This article is contributed. See the original author and article here.
There are considerable focus areas to infrastructure that the IaaS DBA needs to be aware of, so Part I of this blog can be found here.
Now that we’ve covered storage and VM series in Part I of this blog post on Infrastructure, we can go onto the detail areas for performance. Let’s start on performance gains with host caching.
Cache it Out Right
Host caching, by default, for premium SSD is turned off. This is a feature only available on certain VM series, (look for an ‘S’ in the D, E and M-series VMs.)
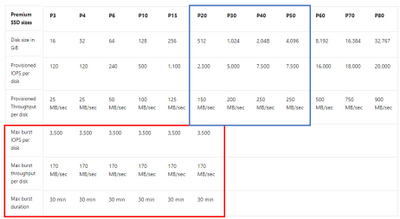
Turn on Read-Only host caching for the datafiles, archive logs and redo logs, but recognize that this is a feature only available on Premium SSD and that if you size the volume over 4095G, any host caching is turned off again. The limit is 4095G, so keep that in mind when you choose a P50 disk with it’s 4096G size. Attempt to allocate it all with read only caching on, as soon as you allocate that last 1G with an LVM create or ASM diskgroup creation command, the host caching will become disabled. You can use up to 4095G- that’s it.
Note the difference in cached vs. uncached performance for the VM you chose to use. We’ve had technical discussions on how “hard” these limits are, as there is also bursting that can cloud the final numbers, as seen in performance tests, but at this time, I recommend sticking to the values shown for the VM you’ve chosen, recognizing the VM values override anything at the storage level unless it’s Azure NetApp Files, (which is only limited by the NIC.)
As stated earlier, I’ll repeat- DON’T turn on read/write caching. These are datafiles and no one wants writes going to memory. We want our data written to disk! There is a risk of corruption in certain Oracle releases, too if this is accidently turned on.
Disk Bursting
Disk Bursting is something that has mixed reviews from most database technologists. On one hand, having the ability to “burst” IO performance for up to 30 minutes during batch loads or heavier IO usage is very beneficial, on the other hand, consistent performance is important because users expect this.
For RDBMS workloads, we can really only focus on the Esv3 series and a few of the Dsv3 series VMs. Disk bursting, like other IO topics, is a combination between the VM and the disk chosen to receive the feature.
To enable disk bursting at the disk layer requires smaller disks and isn’t available in all regions, so take the time to ensure you are deploying in the correct region and disk series P20 or below of premium SSD. If you have a workload that is hitting at the upper limits of the disk series you’ve deployed on, (again, under the P20) then you aren’t going to accumulate credits that can be used towards a bursting period. No, you aren’t robbing Peter to pay Paul, you’re accumulating credits of IO that you aren’t using in inconsistent workloads to be allocated to when you do need that burst of performance.

Premium SSD disks, disk bursting capabilities, (red) vs. those which are preferred for read-only host caching, (blue).
Be Smart with Your Linux Volumes
To use ASM or not to use ASM? That is the question. The answer is really about the ease of management and less about performance gains. There isn’t much that ASM can offer us here, but for the DBA, it does offer the ability to add to an existing diskgroup vs. creating a new volume when adding disk.
- Use 1MB stripe size to ensure the most optimal performance for Oracle, 64K for SQL Server.
- Stripe multiple disks together to combine them for higher IO capabilities. You’re still held to the IO limit at the VM, but you can reach those limits where you may not with just a single disk.
- Use the correct queue depths for SQL Server and match the vCPU count to calculate the DOP for Oracle.
Another common mistake we experience with customers- identify where the swap device is located in Linux. We’ve come across many customers who have placed the swap device on slower, managed disk vs. fast local disk, creating latency and throttling.
Remember not to use standard disk for your OS disk and consider the amount of IO required for anything placed on this disk. As my partner in crime remarked the other day, “I haven’t seen an Oracle environment on a VM perform optimally with a standard SSD for the OS Disk.” Consider Premium SSD for your OS Disk for any database VM.
Lay out Files Strategically
For small databases, all datafiles, redo logs and archive logs, (or transaction logs in SQL Server) can reside in one volume. As databases get larger or experience IO latency, the first step is to separate the appropriate files onto appropriate physical volumes. In Oracle, the redo logs, archive logs and for SQL Server, the transaction logs from the main datafiles.

If the database has exceptionally high IO vs. the managed disk chosen, consider mirroring and striping smaller disks, along with strategically positioning datafiles to get the most performance out of the database. Match datafile IO demands with the managed disk it resides on.
If you’re experiencing IO throttling at the VM tier, then it’s time to move away from managed disk and onto Azure NetApp Files, (ANF). ANF is constrained only by the NIC and can offer higher MBPs. ANF capacity pools can be connected to multiple VMs, offering simpler architecture and cloning solutions that are often part of the reason customers have moved to the cloud. When utilizing ANF, also consider using dNFS to benefit the performance, too.

Stop Backing up Your Databases
Yeah, I said it, but that’s not what I meant- most backup utilities, (looking at you, Oracle RMAN!) is slow and creates heavy IO situations. Most specialists don’t think twice about choosing slow, blob storage to backup databases to, but this can create a serious problem in IO throttling and latency issues in the database during night-time batch processing and other jobs.
Consider moving to snapshot technology that is database platform aware. For Oracle, that is Azure NetApp Files and Commvault, (although there are others, these are the two I’m most satisfied with.) Most snapshot technologies not only take a snapshot in a matter of minutes, (while the heavy lifting goes on behind the scenes, but it far from impacting to the database) and they also have the ability to create clones in as short of time, saving considerable resources. Many of these products provide object level backups, restores and a management interface to make maintaining the backups easy for the DBAs. With the time saved on backups, restores and refreshes, DBAs can get to more important and satisfying work.
There are significantly more infrastructure tips, but this is a good list to start with. If you have time and are registered for PASS Summit, I’ll be presenting on Migrating Oracle Workloads to Azure this week and next blog post, I’ll discuss more on the topic of Oracle optimization in the cloud!
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments