This article is contributed. See the original author and article here.
Bring state-of-the-art search capabilities to your custom applications in content management systems with Azure Cognitive Search. Tour the latest enhancements with Semantic Search to surface relevant answers to your search queries.
Azure Cognitive Search is a PaaS solution that allows you to integrate sophisticated search capabilities into your applications. It helps you quickly ingest, enrich, and explore structured and unstructured data, and is available to everyone.
Azure and Bing teams have worked together to bring learned ranking models to Azure for you to leverage in your custom search solutions. Now search can extract and index information from any format, applying machine learning techniques to understand latent structure in all data. Distinguished engineer, Pablo Castro, joins host Jeremy Chapman, to walk you through the improvements and show you how the intelligence works behind these powerful capabilities.
Semantic Search—Relevance, Captions, and Answers:
- Create similar experiences to web search engines, but for your own application and on your own data.
- Search matches words, but also understands the context of the words relative to the words surrounding them.
- Offers a significant improvement in relevant results; all you have to do is enable it.
Spell correction, Inverted index, Prep model, and Re-ranker:
- Keyword searches return exact matches and ranking is often only based on the rate of relevant frequencies of the words.
- Capture nuances in the language for a more sophisticated machine learning model that’s course document relevant in the context of the query.
QUICK LINKS:
01:18 — Data ingestion
02:38 — Semantic Search
04:48 — How to get it running
06:59 — How the intelligence works
08:43 — Advancements in natural language processing
10:52 — How it avoids slow search results
11:35 — Wrap Up
Link References:
Get started with Azure Cognitive Search at https://aka.ms/SemanticGetStarted
Sign up for the public review of semantic search at https://aka.ms/SemanticPreview
Unfamiliar with Microsoft Mechanics?
We are Microsoft’s official video series for IT. You can watch and share valuable content and demos of current and upcoming tech from the people who build it at Microsoft.
- Subscribe to our YouTube: https://www.youtube.com/c/MicrosoftMechanicsSeries?sub_confirmation=1
- Follow us on Twitter: https://twitter.com/MSFTMechanics
- Follow us on LinkedIn: https://www.linkedin.com/company/microsoft-mechanics/
- Follow us on Facebook: https://facebook.com/microsoftmechanics/
Video Transcript:
– Up next on this special edition of Microsoft Mechanics, we’re joined by distinguished engineer Pablo Castro, to learn how you can bring state-of-the-art search capabilities to your custom applications in content management systems, including the latest enhancements with semantic search for ranking top search results and answers, that uses machine reading and comprehension to surface answers to your search queries. So, Pablo it’s a pleasure to have you on Microsoft Mechanics.
– Thanks Jeremy, happy to be here.
– And it’s a real privilege to have you on the show as one of the leaders for intelligent search at Microsoft and congrats on today’s announcements. But before we get into this though, for those of you who are new to Azure Cognitive Search, it’s a PaaS solution in Azure that allows you to integrate sophisticated search capabilities into your applications. As an example, large industrial manufacturer Howden use Azure Cognitive Search to be able to quickly drill into the details of customer equipment requests, so they can respond with accurate bids. Now, the Azure Cognitive Search platform helps you to quickly ingest, enrich and explore structured and unstructured data. And you can integrate Azure Cognitive Search into your customer-facing mobile apps or e-commerce sites and line of business apps. So Pablo, Azure Cognitive Search really brings together some of the best work for Microsoft across search and AI, and really makes it available for everyone.
– It really does. We’ve been lucky to be able to harness a lot of the amazing work of Microsoft research. We also combined it with our extensive partnership with the Bing team. We’ve developed a lot of advancements for Azure Cognitive Search. Everything starts with data ingestion, so you can bring data from any source. You can automatically pull data in from an Azure data source or you can push any data you want to the search index using the push API. Of course, this content is not uniform, it exists in different formats and it’s anything from records, to long text, to even pictures. So we taught search to extract and index information from any format, applying machine learning techniques to understand latent structure in all data. For example, we extract key phrases, tag images, the tech language, locations and organization names. And you can also bring your custom skills and models. This combination of cognitive search and with cognitive services, in fact makes search able to understand content of all nature.
– Right, and I remember a few years back, we actually showed a great example for this. So we took the John F. Kennedy files, really comprised of decades old, handwritten notes and photos and typed documents. Then with Azure Cognitive Search we could understand the data and even surface new insights that had never been seen before.
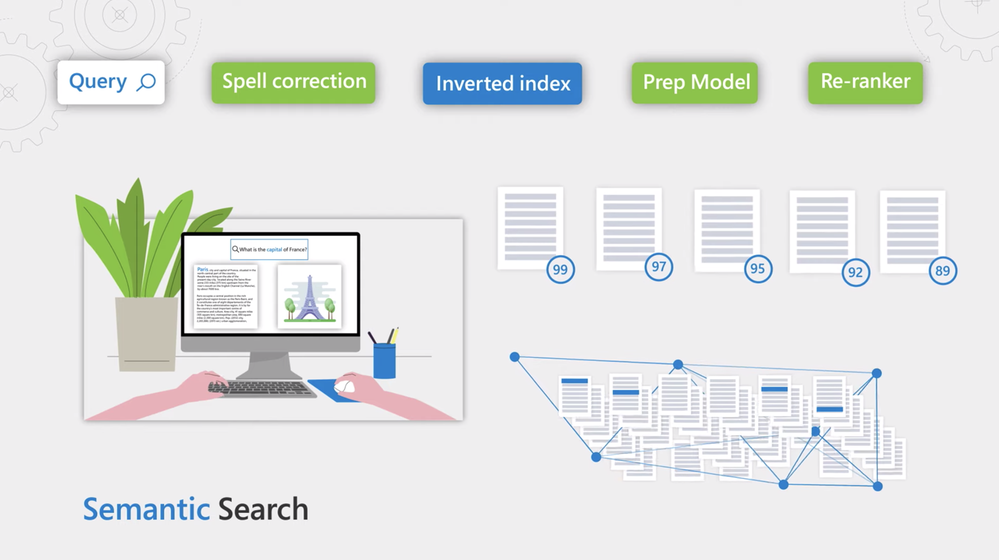
– Yeah, the sophistication of data ingestion, the smarts to understand and index content along with keyword search, it’s something we’ve had for a while. And we’ve seen many of you take advantage of this for lots of interesting scenarios. Today, we’re announcing the next step on this journey with the new semantic search capabilities that includes semantic relevance, captions and answers in preview today. I have this demo application that’s fronting a cognitive search index with a dataset that’s often used for evaluation purposes called MS Marco. Let’s search for what’s the capital of France. You can see that the results match the keywords in our search, but it looks like the ambiguity of the word capital in particular, caused top results to be a bit all over the place. We see capital punishment, capital gains, the capital of Kazakhstan, removals in France. Now, I’ll enable something brand new, semantic search. And this, I’ll auto-enable spelling as well. With semantic search, they Azure and Bing teams have worked together to bring state-of-the art learned ranking models to Azure for you to leverage in your custom search solutions. Now, if I go back to the page, you’ll see the results side-by-side, keyword search on the left, semantic search on the right. You can see how on point the new results are, they’re about France and they discuss it’s capital, with links to Britannica and World Atlas. Note, that this huge improvement in quality only required me to enable this option. Now, let’s take this to the next level with semantic captions and answers. Let me go back here into settings and enable both of these features. Not only do we see relevant results, but we can see captions under each result that are meaningful in the context of our query. We can also see an actual answer proposed by cognitive search. So now, you can create the same kind of experiences that web search engines offer but for your own application and on your own data.
– And what I love about this is that the answer is actually presented directly in the context of the search. And you don’t have to click on an additional link then, to find your answer. So what does it take then to add something like this, semantic search, into our apps?
– Well, it’s not that hard to get it running. Let’s first walk through how to ingest and enrich data in cognitive search, and then we can dive into the new semantic search. First thing to do, is to create a cognitive search service. I already have one created and I’m here in the portal with it open. I’m going to use import data to start this process. You can see, we support many Azure stores. In this case, I’m going to point to an existing blob storage account with unstructured data in it. In the next step I can enable one or more cognitive services or custom models to enrich the data I’m ingesting, so I’ll add enrichments. For example, I can enable optical character recognition, edit extraction, computer vision and more. Finally, I have the chance to customize my index definition and to set up indexer options. At this point, I’m done. And I have an ingestion process that will run automatically, detect changes, enrich data and push it into my index. I already created an index before, so we don’t have to wait for this process. Let’s go into this index and give it a quick try. I can search for say, France. And I can see the results coming back. Now in your application, you’ll typically use one of our client libraries or the HTTP API. Here, I’m in VS code and this is a typical HTTP request for the search API. Let me run it to see the results for the same search we did earlier. You can see we get the keyword search results. Now, I’ll just change the query type to semantic and reissue this query. You can see that now I’m getting the new, more relevant results, thanks to semantic relevance. That one line was all I needed, a few more tweaks will also enable captions and answers. And since these options don’t require re-indexing, you can easily try this on your existing applications as well.
– Right, and these all look like pretty simple API calls but behind the scenes at the service level, there’s a ton of complexity going on there.
– Right. We take care of the data science to give you state-of-the art search results without having to create your own ranking models from scratch. At the same time, we also take care of the infrastructure to run our ranking and machine learning models efficiently and fast.
– All of this, what you shown, would have taken a ton of effort if we were trying to build this ourselves, but what kind of improvements have you made to make all of this possible?
– So let’s start by explaining traditional keyword search. Here, you would match each word in a search query against an inverted index, which allows for fast retrieval of documents based on if they contain the words of search terms that you’re searching for. This returns documents that have those words. The problem with this is it only returns exact matches and ranking is often only based on the record relative frequencies of the words. Sometimes that’s what you want, such as when searching for part numbers like in the example you gave earlier with Howden, when you know precisely what to look for. However, when searching through content written by people, you want to capture the nuance in the language. So we added a few key components to improve search precision and recall. First, we added a step, so as a search query comes in, it passes through a new spelling correction service to improve document recall. Then we use the existing inverted index to retrieve all candidates, and we pick the top 50 candidates using a simple scoring approach that’s fast enough for scoring millions of documents quickly. We then added a new prep step for these search results by running another model that picks part of the document that matter the most based on the query. From there, the results are re-ranked via a much, much more sophisticated machine learning model that’s scores document relevance in the context of the query.
– And still there’s a lot more in terms of how the intelligence works. And in the examples that you demonstrated here, you showed how the semantic search wasn’t just matching words but also understanding the context of the words relative to the words surrounding them. So what makes all of this possible?
– This is where we take advantage of recent advancements in natural language processing. Let’s put this into context in terms of what it means for ranking and then for answers. First thing we need to do is to improve recall to find all candidate documents. So in our example search, a key concept was the word capital. The search engine needs to understand that the word capital could be related to states or provinces, money, finances or a number of other meanings. So to go beyond keyword matching, we use vector representations where we map words to high-dimensional vector space. These representations are learned, such as the words that represent similar concepts are close together in sort of a same bubble of meaning. These represent conceptual similarity, even if those words have no lexical or spelling similarity to the word capital.
– Okay, so how does it find then, the relationship between the words?
– So now that we have solved for recall, we need to solve for precision in results. Here Transformers, which is a novel neural network architecture, enabled us to think about semantic similarity, not just of individual words but of sentences and paragraphs. This uses an attention mechanism to understand long-range dependencies in terms, in ways that were impractical before. Particularly, for models this large. Our implementation starts with the Microsoft developed Turing family of models that have billions of parameters. We then go through a domain specialization process where we train models to predict relevance using data from Bing. For example, when I search for what is the capital of France, reading the whole phrase it’s able to identify the dependency between capital and France as a country, that puts capital in context and quickly return results with high confidence, in this case for Paris. And separately, we also build models oriented towards summarization as well as machine reading and comprehension. For captions, we apply a model that can extract the most relevant text passage from a document in the context of a given query. And for answers, we use a machine reading and comprehension model that identifies possible answers from documents and when it reaches a high enough confidence level, it’ll propose an answer.
– And the nice thing here is that Microsoft takes care of all the infrastructure to run these models. But as you say, they’re pretty large, so what are you doing then to operationalize these models into production to avoid slow search results?
– Yeah, you’re right. I mean, this models can be compute and memory hungry and expensive to run. So we have to right-size them and tune them for performance, all while minimizing any loss in model quality. We distill and retrain the models to lower the parameter count. So they can run fast enough to meet the latency requirements of a search engine. And then to operationalize these, we deploy these model on GPUs in Azure and when a search query comes in, we can parallelize over multiple GPUs to speed up scoring operations to rank search results.
– Great, so all of this then offers a great foundation then to achieve both high precision, as well as relevant search results. Now, there’s a lot behind just those few lines of code that light up these powerful capabilities, really as you build out your custom apps. But how can everyone learn more and then really start using this?
– You can try it out yourself. You can sign up for the public review of semantic search today at aka.ms/SemanticPreview. And we have more guidance on how to get started with Azure Cognitive Search at aka.ms/SemanticGetStarted.
– Thanks Pablo. And of course, for the latest updates across Microsoft, keep watching and streaming Microsoft Mechanics. Subscribe if you haven’t already yet and we’ll see you next time.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments