This article is contributed. See the original author and article here.
Have you ever wondered why your Service Fabric application upgrade is taking more time or have you observed deploying a new application is faster than doing upgrade to an existing app with the same code package? Then the following details may help with some insights.
When you deploy a new application to a Service Fabric cluster, it’s fast as it doesn’t do rolling upgrade and doesn’t do health checks whereas application upgrade to an existing application goes by UD(Upgrade domain) to UD walk and with health policy checks. The upgrade time for an app upgrade in service fabric is determined by multiple factors like, app package size, upgrade mode and the upgrade parameters etc. In this article I’m listing few common upgrade parameters here with their default values which play a role in the overall upgrade time.
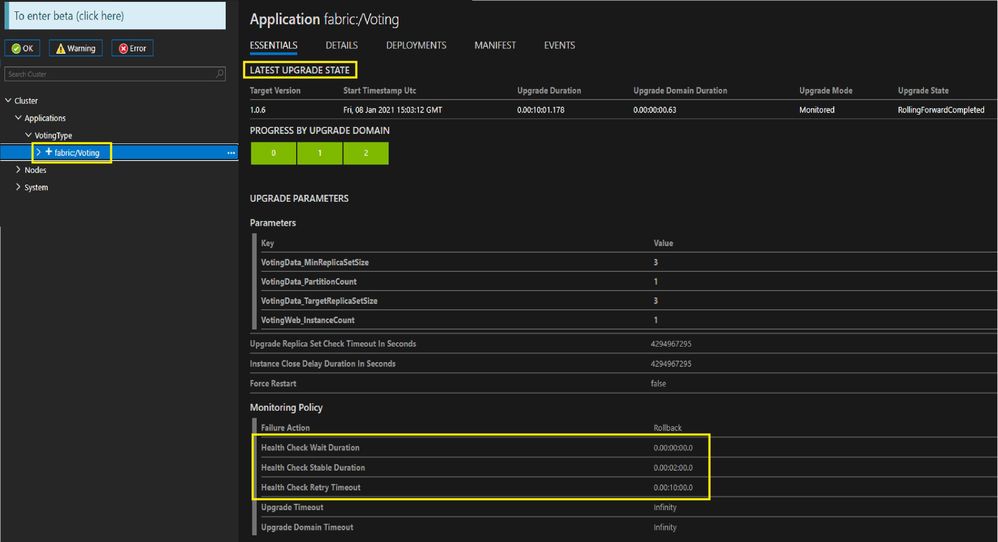
HealthCheckStableDurationSec: The duration (in seconds) to verify that the application is stable before moving to the next upgrade domain or completing the upgrade. This wait duration is used to prevent undetected changes of health right after the health check is performed. The default value is 120 seconds, and should be customized appropriately for your application.
HealthCheckWaitDurationSec: The time to wait (in seconds) after the upgrade has finished on the upgrade domain before Service Fabric evaluates the health of the application. This duration can also be considered as the time an application should be running before it can be considered healthy. If the health check passes, the upgrade process proceeds to the next upgrade domain. If the health check fails, Service Fabric waits for UpgradeHealthCheckInterval before retrying the health check again until the HealthCheckRetryTimeoutSec is reached. The default and recommended value is 0 seconds.
UpgradeHealthCheckInterval: The frequency of health status checks during a monitored application upgrades. This is service fabric level setting and can be updated with an update to the SF cluster resource update. Please find details here.
To see the above parameters in effect, take an example of a monitored upgrade where the HealthCheckStableDurationSec is set to default 2 mins and you have 5 UDs(Upgrade domain) in your cluster, then 10 mins (2 mins X 5 UDs) spent here during upgrade irrespective of the size of the app package. Similarly, every parameter plays role in your upgrade time and hence choose the parameter values which will be more appropriate for the application. Anytime you believe the application upgrade time takes longer, then inspect these parameters first to understand the expected upgrade time.
You can view values of these common upgrade parameters for an ongoing app upgrade or recently completed app Upgrade in SF explorer as below:
All these health checks and its wait time is applicable if the application upgrade is in a monitored mode.
As monitored application upgrade automates the upgrade and does application health check, the upgrade will include the health check and its wait time whereas in UnmonitoredAuto upgrade mode, the upgrade is automated, but skips the application health check. While with UnmonitoredAuto mode, the upgrade will happen faster, it’s useful for performing fast upgrade iterations during service development or testing and not recommended for production deployment. The Monitored upgrade mode is recommended for all Service Fabric upgrades.
You can pass the upgrade mode while initiating the application upgrade.
For complete list of upgrade parameters for each deployment mode (like for Visual Studio, PowerShell, sfctl), you can refer here.
With this, I would like to put forward the following key points to keep in mind whenever you’re concerned with app upgrade time in SF cluster:
- Compress the code package
- Adjust the upgrade parameters well as per your application for optimum upgrade time
- If possible, do a diff code package deployment instead of complete application package deployment
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments