This article is contributed. See the original author and article here.
Data ingestion and preparation is the first experience data engineers go through before they can derive any insights from their data warehousing workloads. Synapse SQL within Azure Synapse Analytics has a distributed SQL processing engine which provides high-throughput data ingestion. There are best practices when loading data into a distributed cloud system like Synapse SQL that need to be considered when building data pipelines.
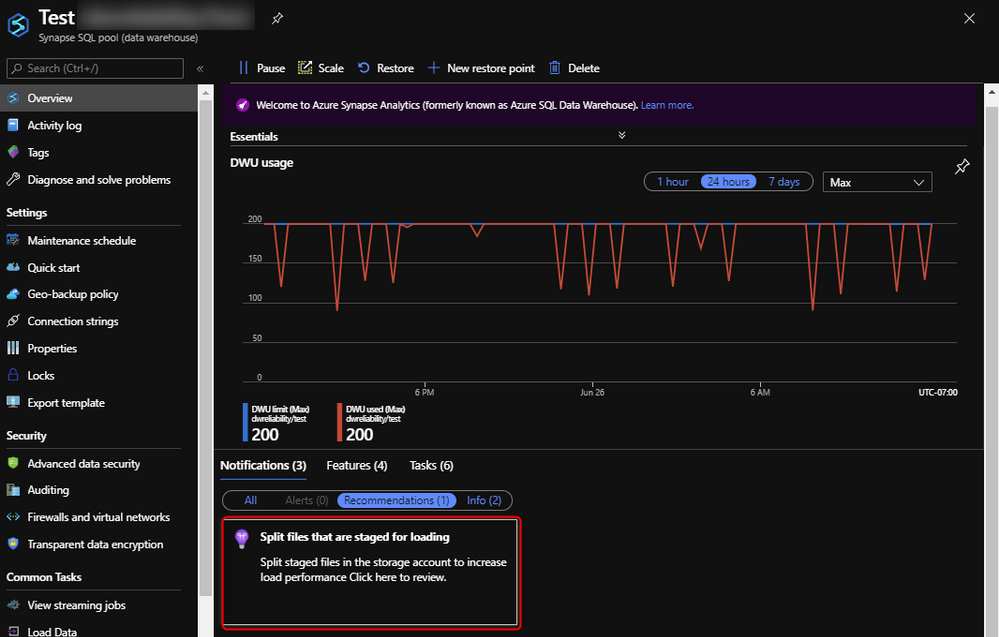
In the latest release of Azure Synapse, we have announced a set of new set of proactive recommendations so you can set up recommendation alerts, download recommendations to distribute within your team, or build applications and automated processes using the recommendations API. These new recommendations detect when you can improve your data loading process:
- File splitting guidance is automatically surfaced informing you when you should split your files for maximum load throughput
- Get alerted on when to increase batch size when loading data with SQLBulkCopy API or BCP
- Be informed of when to co-locate your storage account with your SQL pool to minimize latency
These recommendations are directly available in the Azure advisor blade or in the overview blade of your SQL pool:

For additional data loading guidance, visit the following documentation.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments