
by Scott Muniz | Sep 4, 2020 | Uncategorized
This article is contributed. See the original author and article here.
PowerShell provides an effective way to run queries or actions at scale, whether that’s against Azure resources, Azure Active Directory identities or Office 365 environments (including Exchange Online, SharePoint Online and Microsoft Teams). The first step is connecting PowerShell to your tenant and subscription with valid credentials, using the “Connect-AzAccount” command. So what happens if you hit an error with that very first step?
The warning sign
In PowerShell, I ran the “Connect-AzAccount” command, visited the website and entered the provided (redacted) code. The login process seemed to then authorize my username and password without error, but there was something strange in what was returned (see if you can spot it, below):

This was a slightly tricky question, as you may not be able to tell that I haven’t blacked out the SubscriptionName or TenantID for security reasons. They appeared blank.
This account has access to multiple subscriptions in a single tenant, so before we start issuing commands, we need to set the context. Usually one is picked up by default but you can use the same process to switch to a different subscription or tenant if needed. In this case, with none selected, I issued the next command “Set-AzContext” and provided the -SubscriptionID that I wanted the commands to act against, only ….

Denied!
Troubleshooting
On hitting this error I did what most seasoned IT Professionals would do – I searched the internet for the phrase “failed to acquire token silently as no token was found in the cache the refresh token had expired due to inactivity”.
No matter what permutation I used of these search terms, the limited results I did find were related to API calls or application errors. Not at all helpful in this context (see what I did there?).
What was helpful was this Doc regarding Azure PowerShell context objects. It didn’t specifically list the above error, but it did give me the PowerShell credentials equivalent of “turn it off and back on again” – the “Clear-AzContext” command!

After running Clear-AzContext, I was able to re-run Connect-AzAccount and pick up a default context successfully, then run my commands.
Conclusion
What caused this error to fire? I have no idea. It’s one of those scenarios where the cost benefit analysis doesn’t really stack up to investigate it further. It was likely a one-off incident on my particular PC and I could invest a ton of time in trying to reproduce it or troubleshoot it – or I could accept that I found a quick and easy fix. If it does re-occur or if we get an outpouring of comments that it happens to other people all the time too, then it might be worth looking into further.
But for now, I’ll take the win that clearing the cache was enough to pull down a new, valid authentication token. And it is worth the time to blog about it, for the next seasoned IT Professional that encounters the same thing.
Yours in troubleshooting,
SCuffy.
by Scott Muniz | Sep 4, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
An accurate infrastructure diagram is invaluable to your IT team. It can be used by cloud architects to redesign the existing cloud infrastructure, DevOps engineers responsible for implementing that design, or project managers to ensure the rollout has been executed according to the scope.
We introduced Azure shapes in Visio about two years ago. Today, we are excited to announce more than 250 of the latest Azure shapes are available in Visio for the web. These refreshed icons are better aligned with the Microsoft Fluent design and let you create IT diagrams that accurately represent modern cloud services, tools, and frameworks from Azure.
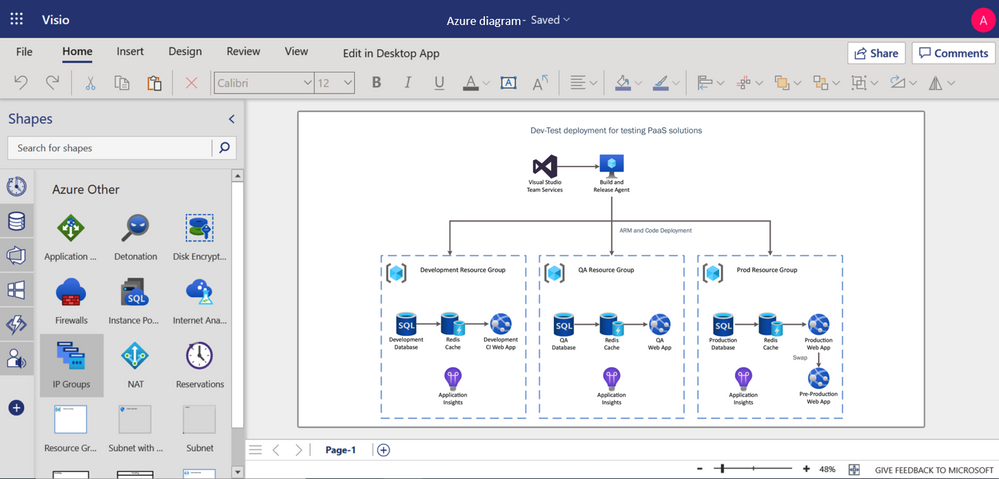
You can use Visio for the web to build Azure diagrams for network topologies, virtual machine configurations, operations, and more. These provide a means of clearly documenting the existing infrastructure for clarity and help visualize various service interactions. For example, you can build a diagram showing how to configure infrastructure for development and testing of a standard PaaS-style system that leverages Azure DevOps, Azure SQL Database, Azure Cache Redis and Application insights service. By sharing diagrams like this among your team, everyone is on the same page for executing concepts. Detailed Azure diagrams can also serve as roadmaps for scaling and managing your Azure network as it grows with your business.

Azure diagram representing Dev-test deployment for PaaS solutions
There are 18 shape sets in all, including Azure AI and Machine Learning, Azure App Services, Azure Compute, Azure Containers, Azure Databases, Azure General, Azure IoT, Azure Identity, Azure Integration, Azure Management & Governance, Azure Analytics, Azure Migrate, Azure Networking, Azure Security, Azure Storage, Azure Other, and Microsoft Product Icons.

To help you get started easily, we have provided a few starter diagrams using various Azure services. Visit visio.office.com, select the preferred diagram template, and start visualizing your Azure infrastructure. Our support page provides even more details on how to create your Azure diagrams.

For questions or feedback regarding Visio Azure templates and other features, please email us at tellvisio@microsoft.com. Keep visiting the Visio Tech Community, and follow us on Facebook and Twitter to stay current on the latest Visio releases.
by Scott Muniz | Sep 4, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
Recently Microsoft announced general availability of Azure Shared Disks.
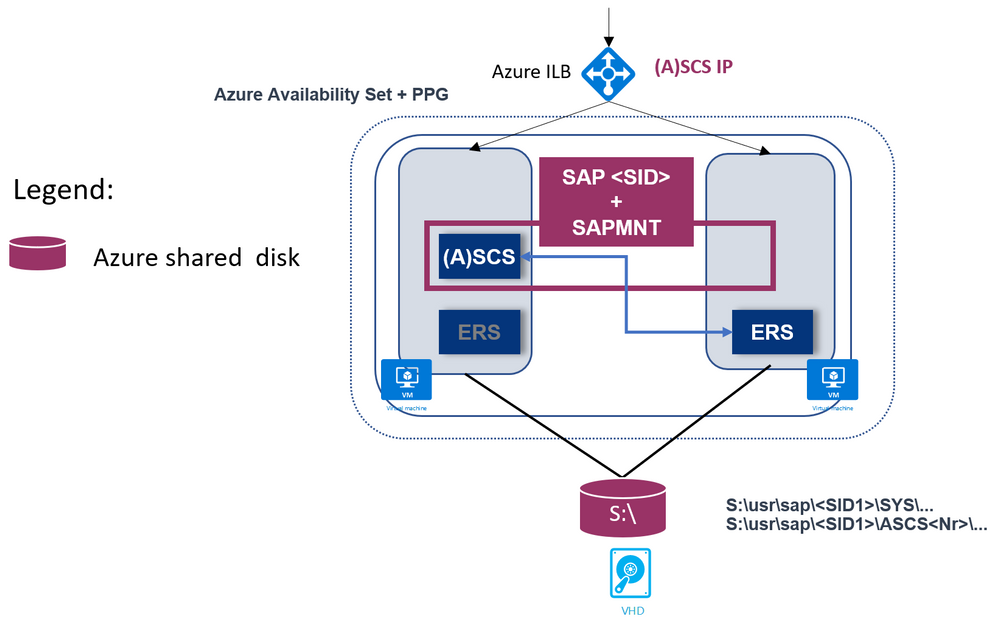
We are happy to announce Azure Shared Disks support for SAP central services (ASCS/SCS) instance on Windows Failover Cluster!
Azure shared disks enable an Azure disk to be attached to multiple VMs in a cluster and supports the SCSI Persistent Reservations (PR) industry standard.
Shared Disk is a well-known option for running highly available SAP ACS/ASCS instances on WSFC. This is commonly used on-premises in both physical and virtual environments.
Features of the solution are:
- Simplicity
It is very simple solution: so overall complexity is reduced.
- Cost effective
You only need two VMs as Windows cluster nodes.
This will reduce Azure costs, and overall maintenance.
In a file share approach with SOFS (Scale Out File share) + S2D (Storage Space Direct), you need additional two or three VMs for SOFS, and multiple disks for S2D.
- Supported Windows releases
It is supported with Windows Failover Clustering on Windows Server 2016 & 2019 Datacenter OS versions.
- Windows release recommendation
It is recommended to use Windows Server 2019 Datacenter due to a number of key enhancements in WSFC on WS 2019, including:
- Windows 2019 Failover Cluster is Azure aware.
- There is added integration and awareness of Azure Host Maintenance, and improved experience by monitoring for schedule events.
- For the cluster virtual IP address, it is possible to use (default option) Distributed network name, where cluster network name (virtual hostname) use any cluster node local IP address. This is the same approach that Windows Scale Out File Server is using.
In this way there is no need to have a dedicated IP address for cluster network name, and there is no need to configure this IP address on the Azure Internal Load Balancer.
Therefore, overall management is easier.
- SAP Enqueue Replication version 1 (ERS1)

- SAP Enqueue Replication version 2 (ERS2) is also supported, as shown:

Here, SAP ERS instance is also clustered.
-
SAP Multi-SID is supported as well.
Each SAP SID has its own shared disks.
Here is an example with two SAP SIDs and ERS1:

Another example with two SAP SIDs and ERS2:

- Supported with heterogeneous Linux clustering
You can use this solution for achieving high availability of the SAP ASCS/SCS even when using SAP HANA or any DB as the database layer, even if the database layer is running on Linux.
This is discussed in blog SAP on Azure High Availability Systems with Heterogenous Windows and Linux Clustering and SAP HANA
Please refer to official documentation for list of limitations.
Important: When deploying SAP ASCS/SCS Windows Failover cluster with Azure shared disk, be aware that your deployment will be operating with a single shared disk in one storage cluster. Your SAP ASCS/SCS instance would be impacted, in case of issues with the storage cluster, where the Azure shared disk is deployed.
You can find further information here:
The documentation above covers a manual procedure to deploy and prepare the infrastructure for the SAP ASCS/SCS using Azure Shared Disks.
With this Azure ARM Template , you can automate the infrastructure preparation for a single SAP SID with ERS1. The Azure ARM template will create two Windows Server 2019 or 2016 VMs, the Windows OS will be added to an existing Windows Active Directory domain, a shared disk will be created, attached to the VMs, and formatted with a drive letter; Azure Availability Set and Proximity Placement Group will be created and VMs will be added; Azure Internal Load Balancer will be created and configured; Azure cloud witness as a majority maker is created and configured etc.
by Scott Muniz | Sep 4, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Many of you rely on databases to return correct results for your SQL queries, however complex your queries might be. And you probably place your trust with no questions asked—since you know relational databases are built on top of proven mathematical foundations, and since there is no practical way to manually verify your SQL query output anyway.
Since it is possible that a database’s implementation of the SQL logic could have a few errors, database developers apply extensive testing methods to avoid such flaws. For instance, the Citus open source repo on GitHub has more than twice as many lines related to automated testing than lines of database code. However, checking correctness for all possible SQL queries is challenging because of the lack of a “ground truth” to compare their outputs against, and the infinite number of possible SQL queries.
Even when we do know the result a SQL query is supposed to give and we get that result as expected, that does not mean the implementation is 100% correct in all possible variants of the query and input data. The challenge for a database team is in finding subtle edge cases where bugs might be introduced.
What are logic bugs in SQL, and why are they hard to detect?
There are 2 primary types of errors in databases:
- “raised” errors
- logic errors
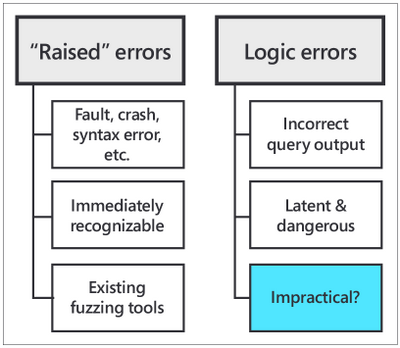
“Raised” errors include syntax errors, panics, faults, and other crashes. Raised errors terminate the process abnormally or give you some signal of undesired behavior, making them immediately recognizable to you. In order to automatically detect (and then fix) raised errors, database providers widely use fuzzing tools for SQL. Fuzzing tools are random SQL query generators that strain the target database with complex commands until an error is raised.
Logic errors, on the other hand, are latent (or silent) errors that cause the database to produce inaccurate results without emitting any sign of unexpected behavior. Logic bugs are dangerous—neither the user, nor the database provider, nor the fuzzing tools might be aware of incorrect results being fetched from the database.
 Fig. 1: “Raised” errors vs. logic errors
Fig. 1: “Raised” errors vs. logic errors
What if we could find a way to test the validity of SQL query output for a DBMS?
The recently launched open source SQLancer (Synthesized Query Lancer) tool gives you a way to test the validity of a database’s query responses. SQLancer is an automated Database Management System (DBMS) testing tool for detecting logic bugs. SQLancer’s testing approaches substitute the need for a ground truth in their correctness checks, by probing databases for self-consistency rather than agreement with some known behavior.
While SQLancer is still in the research prototype stage, it was released early on due to high demand from different companies, organizations, and developers. I first learned about SQLancer in June 2020 through a Quarantine 2020 Database Talk organized by Carnegie Mellon Professor of Databases Andy Pavlo.
The CMU talk by SQLancer creator Manuel Rigger was about Finding Logic Bugs in Database Management Systems. At the time of Manuel Rigger’s talk, SQLancer had already identified more than 175 bugs in 5 different SQL database management systems by using Ternary Logic Partitioning (TLP). Hence, Ternary Logic Partitioning became the SQLancer testing approach that was of most interest to our team at Citus.
If you are not familiar, Citus is an open source extension to Postgres that transforms Postgres into a distributed database. Since the Citus team was acquired by Microsoft last year, Citus is now available on Microsoft Azure as Hyperscale (Citus), a built-in deployment option on Azure Database for PostgreSQL.
During my software engineering internship the summer after my second year as an undergraduate at Stanford, I worked on the Citus open source team at Microsoft. My project was about incorporating correctness checks into our automated testing mechanisms, which led me to the CMU database talk on SQLancer. Keep reading to find out what excited us about SQLancer, how I developed an implementation of SQLancer that supports the Citus extension to Postgres, and the rewarding outcomes of my project.
SQLancer’s performance on Citus (& Postgres)
SQLancer proved itself useful for detecting logic bugs in Citus early on in my project, with the first error found within seconds of our initial SQLancer run after I had just finished implementing basic Citus support. And I found the first SQL logic bug within the first week.
By the end of my summer internship on the Postgres team at Microsoft, we had opened more than 10 issues in the Citus GitHub page for errors found by SQLancer, at least 3 of which qualify as SQL logic bugs. Moreover, I was also able to identify an error in PostgreSQL, which was then fixed by David Rowley and referenced by Thomas Munro—both of whom are PostgreSQL committers and part of the Postgres team at Microsoft.
 https://twitter.com/MengTangmu/status/1282909653530103813
https://twitter.com/MengTangmu/status/1282909653530103813
With the Citus implementation of SQLancer, we were able to test more than 3 million SQL queries in 3 days. While logic bugs in SQL databases are rare, the speed of the SQLancer tool and its broad, complex test space allowed us to detect logic errors that exist in the DBMS implementation (or that might be introduced in the future with the addition of new features). Whether part of Continuous Integration (CI) tests or part of regular lengthy background runs, incorporating SQLancer into the automated testing procedures for the Citus extension to PostgreSQL will significantly improve the reliability and stability of Citus for our users.
A technical overview of SQLancer’s testing approach: Ternary Logic Partitioning (TLP)
Among three of the test oracles adopted by SQLancer, my project focused on the Ternary Logic Partitioning (TLP) approach, which can be used to test WHERE, GROUP BY, HAVING clauses, aggregate functions, and DISTINCT queries. TLP compares the result sets of two semantically equivalent yet syntactically different SELECT queries that are expected to be equal.
Let’s make an apples analogy: Say, you want to ‘fetch all apples’. You could also say that you want to ‘fetch all apples that are red,’ ‘fetch all apples that are not red,’ or ‘fetch all apples where the color is unknown.’ Both versions would be equivalent—the second one is only a more verbose way of saying the same thing by adding conditions related to “redness” and combining them in a way that makes the condition trivial.
 Fig 2. Ternary partitioning of a predicate, hand-drawn by Nazli Ugur Koyluoglu, inspired by TLP paper by Rigger & Su (https://www.manuelrigger.at/preprints/TLP.pdf)
Fig 2. Ternary partitioning of a predicate, hand-drawn by Nazli Ugur Koyluoglu, inspired by TLP paper by Rigger & Su (https://www.manuelrigger.at/preprints/TLP.pdf)
For those of you who want to see the mathematical explanation for how TLP works, rather than rely on my apple analogy, here it goes:
Let Q be the original query. The semantically equivalent query Q’ would be a UNION of 3 queries that partition Q using ternary logic. These 3 queries are generated by randomly generating a boolean predicate ϕ, and appending a version of ϕ evaluated to TRUE, FALSE, and NULL to the end of Q, each in the form of a WHERE or HAVING clause. Since these 3 boolean values cover the universal set of states associated with the predicate, their union, Q’, must return the same result set as that returned by the query without the predicate, Q, i.e. ResultSet(Q) = ResultSet(Q’).
 Fig 3. Implementation steps for Ternary Logic Partitioning, inspired by Manuel Rigger’s SQLancer talk at the CMU Quarantine 2020 Database talks: https://youtu.be/_LLHssTadKA
Fig 3. Implementation steps for Ternary Logic Partitioning, inspired by Manuel Rigger’s SQLancer talk at the CMU Quarantine 2020 Database talks: https://youtu.be/_LLHssTadKA
The steps for implementing the test oracle are as follows:
- Randomly generate the original query Q, in a similar fashion to random queries generated by fuzzers. To continue our apple analogy, Q would be ‘fetch all apples.’
- Randomly generate the boolean predicate ϕ. ϕ corresponds to the condition in our analogy, ‘to be red.’
- Create the semantically equivalent query Q’ using the Ternary Logic Partitioning (TLP) approach. In our analogy, Q’ corresponds to the verbose version of the command, to ‘fetch apples that are red,’ ‘that are not red,’ or ‘where the color is unknown.’
- Fetch and compare result sets for Q and Q’.
- Report a logic bug if there is a mismatch.
Ternary Logic Partitioning in SQLancer allows us to test a database like Postgres or Citus against itself, first by generating a (relatively) simple and a more complex version of a SQL query, and then by checking whether the added complexity introduces a logic bug. In other words, SQLancer’s TLP test oracle eliminates the need for a ground truth by designating the simpler SQL query as a heuristic for the expected output of the more complex query.
While there’s no guarantee that we can detect all logic bugs in a database like Postgres or Citus using query partitioning, SQLancer’s TLP has proven to be successful with the Citus extension to Postgres and with other databases as well.
Why care about the logic bugs SQLancer finds?
You might think, if SQLancer is testing super complex SQL queries that developers wouldn’t usually come up with (let alone users), why are these SQL queries important? Good question.
Well, while the logic errors are revealed by complex machine-generated SQL queries, it’s possible that the logic bugs themselves might lie in integral operations that affect behavior generally. For the Citus extension to Postgres in particular, the source of logic bugs has mostly been the parsing and deparsing of SQL queries during pushdown to the Citus worker nodes.
Another use case that highlights the usefulness of SQLancer: many of you probably use object-relational mappers (ORMs) to generate SQL queries rather than manually writing them, which makes it more likely that your computer-generated queries might wander into the error-prone zone tested by SQLancer.
Logic bug detection in Citus, at a glance
Running SQLancer to find logic bugs in your SQL involves 2 different phases of execution:
- The preparation phase. SQLancer initializes the test database with Citus support, creates local, distributed, and reference tables inside the database, and performs insertions, updates, deletes, and other modifications to the tables via the randomly generated SQL commands.
- The testing phase. SQLancer generates, executes, and compares the outputs of pairs of original and partitioned SELECT queries, in line with the TLP approach—until it finds a mismatch, i.e. logic bug.
 Fig. 4: A sample pair of original and partitioned queries generated by the Citus implementation of SQLancer.
Fig. 4: A sample pair of original and partitioned queries generated by the Citus implementation of SQLancer.
In Figure 4 above, you can see the original SQL query and the partitioned query—a union of the 3 components with the predicates evaluated to TRUE, FALSE, and NULL, respectively—that failed to return identical result sets. As it turned out, Citus had a bug in its handling of explicit CROSS JOIN syntax when used in a complex join tree. Since cross joins are more commonly used in the implicit form (FROM t1, t4), this type of join tree had not come up in manual testing.
How I implemented SQLancer for the Citus extension to Postgres
I created the Citus implementation of SQLancer by reusing and extending components of the existing SQLancer support for PostgreSQL.
Programming a SQLancer implementation for Citus involved incorporating sharding across multiple nodes in the creation of test databases by SQLancer, expanding the test space by integrating Citus concepts and features such as distributed and reference tables, colocation, distribution key etc. into the database preparation phase, configuring the different types of JOINs supported by Citus in the SELECT statements generated during the testing phase, and adjusting the expected behavior to reflect Citus’ SQL coverage.
 https://twitter.com/AzureDBPostgres/status/1293663559801438208
https://twitter.com/AzureDBPostgres/status/1293663559801438208
A potential positive side effect of my project to the Postgres community: Building Citus support into SQLancer on top of the existing Postgres support required reworking the Postgres support to prepare its Java classes to be extended by new implementations. The improvements and modifications I contributed to the Postgres implementation of SQLancer have thus paved the way for future SQLancer applications for other PostgreSQL extensions, as well.
Special Thanks
I had an incredible experience working on the Citus extension to Postgres during my summer internship in the Postgres team at Microsoft. I had the chance to join the Citus open source project and work with some pretty amazing people. I would like to thank my mentor, Nils Dijk, for his commitment to my growth, especially in a remote setting with limitations imposed by COVID-19. I would like to thank my manager, Utku Azman, for his constant encouragement to take initiative.
Thank you to Onder Kalaci and Marco Slot, whose contributions to the vision for our implementation of SQLancer helped tailor my project to make my work even more useful for the Citus team. And I want to thank the Citus team as a whole for welcoming me with their unsparing help.
Special thanks to Manuel Rigger, the creator of SQLancer, for sharing our excitement about the development of a SQLancer implementation for Citus and his willingness to collaborate.
 https://twitter.com/sqlancer_dbms/status/1293277358783434752
https://twitter.com/sqlancer_dbms/status/1293277358783434752
 https://twitter.com/sqlancer_dbms/status/1293178256108081152
https://twitter.com/sqlancer_dbms/status/1293178256108081152
by Scott Muniz | Sep 4, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
One of the biggest challenges businesses face is how to integrate disparate data sources from many different sources, and how to turn valuable data into actionable insights. Big Data Clusters (BDC) is on the right choice for Big Data Analytics solutions.
As a cloud-native, platform-agnostic, open data platform for analytics at any scale orchestrated by Kubernetes, BDC works on Azure Kubernetes Service ( AKS ) – a fully managed Kubernetes service in Microsoft Azure cloud platform.
For security-critic customers who need a private environment, deploying BDC with AKS private cluster is a good way to restrict use of public IP addresses. Furthermore you can use UDR ( user-defined routes) to restrict egress traffic. You can do this with automation scripts are available on SQL Sample Github repo – private-aks.
Deploy AKS private cluster with automation scripts
Go to the Github repo to deploy AKS private cluster from here with your client in Linux OS or using WSL/WSL2. There are two bash scripts of you can use to deploy AKS private cluster:
You can use deploy-private-aks.sh to provision a private AKS cluster with private endpoint, and fto limitthe use of public addresses as well as egress traffic, use deploy-private-aks-udr.sh to deploy BDC with AKS private cluster and limit egress traffic with UDR ( User-defined Routes ).
Here we take more common case where a you deploy BDC with AKS private cluster. After downloading the script on the client environment, you can use the following command to execute the script :
chmod +x deploy-private-aks.sh
sudo ./deploy-private-aks.sh
Input your Azure subscription ID, the resource group name, and the Azure region that you wish to deploy your resource:

The deployment will take a few minutes. You’ll be able to find the deployed resources on your Azure portal after the deployment completes.
Access to AKS private cluster
After you deploy a private AKS cluster, you need to access a VM to connect to AKS cluster. There are multiple ways to help you manage your AKS private cluster, and you can find those at this link. Here we’re using the easiest option, which is to provision a management VM which installs all required SQL Server 2019 big data tools and resides on the same VNET with your AKS private cluster, then connect to that VM so you can get access to private AKS cluster as follows :

Deploy BDC with AKS private cluster with automation script
You can download the script deploy-bdc.sh to deploy BDC without a public endpoint:
chmod +x deploy-bdc.sh
sudo ./deploy-bdc.sh
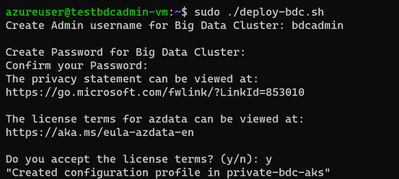
This requires you to set up the BDC admin username and password, and then it kicks off a BDC cluster deployment:

At the end of the deployment, the script will list all the BDC endpoints :

Connect to BDC in AKS private cluster
Make sure all components of your BDC cluster show a healthy status :
azdata bdc status show
If all goes well, you’ll get this output:

You can use the SQL Server master instance in the cluster endpoint to connect to BDC cluster with SQL Server Management Studio or Azure Data Studio as shown here :

Wrap up
As we saw in the first part of this article, businesses are looking for a secure, portable way to create value from multiple sources of data. Using SQL Server’s Big Data Cluster ( BDC ) in an Azure Kubernetes Service ( AKS ) private cluster, they get exactly that. You’ve seen how to use two variations of scripts that are available on our repository to fit your network environment and security requirements. You can also customize the scripts with your specific requirements for the information such as IP addresses range, flags to add or remove an AKS feature while creating AKS cluster before deploying in your environment.

Recent Comments