
by Contributed | Mar 20, 2024 | Technology
This article is contributed. See the original author and article here.
Buenas,
Es un placer para nosotros, Bruno y Francis Nicole, compartir con ustedes nuestras impresiones sobre el primer episodio de la serie AI + .NET LATAM que tuvimos el honor de presentar la semana pasada junto con Ivana y Pablo.
El episodio inaugural de nuestra serie se centró en cómo la inteligencia artificial (IA) está revolucionando el mundo del desarrollo en .NET. Abordamos temas cruciales y compartimos recursos valiosos que, creemos, serán de gran utilidad para los desarrolladores interesados en esta área.
- Semantic Kernel con Heroes: Exploramos el repositorio de GitHub ‘understanding-semantic-kernel-with-heroes’, donde demostramos cómo utilizar los polyglot notebooks para aprender los fundamentos del Semantic Kernel.

- GPT-RAG en Azure: Discutimos el proyecto ‘GPT-RAG’ de Azure, que ilustra cómo habilitar Azure OpenAI a escala empresarial de manera segura, utilizando un patrón de Generación Aumentada por Recuperación.

- Formación Profesional en Azure 2024: Presentamos el programa de formación profesional de Azure para el año 2024, una oportunidad imperdible para aquellos que buscan profundizar sus conocimientos en IA y servicios en la nube.

- Control de Computadoras con OptiKey: Mostramos cómo OptiKey permite el control completo de computadoras y la comunicación mediante el uso de la mirada, abriendo nuevas posibilidades para la accesibilidad.

- Creación de Asistentes con Azure OpenAI Service: Ofrecimos una guía sobre cómo crear asistentes virtuales utilizando el servicio Azure OpenAI, proporcionando un camino claro para la integración de IA en aplicaciones.

- AI-in-a-Box: Analizamos el notebook ‘assistant-wind_farm’ que forma parte del proyecto AI-in-a-Box, destacando cómo la IA puede optimizar la gestión y operación de parques eólicos.

Recursos: https://www.theurlist.com/ainetlatam01
Para aquellos que no pudieron asistir al evento en vivo, hemos puesto a disposición todos los recursos mencionados y la grabación del episodio en los enlaces proporcionados. Les animamos a explorarlos y a sumergirse en el fascinante mundo de la IA y .NET.
Este primer episodio ha sido solo el comienzo de un viaje apasionante. Nos llena de entusiasmo ver la participación y el interés de la comunidad, y estamos comprometidos a seguir proporcionando contenido de calidad que impulse el conocimiento y la innovación.
Les agradecemos su apoyo y esperamos verlos en los próximos episodios.
Registro: https://aka.ms/IAyNET-LATAM
Redes de LinkedIn de Microsoft-Reactor:
https://www.linkedin.com/showcase/microsoft-reactor/
Un saludo,
Bruno y Francis

by Contributed | Mar 20, 2024 | AI, Business, Microsoft 365, Technology, WorkLab
This article is contributed. See the original author and article here.
Since we first introduced Copilot to our earliest customers, we’ve been closely studying how people are using AI at work—what’s going well, where there are challenges, and what early behaviors can teach us about adopting and rolling out AI broadly. And we want to share what we’re learning with leaders who are looking to drive AI adoption with their own people.
The post AI Data Drop: The 11-by-11 Tipping Point appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | Mar 19, 2024 | Technology
This article is contributed. See the original author and article here.
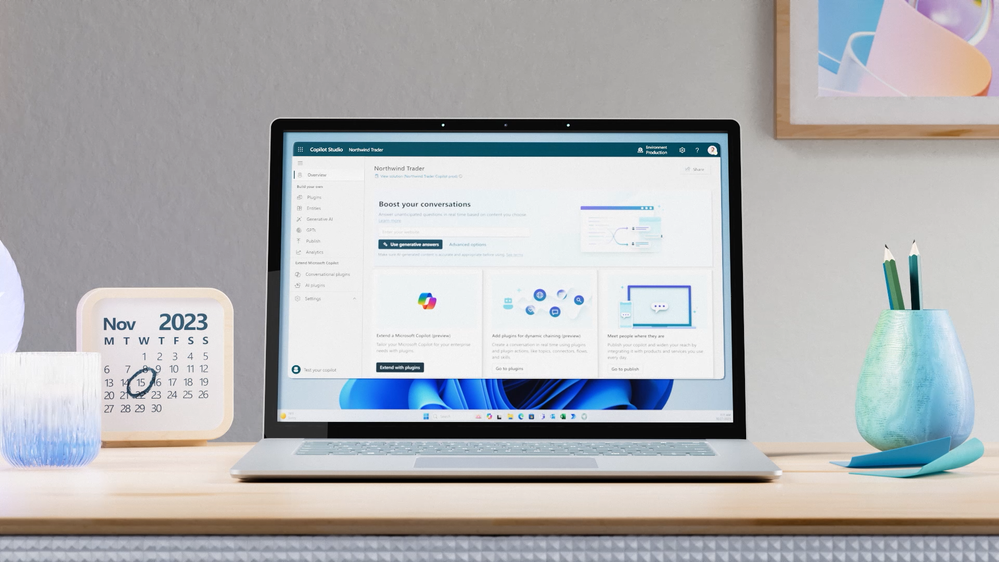
Copilot Studio app window open on the screen of a laptop on a table
Customizing Copilot for Microsoft 365 with Copilot Studio
Copilot for Microsoft 365 is your everyday AI companion that helps you create, find, and ask for information across Microsoft 365 apps. Whether you need to summarize a document, find relevant data, or generate content, Copilot can help you get things done faster and smarter. But what if you want to tailor Copilot to work the way you need, with your data, processes, and policies? That’s where Copilot Studio comes in.
Introduced in November 2023, Microsoft Copilot Studio is a low-code conversational AI platform that enables you to extend and customize Copilot for Microsoft 365 with plugins, as well as build your own copilots. Plugins are reusable building blocks that allow Copilot to access data from other systems of record, such as CRM, ERP, HRM and line-of-business apps, using 1200+ standard and premium connectors. You can also use plugins to incorporate your unique business processes into Copilot, such as expense management, HR onboarding, or IT support. And you can use plugins to control how Copilot responds to specific questions on topics like compliance, HR policies, and more.
Copilot Studio provides a visual canvas to create plugins, publish and manage them centrally, and secure them with the right access, data controls, and analytics. This is included in your Copilot for Microsoft 365 subscription and available in public preview today.
How Copilot Studio works
Let’s talk through how Copilot Studio in Copilot for Microsoft 365 works in action. Imagine you want to know how much of your team’s travel budget is left for the rest of the quarter. You ask Copilot in the chat, but it can’t answer because the data you’re looking for resides in your SAP system. With Copilot Studio, you can customize Copilot to connect to your SAP system and retrieve the information you need.
You start by launching Copilot Studio from within Copilot. You give your plugin a description, such as “providing richer details on expense questions”. You then choose the connectors you want to use, such as SAP or SharePoint (where perhaps your travel policy is stored). You can also use connectors to other data sources, such as websites, Azure services, or even OpenAI’s GPTs. You then design the logic and flow of your plugin, using conditions, variables, and actions. You can also specify how you want Copilot to generate responses, using natural language templates or expressions.
Once you’re done building your plugin, you hit publish. Copilot Studio will automatically create a metadata trigger for your plugin, so that Copilot knows when to use it. You can also manage your plugin settings, such as who can access it, what data is collected, and how it is monitored. And the best part is, you only need to build your plugin once, and it can be reused across your organization.
Now, when you go back to Copilot and ask the same question, Copilot will use your plugin to access your SAP data and give you the answer you were looking for. You can see how Copilot Studio can help you create rich and relevant experiences with Copilot, using your data and processes.
How Copilot studio will evolve in the future
Copilot Studio is a powerful tool for creating conversational plugins so you can tailor Copilot for Microsoft 365 to work the way you do, with the business data you use. While in preview, we are continuing to build Copilot Studio’s capabilities so you can enable richer and broader use cases. Over the next several months, Copilot Studio will evolve to include capabilities and features like –
- Plugins that can interact with the user – for example, by posing questions or presenting options and input boxes. Today, plugins are single-turn – Meaning, they can take in a user question and either, search over content to provide an answer, or possibly call a Power Platform Connector or flow to get information.
- Secure and seamless access to SharePoint and other Microsoft services, on behalf of the user. This will expand the range of scenarios Copilot Studio can support, such as accessing documents, calendars, emails, or other organization data that requires end-user credentials.
- More granular admin control on which users in the organization can use, create, or edit a plugin. Currently, plugin capability is controlled by the MAC Admin in an ‘all-or-none’ fashion and an admin can enable copilot studio plugins ‘as a category’ to a limited group of individuals for trials.
- Test control for plugins, so you can easily debug and validate plugins before publishing. This will also allow you to preview how your plugin will look and behave in Copilot for Microsoft 365 and make any adjustments as needed.
We are excited about the potential of Copilot Studio to create rich experiences with Copilot for Microsoft 365, using your data and processes and appreciate your ongoing feedback and suggestions as we continue to improve the experience. Stay tuned for more updates at Microsoft Build.
What else can you do with Copilot Studio?
Copilot Studio is a great way to customize Copilot for M365 to work with your data outside Microsoft 365. But that’s not all. If you’re interested in building your own custom copilot to provide generative AI experiences that Copilot for Microsoft 365 isn’t designed for, there is a separate Copilot Studio license, generally available, that allows you to build your own conversational copilots for customers or employees and publish it on any channel of your choice, such as websites, SharePoint sites, social media, and more. Organizations look to build their own copilot if they want to provide Gen AI experiences on channels not offered within Copilot for Microsoft 365 or would like to design employee and/or customer facing gen ai experiences. You can get started quickly designing a copilot with topics, plugins, automation and out of the box generative AI, allowing you to see value fast. You can even design the copilot with specific rules based dialog for greater control.
With Copilot Studio, you can create custom copilots for various scenarios, such as enhancing customer experiences, streamlining internal functions, or building innovative solutions. For example, you can create a copilot for your external website that can help customers check in-stock items, provide a quote, or book a service. Or you can create a copilot for your SharePoint site that can help employees with HR or IT requests, such as expenses or IT tickets. Or you can create a copilot that can leverage advanced AI services, such as vision, speech, or language, to create novel applications.
Copilot Studio makes it easy and fast to build your own copilots, using a low-code interface, drag-and-drop components, and pre-built templates. You can also test and debug your copilots, and publish them with a few clicks. And you can manage and monitor your copilots, using the same IT admin center as Copilot for Microsoft 365.
Get Inspired with Use Cases
If you are wondering how you can use Copilot Studio in your organization, here are some examples to get you started.
- Connect Copilot to your sales data in Salesforce and ask questions like “How many deals did I close this quarter?” or “What are the top opportunities in my pipeline?”
- Connect Copilot to your HR data in Workday and ask questions like “How many vacation days do I have left?” or “What is the process for requesting a leave of absence?”
- Connect Copilot to your finance data in SAP and ask questions like “What is the status of my expense report?” or “How much budget do I have left for this project?”
- Create custom topics for Copilot to respond to specific questions on compliance, legal, or policy matters, such as “What are the GDPR requirements for data retention?” or “What is the company’s policy on remote work?”
- Orchestrate workflows with Copilot using Power Automate, such as booking a meeting, sending an email, or creating a document.
Get started with Copilot Studio today
Copilot Studio is a powerful tool that can help you make the most of Copilot for Microsoft 365, and beyond. You can use it to connect Copilot to your data outside Microsoft 365, orchestrate workflows, and tailor Copilot responses to your business needs. You can also use it to build your own copilots, for customers or employees, and publish them on any channel of your choice. Whether you want to extend or customize Copilot, Copilot Studio can help you create conversational experiences that are rich, relevant, and intelligent.
To learn more about Copilot Studio, visit aka.ms/copilotstudio. To try it for yourself, go to aka.ms/trycopilotstudio. And don’t miss our Microsoft Build session, where we’ll share more announcements and demos.
We can’t wait to see what you create with Copilot Studio!
Additional Resources:
Continue the conversation by joining us in the Copilot for Microsoft 365 Community! Want to share best practices or join community events? Become a member by “Joining” the Microsoft 365 community. For tips & tricks or to stay up to date on the latest news and announcements directly from the product teams, make sure to Follow or Subscribe to the Copilot for Microsoft 365 Blog Space!

by Contributed | Mar 19, 2024 | Dynamics 365, Microsoft 365, Technology
This article is contributed. See the original author and article here.
End of support for Project Service Automation (PSA 3.x)
In April 2022, November 2022 and April 2023 release waves we announced the availability of the first, second and third and final phase of upgrade experiences from Dynamics 365 Project Service Automation to Dynamics 365 Project Operations. With the third and final phase of upgrade experiences, it is now possible to upgrade projects of any size to Project Operations. Today, we are announcing the deprecation of Dynamics 365 Project Service Automation or PSA 3.x.
As of March 31st 2025, Microsoft will no longer be supporting the PSA application. Beyond this date, there will not be any feature enhancements, updates, bug fixes or other updates to this application. Any support ticket logged on the PSA application will be closed with instructions to upgrade to Dynamics 365 Project Operations.
We strongly encourage all customers of PSA application to start planning your upgrade process as soon as possible so you can take advantage of many new Project Operations features such as:
- Integration with Project for the Web with many new advanced scheduling features
- Project Budgeting and Time-phased forecasting
- Date Effective price overrides
- Revision and Activation on Quotes
- Material usage recording in projects and tasks
- Subcontract Management
- Advances and Retained-based contracts
- Contract not-to-exceed
- Task and Progress based billing
- Multi-customer contracts
- AI and Copilot based experiences.
Upgrade documentation and FAQ links
Upgrade from Project Service Automation to Project Operations | Microsoft Learn
Project Service Automation end of life FAQ | Microsoft Learn
Feature changes from Project Service Automation to Project Operations | Microsoft Learn
Project Service Automation to Project Operations project scheduling conversion process | Microsoft Learn
Plan your work in Microsoft Project with the Project Operations add-in | Microsoft Learn
Learn more about Dynamics 365 Project Operations
Project Operations was first released in October 2020 as a comprehensive product to manage Projects from inception to close by bringing together the strengths of Dataverse, F&O and Project for the web assets. Want to learn more about Project Operations? Check this link and navigate to our detailed documentation!
Want to try Project Operations? Click here and sign up for a 30 days trial!
Thank you
Rupa Mantravadi
GPM, D365 Project Operations
The post Announcing End of Life for Dynamics 365 Project Service Automation appeared first on Microsoft Dynamics 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments