying volume virtualization technology that is part of Azure NetApp Files. Like a database, this layer uses pointers to the actual data blocks on disk. But, unlike a database, it doesn’t rewrite existing blocks; it writes updated data to new blocks and changes the pointers, thus maintaining the new and the old data. An Azure NetApp Files snapshot simply manipulates block pointers, creating a “frozen”, read-only view of a volume that lets applications access older versions of files and directory hierarchies without special programming. Actual data blocks aren’t copied. As such, snapshots are efficient in the time needed to create them; they are near-instantaneous, regardless of volume size. Snapshots are also efficient in storage space; only delta blocks between snapshots and the active volume are kept.
Files consist of metadata and data blocks written to a volume. In this illustration, there are three files, each consisting of three blocks: file 1, file 2, and file 3.

A snapshot Snapshot1 is taken, which copies the metadata and only the pointers to the blocks that represent the files:

Files on the volume continue to change, and new files are added. Modified data blocks are written as new data blocks on the volume. The blocks that were previously captured in Snapshot1 remain unchanged:

A new snapshot Snapshot2 is taken to capture the changes and additions:

ANF Backup (SnapShot – SnapVault based)
Azure NetApp Files backup expands the data protection capabilities of Azure NetApp Files by providing fully managed backup solution for long-term recovery, archive, and compliance. Backups created by the service are stored in Azure storage, independent of volume snapshots that are available for near-term recovery or cloning. Backups taken by the service can be restored to new Azure NetApp Files volumes within the same Azure region. Azure NetApp Files backup supports both policy-based (scheduled) backups and manual (on-demand) backups. For additional information, see https://learn.microsoft.com/en-us/azure/azure-netapp-files/snapshots-introduction
To start with please read: Understand Azure NetApp Files backup | Microsoft Learn
ANF Resource limits: Resource limits for Azure NetApp Files | Microsoft Learn
Design
The four big benefits of ANF backup are:
- Inline compression when taking a backup.
- De-Duplication – this will reduce the amount of storage needed in the Blob space. Be aware that using Transparent Data Encryption functionality as offered by the different DBMS are prohibiting efficiency gains by De-Duplication
- Block level Delta copy of the blocks – this will the time and the space for each backup
- The database server is not impacted when taking the backup. All traffic will go directly from the storage to the blob space using the Microsoft backbone and NOT the client network. The backup will also NOT impact the storage volume quota. The database server will have the full bandwidth available for normal operation.

How this is all working
We are going to split the backup features in two parts. The data volume will be snapshotted with azacsnap. Creating this snapshot, it is important that the data volume is in a consistent state before the snapshot is triggered. Creating the application consistency is managed with azacsnap in the case of e.g. SAP HANA Oracle (with Oracle Linux), and Db2 (Linux only).
The SAP HANA log backup area is a “offline” volume and can be backed up anytime without talking to the database. We also need a much higher backup frequency to reduce the RPO as for the data volume. The database can be “rolled forward” with any data snapshot if you have all the logs created after this data volume snapshot. Therefore, the frequency of how often we backup the log backup folder is very important to reduce the RPO. For the log backup volume we do not need a snapshot at all because, as I mentioned, all the files there are offline files.

This displays the “one AV Zone scenario”. It will also be possible to use ANF backup in a peered region (DR) but then the restore process will be different (later in this document)
ANF Backup using an DR Region
It is also an option to leverage ANF backup from a DR Azure region. In this scenario the backups will be created from the ANF DR volumes. In our example, we are using both. CRR (Cross Region Replication) in a region ANF can replicate to and ANF backup to store the backups for many days, weeks or even months.
For a recovery you will primarily use the snapshots in the production ANF volume. If you have lost the primary zone or ANF you might have an HA system before you even recover the DB. If you don’t have an HA system, you still have a copy of the data in your DR region. In the DR region, you simply could activate the volumes or create a clone out of the volumes. Both are very fast methods to get your data back. You would need to recover the database using the clone or the DR volume. In most cases you will lose some data because in the DR region usually is a gap of available log backups.

ANF Volume Lock
One other data protection method is to lock the ANF volume from deletion.
When you create a lock you will protect the ANF volume from accidently deletion.

If you or someone else tries to delete the ANF volume, or the resource group the ANF volume belongs to, Azure will return an error.

Result in:

However, there is a limitation to consider. If you set a lock on an ANF volume that vlocks deletion of the volume, you also can’t delete any snapshots created of this volume. This presents a limitation when you work with consistent backups using AzAcSnap. AzAcSnap. As those are not going to be able to delete any snapshots of a volume where the lock is configured. The consequence is that the retention management of azacsnap or BlueXP is not able to delete the snapshots that are out of the retention period anymore.
But for a time where you start with your SAP deployment in Azure this might is a workable way to protect your volumes for accidently deletion.
Repair system
There are many reasons why you might find yourself in a situation to repair a HANA database to s specific point in time. the most common are:
- Accidental deletion of data within a table or deletion of a complete table during administration or operations causing a logical inconsistency in the database.
- Issues in hardware of software stack causing corruption of page/block content in the database.
In both of these it might take hours, days or even weeks until the impacted data is accessed the next time. The more time passes between the introduction of such an inconsistency and the repair, the more difficult is the root cause analysis and correction. Especially in cases of logical inconsistencies, an HA system will not help since the logical inconsistency cause by a ‘delete command’ got “transferred” to the database of the HA system through HANA System Replication as well.
The most common method of solving these logical inconsistency problems is to “quickly” build an, so called, repair system to extract deleted and now “missing” data.
To detect physical inconsistencies, executing regular consistency checks are highly recommended to detect problems as early as possible.
For SAP HANA, the following main consistency checks exist:
CHECK_CATALOG | Metadata | Procedure to check SAP HANA metadata for consistency |
CHECK_TABLE_CONSISTENCY | Column store | Procedure to check tables in column store and row store for consistency |
Backup | Persistence | During (non-snapshot) backups the physical page structure (e.g. checksum) is checked |
hdbpersdiag | Persistence | Starting with SAP HANA 2.0 SPS 05 the hdbpersdiag tool is officially supported to check the consistency of the persistence level. see Persistence Consistency Check for more information. |
2116157 – FAQ: SAP HANA Consistency Checks and Corruptions – SAP for Me
SAP Note 1977584 provides details about these consistency check tools. See also for related information in the SAP HANA Administration Guide.
To create an “repair System” we can select an older snapshot, which was created with e.g. azacsnap, and recover the database where we assume the deleted table was still available. Then export the table and import the table into the original PRD database. Of course,
we recommend that SAP support personnel guides you through this recovery process and potential additional repairs in the database.
The process of creating a ‘repair system’ can look as the following graphic:

Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments