by Contributed | Aug 6, 2021 | Technology
This article is contributed. See the original author and article here.
If you’re migrating your data estate to Azure, as is normal considering Azure is an enterprise cloud that can be the home for all data, including Oracle, you may wonder what storage solutions there are to support these types of IO heavy workloads. Maybe you didn’t realize how important storage was to Oracle in the cloud. Most customers we word with are focused on what vCPU and memory are available in Azure, but for 95% of Oracle workloads, it’s IO that makes the decision on the infrastructure we choose and of that IO, its throughput, (MBPs) that is most often the deciding factor in the final VM sizes and storage type.
This post isn’t going to be about promoting one storage vendor or any solution over another, but hopefully help you understand that each customer engagement is different and that there is a solution for everyone, and you can build out what you need and meet every IO workload with Oracle, (or any other heavy IO workload) in Azure.
There are limits on storage, but more importantly, there are limits per each VM on storage and Network that must be considered. When choosing a VM, don’t just match the amount of vCPU and memory, but can the VM handle the throughput demands your workload will place on it. One of our favorite VMs types is the E-series ds v4. This sku series offers us the ability to have premium SSD for the OS disk, constrained vCPU versions if we need to have a larger “chassis” and memory with lesser vCPU for licensing constraints and higher throughput than we see with many others with similar configurations.
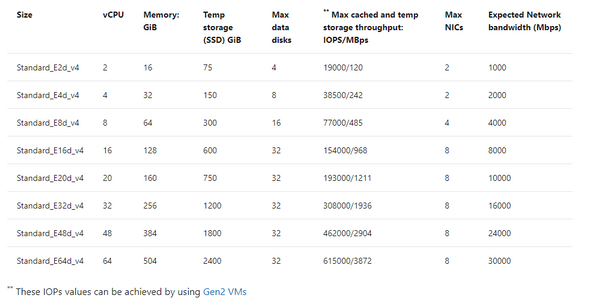
If you inspect the specifications by SKU size, you will see displayed the max cached IOPS/MBPs and Network bandwidth for the E ds v4 series:
Table 1, E-series, ds v4 VMs in Azure specifications
The above table will result in both premium disk and ultra disk being held to both storage and network limits displayed, or for solutions such as ANF, Silk, Excelero or Flashgrid, we’re held to only the network limits shown. As I stated earlier that throughput, MBPs is the biggest headache, not IOPs, (i.e., the number of requests) you can understand why the latter solutions come in handy with IO heavy workloads such as Oracle in Azure.
If you have sized out the Oracle workload for Azure properly, then you will know what you require in Azure IaaS to run it and can then choose the best VM, and storage needed. If you’re then puzzled by storage solutions, let’s take a deeper look and especially for Exadata, demonstrate what options there are.
Don’t Guess
I can’t stress enough, if you haven’t sized out the Oracle workload from an AWR that shows considerable database workload activity from the customer’s environment, you’re just guessing. Do NOT try to lift and shift the infrastructure, especially from an Exadata- you are AGAIN, wasting your time. An Exadata is an engineered system and there are infrastructure components that can’t be shifted over and more often is quite over-provisioned.
I also run into pushback on going through the sizing exercise. Many will want to simply take the existing hardware and lift and shift it to the cloud. This is one of the quickest ways to pay two or more times for Oracle licensing. I’m not going to argue with sales people who pushback with me on this, but chalk the deal or migration up as lost and go spend my time on a migration that’s going to be successful from the beginning.
Fight Me
So I know what the documentation says for storage IaaS VMs–

Table 2, Storage Options for IaaS VMs in Microsoft Docs.
Reality of what is best for Oracle on Azure may not agree with what is in this table and I’m going to tell you now, I don’t agree with the above table. Ultra disk may look appealing for Oracle, but we simply haven’t found the limitations vs. the cost for Oracle worthy, where for other uses, such as redo logs, it’s a fantastic win, (along with non-Oracle opportunities.) Ultra is still limited by the storage and network limit per VM, and this means that we can’t gain the throughput that we require for most heavy Oracle workloads with 2000+ MBPs.
Using example workloads, I can begin to direct and “evolve” our storage solution and the levels we use with real customer use cases:
Storage Name
|
Storage Type
|
Use
|
Standard HDD
|
Native
|
Not for use with Relational Databases
|
Standard SSD
|
Native
|
Less than acceptable for Oracle workloads or Oracle VM OS Disks
|
Premium SSD
|
Native
|
Standard Oracle Workloads and OS Disk, With Datafiles, always turn on ReadOnly host caching.
|
Ultra Disk
|
Native
|
Redo Logs, rarely for datafiles due to limitations.
|
Azure NetApp Files
|
Native with 1st Party Partnership
|
High IO Oracle Workloads, some Exadata
|
Silk
|
Third Party Partnership
|
High IO Oracle + Workloads, especially Exadata
|
Excelero NVMesh
|
Third Party Partnership
|
High IO Oracle + Workloads
|
Flashgrid Storage Fabric SW
|
Third Party Partnership
|
High IO Oracle + Workloads
|
NetApp Cloud Volume OnTap (CVO)
|
Third Party Partnership
|
High IO Oracle + Workloads, especially Exadata
|
Table 3, Storage options most common for Oracle in Azure
As you look at the table above, you realize that there are a few options at the lower IO workload levels and many at the higher ones. This is where knowledge of your workload and demands, along with unique features of each will come in handy when deciding.
Premium Disk
It is going to be very, very rare day that we place an Oracle workload on standard SSD. A P10 disk will be recommended practice for the OS Disk for each VM Oracle will be running on and then we need to start allocating storage for the datafiles, redo logs, etc.
We rarely, if ever come across Oracle databases that don’t need the IO horsepower for anything but Premium. With that, we get significant performance gain from ReadOnly host caching so the P40/P50, (minus that last 1Gb to leave it inside the limit for ReadOnly host caching of 4095 TiB) disks are our favorite and meet the needs of many Oracle workloads. For the smallest Oracle database workloads, we may use smaller premium SSD or stripe premium disk, as we can use multiple disks with a single ASM diskgroup. Always pay attention when choosing your VM size, there is a max number of data disks that can be attached, so this will also determine what storage you choose, (refer to table 1.)
ReadOnly host caching is only available on certain VM series/skus, as well as mid to high range premium SSD and limited to 4095 TiB. If you allocate a disk larger than that, the host caching will automatically be disabled. We hear a lot from Infra folks about “disk bursting”, either credit or On-demand versions with IO in Azure premium SSD storage. I haven’t had a customer workload that really could make use of it, but for smaller workloads, upwards of 30 minutes of bursting could be beneficial. For P40-P80, there is an unlimited bursting that can be an option at 1000 MBPs. Many customers batch loads in Oracle are just too intensive and too long to take advantage of credit-based bursting and On-demand or changing performance tier is too expensive or too inconsistent in performance for many. For relational database workloads, consistency in performance really is key. Most customers choose to stripe disks to get the max throughput from storage for most Oracle databases or choose higher tier storage, skipping bursting options all together.
Using the table below, you can see the size and the IO max for each premium storage, which tells you what you will be limited to for a single disk unless you stripe-
|
|
|
|
Premium Disk Size
|
Storage Amount
|
IOPs Max/Bursting
|
MBPs Max/Bursting
|
P10
|
128
|
500/3500
|
100/170
|
P20
|
256
|
1100/3500
|
125/170
|
P30
|
512
|
2300/3500
|
150/170
|
P40
|
1024
|
5000/30000
|
250/1000
|
P50
|
2048
|
7500/30000
|
250/1000
|
P60
|
8192
|
16000/30000
|
500/1000
|
P70
|
16384
|
18000/30000
|
750/1000
|
P80
|
32767
|
20000/30000
|
900/1000
|
When striping, again, you must be cognizant of the max number of disks you’re allowed per VM, remembering that the OS disk is counted as one.
Ultra Disk
We like Ultra disk, but it has numerous limitations when we start pricing out what it will take to run a database on it, realizing that it will be limited at the storage, not just the network limit per VM, that we have no volume snapshot mechanism or availability zone solution using it and the complicated pricing model, it ends up being a solution with limited use with Oracle. That use is redo logs when a database resides on premium disk and experiencing redo log latency.
More often a better option is to stripe premium disks to achieve upwards of 2000 MBPs, use Azure Backup volume snapshots to eliminate excess IO created by large RMAN backups and no need to spend more money on Ultra Disk.
Azure NetApp Files (ANF)
Many folks think this is a third-party solution, but it’s really a native solution in Azure in partnership with NetApp, and might need a rename to something like, “Azure Enterprise Files”. It’s a first tier storage for high IO workloads and is only limited by the network per VM. An ANF capacity pool is storage built at the region level, has HA built into the solution and can be allocated to multiple VMs, offering the ability to meet numerous workloads that other native solutions can’t. Along with robust cloning capabilities, shared volume snapshots across capacity pools even across regions, which can be used to bring up a second Oracle environment in a short order and avoid additional licensing that would be required if Oracle Data Guard was present.
ANF is also an excellent choice for datacenter migrations where a native storage solution is required or strict, Azure certified storage with high IO capabilities are needed.
Silk
As I work almost primarily on Exadata migrations, I spend a lot of time with Silk data pods. This is a third-party solution that uses a number of patented features to build out a Kubernetes data pod inside Azure, out of compute nodes, (D-series VMs) and management nodes, (L-series VMs) using the NVMe storage to accomplish fast IO. They have compression and dedupe that simplifies some of the additional “decoupling” I’d have to do with the loss of Hybrid Columnar Compression, (HCC) in Exadata. As the IO would grow considerably without HCC, I commonly use additional partitioning and Oracle Advanced Compression to try to make up for that loss.
Another feature that I love about Silk is it’s thin cloning. The ability to create a read/write clone and not have a storage cost is beneficial for E-Business Suite (EBS) and other Oracle applications that require consistent copies across multiple stage environments and the ability to save on storage while doing this, plus doing it quickly is fantastic. Anyone who’s used sparse clone on Exadata would love to have the thin clone in Silk, too.
The Rest
Excelero NVMesh I’ve only been working with for a short while and same with Flashgrid Storage Fabric. While both, like Silk, use VMs and the local storage to creation high IO solutions with the only per VM limitation at the Network layer, they don’t have some of the additional features such as compression/dedupe, thin cloning and volume snapshots. I’ve also been introduced to NetApp Cloud Volume OnTap,(CVO) which marries the best of onprem OnTap storage with Azure in a third-party solution that is closer in features to Silk and can benefit Exadata workloads that rely on HCC, thin cloning and snapshot backups.
The How
When deciding what solution to go through, it’s important to identify the following:
- The vCPU and memory requirements
- The IO, both IOPs and MBPs, especially the latter limit for the VM
- Using the size of the database, along with IOPS/MBPs, then choose the type of storage, (premium or high IO)
- The business’ SLA around Recovery Point Objective (RPO) and Recovery Time Objectcive (RTO) will tell you then which solution will be best that meets the IO needs.
- A secondary service can be added to create additional functionality, (as an example, we add Commvault to ANF to add additional cloning features at a low cost).
So let’s take a few example and look at what kind of combinations you might choose:
Example Oracle Workload #1
- 16 vCPU
- 128G of RAM
- IOPS 22K
- MBPs 212M
- DB Size: 5TB
- Backup Size: 23TB
- RPO/RTO of 15 min/8 hrs
I know this may seem limited on all that you might need to size it out, but we are assuming a sizing assessment has been done from an AWR and from this we can come up with the following recommendations:
Recommended VM: E16ds v4
Storage Option A
- 1 Premium P10- OS Disk
- 6 Premium P40 Disks- Datafiles and Redo Logs
- 24 TiB of Azure Blob Storage- Backups
- Backup strategy: RMAN
Storage Option B
- 1 Premium P10- OS Disk
- 5 Premium P40 Disks- Datafiles
- 40G Ultra Disk- Redo Logs
- 24 TiB of Azure Premium Blob Storage- Backups
- Backup Strategy: Azure Backup for Oracle
Example Oracle Workload #2
- 32 vCPU
- 480G RAM
- IOPs 100K
- MBPS 2800M
- DB Size 8TB
- Backup Size 28TB
- RPO/RTO of 15 min/2 hrs
Due to the limited RTO, I would use Oracle Data Guard to support the 2 hr RTO, as an RMAN recovery from storage wouldn’t meet the requirements for the DR on it’s own.
Recommended VM: E64-32ds v4 constrained vCPU VM
- 1 Premium P10- OS Disk
- Storage Option A: ANF with capacity pool and snapshot taken every 10 minutes to secondary capacity pool in separate region.
- Storage Option B: Excelero with Oracle Data Guard secondary in second Availability Zone, using Fast-start Failover and Observer/DG Broker and RMAN backups to Premium file storage.
Example Oracle Workload #3
- 16 vCPU
- 85G of Ram
- IOPs 300K
- MBPs 4500M
- DB Size 12T
- Backup Size: Using ZDLRS from Oracle
- RPO/RTO of 5 min/1 hr
- Using Exadata features HCC, smart scans, storage indexes, flash cache and flash logging
Recommended VM: E16ds v4, (extra memory will come in handy with the SGA and PGA grows post migration)
- 1 Premium P10- OS Disk
- Storage Option A: Silk with Data Guard, thin cloning, and volume snapshot and their compression/dedupe. Lessen post migration optimization that will need to be done.
- Storage Option B: ANF with Data Guard, volume snapshot for backups to eliminate some of the overhead of IO from RMAN, add Oracle advanced compression and partitioning, along with build out a partitioning strategy to assist with increased IO with loss of HCC.
With the examples above, I stuck to the E-series, ds v4 type VMs, as again, these are some of our favorite skus to work with Oracle on Azure in IaaS. Realize that we do have options for each type of workload, but that depending on the IO, there are different solutions that will meet the customer’s requirements and it’s important to have the right data.
by Contributed | Aug 6, 2021 | Technology
This article is contributed. See the original author and article here.
Introduction:
In this blog, we will look at how we configure near real-time monitoring of SQL Server on Linux and containers with the Telegraf-InfluxDB and Grafana stack. This is built on similar lines to Azure SQLDB and Managed Instance solutions already published by my colleague Denzil Ribeiro. You can refer to the above blogs to know more about Telegraf, InfluxDB and Grafana.
A quick rundown of all the tasks we’ll be carrying out to complete the setup:
- We will first install the Telegraf, InfluxDB, and Grafana containers on the monitoring host machine. You may be wondering why containers are used? because they are simple to set up and also provide isolation.
- Then, we will prepare the target SQL Server instances that we will monitor by creating the login on all of the target SQL Server instances (SQL Server on Linux/containers/Windows) that telegraf will use to connect to SQL Server instances for data collection.
- As this is a demo, I am running all three containers on a single host machine, but depending on the instances you monitor and data that is collected, you may decide to run the containers on different nodes.
- The data retention policies of InfluxDB will then be configured. The retention policy ensures that Influxdb does not grow out of bounds.
- Finally, we will configure and set up Grafana to create our dashboard with graphs and charts.
Let’s Build:
For this demonstration, the host on which I deploy the containers is an Azure VM running Ubuntu 20.04. I’m collecting data from the four SQL Server instances listed below:
- A SQL Server instance running on RHEL.
- Two SQL Server container instances, one deployed using the Ubuntu image and the other using the RHEL image.
- A SQL Server running on Windows.
Let’s start deploying containers:
- Install docker on the Ubuntu 20.04 host, which is our monitoring VM. To install Docker on Ubuntu 20.04 VM, refer to this article.
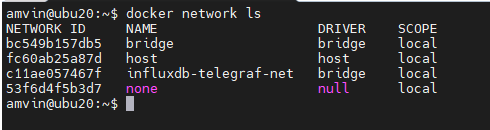
- Run the command below to create a docker network. This is the common network on which all three containers (Telegraf, InfluxDB, and Grafana) will be deployed.
docker network create --driver bridge influxdb-telegraf-net
#You can change the name of the network from “influxdb-telegraf-net” to whatever you want.
you can list the network using the command
docker network ls
We will now create the SQL Server login that telegraf will use to connect to the target SQL Server instances. This login must be created on all target SQL Server instances that you intend to monitor. You can change the login name from telegraf to any other name of your choice, but the same also needs to be changed in the telegraf.conf file as well.
USE master;
CREATE LOGIN telegraf WITH PASSWORD = N'StrongPassword1!', CHECK_POLICY = ON;
GO
GRANT VIEW SERVER STATE TO telegraf;
GO
GRANT VIEW ANY DEFINITION TO telegraf;
GO
Run the following command to deploy the telegraf container
docker run -d --name=telegraf -v /home/amvin/monitor/sqltelegraf/telegraf.conf:/etc/telegraf/telegraf.conf --net=influxdb-telegraf-net telegraf
# where:/home/amvin/monitor/sqltelegraf/telegraf.conf is a telegraf configuration file placed on my host machine, please update the path as per your environment.
# please ensure that you change the IP addresses and port numbers to your target SQL Server instances in the telegraf.conf file that you create in your environment.
Note: You can download the sample telegraf.conf from here. Please remember to change the IP address to your target SQL Server instance IP addresses.
- Run the following command to deploy the InfluxDB container
docker run --detach --net=influxdb-telegraf-net -v /home/amvin/monitor/data/influx:/var/lib/influxdb:rw --hostname influxdb --restart=always -p 8086:8086 --name influxdb influxdb:1.8
# where: /home/amvin/monitor/data/influx is a folder on the host that I am mounting inside the container, you can create this folder in any location.
# please ensure you set the right permissions so files can be written inside this folder by the container.
- Deploy the Grafana container using the following command
docker run --detach -p 3001:3000 --net=influxdb-telegraf-net --restart=always -v /home/amvin/monitor/data/grafana:/var/lib/grafana -e "GF_INSTALL_PLUGINS=grafana-azure-monitor-datasource,grafana-piechart-panel,savantly-heatmap-panel" --name grafana grafana/Grafana
# where: home/amvin/monitor/data/grafana is a folder on the host that I am mounting inside the container, you can create this folder in any location.
# please ensure you set the right permissions so files can be written inside this folder.
With the containers now deployed, use “docker ps -a” to list them, and you should see something like this:

Note: Please ensure that you open the ports on the host to which Grafana and InfluxDB containers are mapped to, in this case they are 3000 and 8086 respectively.
Let’s now setup retention policy on InfluxDB to ensure that there is limited growth of the database. I am setting this for 30 days, you can configure it as per your requirement.
sudo docker exec -it influxdb bash
#then run beow commands inside the container
influx
use telegraf;
show retention policies;
create retention policy retain30days on telegraf duration 30d replication 1 default;
quit
Setting up Grafana:
We are now ready to create the dashboard, before that we need to setup Grafana and to do that follow the below steps:
- Browse to your Grafana instance – http://[GRAFANA_IP_ADDRESS_OR_SERVERNAME]:3000
- First time you login into Grafana, login and password are set to: admin. Also take a look at the Getting Started Grafana documentation.
- Add a data source for InfluxDB. Detailed instructions are at in the grafana data source docs
- Type: InfluxDB
- Name: InfluxDB (this is also the default)
- URL: http://[INFLUXDB_HOSTNAME_OR_IP_ADDRESS]:8086. (The default of http://localhost:8086 works if Grafana and InfluxDB are on the same machine; make sure to explicitly enter this URL in the field. )
- Database: telegraf
- Click “Save & Test”. You should see the message “Data source is working”.
- Download Grafana dashboard JSON definitions from the repo from here and then import them into Grafana.
You are ready and this is how the dashboard should look, feel free to modify the graphs as per your requirement.



by Contributed | Aug 5, 2021 | Technology
This article is contributed. See the original author and article here.
Abnormal Security, an app available in Azure Marketplace, uses advanced artificial intelligence detection techniques to stop targeted phishing attacks. The cloud-native email security platform protects enterprises by detecting anomalous behavior and developing a deep understanding of people, relationships, and business context. Abnormal Security is a member of the Microsoft Intelligent Security Association.
Azure Marketplace interviewed Ben S., an IT director in the manufacturing sector, to learn what he had to say about the product.
What do you like best about Abnormal Security?
Abnormal Security stood out to us as a nuanced and unique way to approach the idea of business email compromise. Through their behavioral engine, they would build out personas for what is normal and expected interaction for your employee base, and through that identification, they would classify what is abnormal activity. And they carry that forward from your internal personnel to the vendor base that you contact and interact with.
It does a really great job of providing reporting both at a high level and then down to the granular details. So there’s a handful of dashboards that help to show attack trends and attack types, whether it be credential phishing, malware scam, or social engineering. Any of those types of categories it’s able to represent both in percentage and count. It’s also able to show attacker origin. And then the other piece that I think is incredibly helpful is that, for the emails it does remediate or take action on, it doesn’t just do that blindly. It actually takes that email message and is able to highlight the pieces that caused its threat score to be elevated so that you, as a security analyst or a support individual, can go through and understand what it is you’re looking at and know why something would be considered a threat or malicious.
How has the product helped your organization?
We saw a lot of banking impersonation and, in some cases, internal invoice impersonation taking place. We were receiving pretty legitimate-looking invoices from known vendors. But they were coming from different email servers. There were also instances where the external contact had been compromised and the invoice had banking information changes to it, trying to get us to wire funds to an attacker’s bank account. Abnormal had a great proof of concept that they were able to walk us through. From the time we turned it on, we saw immediate results from that. The solution integrates with our Exchange Online environment and doesn’t sit in line like a traditional secure email gateway type of solution. It sits next to it and maintains that same visibility. So if an attack is identified after the fact, it’s still connected to the point where it’s able to then do post-remediation and pull those delivered messages out from mailboxes.
Another useful feature is the abuse mailbox. It’s a function that allows us in IT support to leverage some email client toolbar applications for employees to be able to submit suspect messages. Previously that was a manual effort by our security team, where that would become a helpdesk ticket item that then would require hands-on analysis by someone on my team.
How are customer service and support?
Customer service has been great. When we reached out and started to engage with them on the proof of concept, they were tremendous in helping to get the platform configured. And then that carried forward to when we were customers as we were getting more and more familiar with the platform and asking questions, primarily around why certain emails were classified the way they were. Those were all easy-to-open cases where we got connected with dedicated support personnel. They configured this solution for us so that we have some flexibility in some different classifications, most notably the ability for us to maintain our VIP list of people that potentially are at higher risk, or that we want additional scrutiny around because of approval power.
Any recommendations to other users considering this product?
I think the biggest thing in the security space is there are a ton of different solutions and platforms trying to address similar issues. It’s important, when you’re looking for a solution, to understand what you’re looking to address. Financial loss, for us, was one of the biggest drivers, and in the evaluations we did, Abnormal showed the best capabilities to help address that risk.
What is your overall rating for this product?
5 out of 5 stars.
Cloud marketplaces are transforming the way businesses find, try, and deploy applications to help their digital transformation. We hope these improvements make your experience in Azure Marketplace intuitive and simple. Learn more about Azure Marketplace and find ways to discover the right application for your cloud solution needs.

by Contributed | Aug 5, 2021 | Dynamics 365, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Human interaction is at the cornerstone of every experience and today’s world has dramatically shifted what that means. Customers expect each touchpoint with businesses to be authentic, timely, and efficient, which has led to a rapid acceleration of customer engagement tools. Perhaps most important is customer service scenarios, where businesses must act on customer feedback to deliver in the moment. However, many businesses are falling short on this key activity, leading to more dissatisfaction and inefficiency.
61 percent of companies don’t close the loop with customers who gave feedback (Forrester)1
Customer service is paramount to the success and longevity of customer relationships. That’s why Dynamics 365 Customer Voice brings powerful data, sentiment, and satisfaction analysis to Dynamics 365 Customer Service. With easy-to-use tools, your team will be empowered with the right information at the right time. To learn more about how to get started using Dynamics 365 Customer Voice with Dynamics 365 Customer Service, read our free e-book, “The Power of Knowing Your Customers.”
Panduit boosts loyalty by automating surveys
Companies that emphasize customer service are at the forefront of delivering great experiences. They adapt their systems to meet customer demands while elevating how they operate in a digital environment.
Panduit, a global electrical and network infrastructure manufacturer, took this to heart as they rebuilt their customer service group into a broader customer experience organization. With Dynamics 365 Customer Voice and Customer Service, Panduit built a single platform to create a data-driven culture centered on the customer. They used survey results to track its Net Promoter Score as a strategic way to monitor overall customer sentiment and loyalty.
“For us, Dynamics 365 trumped its competitors because it’s such an easy platform to use. Now that [our customer service teams] get near real-time feedback in the voice of the customer, our advocates understand exactly what they need to change or continue doing” Jim Dillon, Director of Order Fulfillment, Panduit.
A connected service and voice of customer program doesn’t just impact the customer’s experience, it positively shifts how the company operations. Streamlined data and real-time insights into the customer make exceeding customer expectations simple, freeing up time for developers to work on other impactful projects. No longer can silo data be an effective form of understanding customers, and companies need to shift their systems into comprehensive platforms to provide the best customer experience.
Read more about how Panduit used Dynamics 365 to understand their customers.
Accelerate empathy and effectiveness of agents
Your customer service department is arguably the doorstep to your brand, products, and perception. From online chats to support agents, each avenue is a make-or-break moment for the customer and their relationship with your brand. These moments are built on two things: empathy and efficiency.
Dynamics 365 Customer Voice maximizes the effectiveness of the support you give customers, creating tailored interactions and cultivating longevity. Within Dynamics 365 Customer Service, chat agents can send surveys after a purchase or service, automatically capturing direct feedback. Additionally, surveys can be created as a feedback and customer service mechanism, giving businesses the opportunity to resolve complaints. Watch the video below to learn how to easily use surveys in Dynamics 365.
Agents who have access to automatically analyzed feedback from Customer Voice can help customer service departments continually understand their customers. And, with automation tools, agents can gather satisfaction scores and utilize the data to create more effective and efficient service calls and support chats. True digital transformation of customer service departments starts with the customer and with quality data, but ends with authentic connections. The technologies of tomorrow can create unparalleled value for organizations as agents can continually learn about the customer, improve their own effectiveness, and elevate brands.
The future of connected customer service
Connectivity is essential in a digital-first world, not just with customers but within companies. While each department has its own responsibility, they can all interact with the same singular customer making it critical that everyone is aligned on who that customer is, what their satisfaction is, and how to deliver on their wants and needs. A connected environment increases the chances for a positive experience, even in situations where a response is needed quickly.
63 percent of companies don’t have a cadence of sharing in line with decision making (Forrester)1
Aligning technologies across the department, from voice of customer solutions to customer service solutions to your customer data platform, creates a wealth of unified data that all agents can tap into. This can create a level of consistency and proactiveness unmatched by competitors. Connecting technologies isn’t just about aligning on data, it’s also elevating the knowledge of agents and their understanding of customers. The future will demand tailored, consistent experiences, and creating a comprehensive solution that pulls all your data together for every scenario will leave a lasting impact on your valued customers.
Learn more
To learn more about listening to customers and aligning data across your organization, visit the Dynamics 365 Customer Voice website or start your free Dynamics 365 Customer Voice trial today.
To learn more about delivering great customer service, visit the Dynamics 365 Customer Service website or start your free Dynamics 365 Customer Service trial today.
Download our free infographic to learn more about Dynamics 365 Customer Voice.
1- The State Of CX Measurement And VoC Programs, 2020, Faith Adams, Forrester, May 3, 2021.
The post Deliver authentic customer service with Dynamics 365 appeared first on Microsoft Dynamics 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments