This article is contributed. See the original author and article here.
This is the third post of a series dedicated to the implementation of automated Continuous Optimization with Azure Advisor Cost recommendations. For a contextualization of the solution here described, please read the introductory post for an overview of the solution and also the second post for the details and deployment of the main solution components.
Introduction
If you read the previous posts and deployed the Azure Optimization Engine solution, by now you have a Log Analytics workspace containing Advisor Cost recommendations as well as Virtual Machine properties and performance metrics, collected in a daily basis. We have all the historical data that is needed to augment Advisor recommendations and help us validate and, ultimately, automate VM right-size remediations. As a bonus, we have now a change history of our Virtual Machine assets and Advisor recommendations, which can also be helpful for other purposes.
So, what else is needed? Well, we need first to generate the augmented Advisor recommendations, by adding performance metrics and VM properties to each recommendation, and then store them in a repository that can be easily consumed and manipulated both by visualization tools and by automated remediation tasks. Finally, we visualize these and further recommendations with a simple Power BI report.
Anatomy of a recommendation
There isn’t much to invent here, as the Azure Advisor recommendation schema fits very well our purpose. We just need to add to this schema some other relevant fields:
- Confidence score – each recommendation type will have its own algorithm to compute the confidence score. For example, for VM right-size recommendations, we’ll calculate it based on the VM metrics and whether the target SKU meets the storage and networking requirements.
- Details URL – a link to a web page where we can see the actual justification for the recommendation (e.g., the results of a Log Analytics query chart showing the performance history of a VM).
- Additional information – a JSON-formatted value containing recommendation-specific details (e.g., current and target SKUs, estimated savings, etc.).
- Tags – if the target resource contains tags, we’ll just add them to the recommendation, as this may be helpful for reporting purposes.
Generating augmented Advisor recommendations
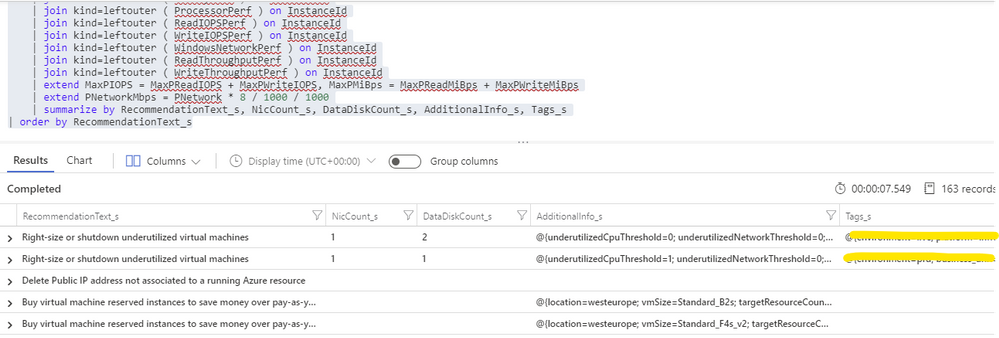
Having in the same Log Analytics repository all the data we need makes things really easy. We just need to build a query that joins Advisor recommendations with VM performance and properties and then automate a periodic export of the results for additional processing (see sample results below). As Advisor right-size recommendations consider only the last seven days of VM performance, we just have to run it once per week.

For each exported recommendation, we’ll then execute a simple confidence score algorithm that decreases the recommendation confidence whenever a performance criterion is not met. We are considering these relatively weighted criteria against the recommended target SKU and observed performance metrics:
- [Very high importance] Does it support the current data disks count?
- [Very high] Does it support the current network interfaces count?
- [High] Does it support the percentile(n) un-cached IOPS observed for all disks in the respective VM?
- [High] Does it support the percentile(n) un-cached disks throughput?
- [Medium] Is the VM below a given percentile(n) processor and memory usage percentage?
- [Medium] Is the VM below a given percentile(n) network bandwidth usage?
The confidence score ranges from 0 (lowest) to 5 (highest). If we don’t have performance metrics for a VM, the confidence score is still decreased though in a lesser proportion. If we are processing a non-right-size recommendation, we still include it in the report, but the confidence score is not computed (remaining at the -1 default value).
Bonus recommendation: orphaned disks
The power of this solution is that having so valuable historical data in our repository and adding other sources to it will allow us to generate our own custom recommendations as well. One recommendation that easily comes out of the data we have been collecting is a report of orphaned disks – for example, disks that belonged to a VM that was meanwhile deleted (see sample query below). But you can easily think of others, even beyond cost optimization.

Azure Optimization Engine reporting
Now that we have an automated process that generates and augments optimization recommendations, the next step is to add visualizations to it. For this purpose, there is nothing better than Power BI. To make things easier, we have meanwhile ingested our recommendations into an Azure SQL Database, where we can better manage and query data. We use it as the data source for our Power BI report, with many perspectives (see sample screenshots below).
The overview page gives us a high-level understanding of the recommendations’ relative distribution. We can also quickly see how many right-size recommended target SKUs are supported by the workload characteristics. In the example below, we have many “unknowns”, since only a few VMs were sending performance metrics to the Log Analytics workspace.

In the exploration page, we can investigate all the available recommendations, using many types of filters and ordering criteria.

After selecting a specific recommendation, we can drill through it and navigate to the Details or History pages.

In the Details page, we can analyze all the data that was used to generate and validate the recommendation. Interestingly, the Azure Advisor API has recently included additional details about the thresholds values that were observed for each performance criterion. This can be used to cross-check with the metrics we are collecting with the Log Analytics agent.

In the History page, we can observe how the confidence score has evolved over time for a specific recommendation. If the confidence score has been stable at high levels for the past weeks, then the recommendation can likely be implemented without risks.

Each recommendation includes a details URL that opens an Azure Portal web page with additional information not available in the report. If we have performance data in Log Analytics for that instance, we can even open a CPU/memory chart with the performance history.

Deploying the solution and next steps
Everything described so far in these posts is available for you to deploy and test, in the Azure Optimization Engine repository. You can find there deployment and usage instructions and, if you have suggestions for improvements or for new types of recommendations, please open a feature request issue or… why not be brave and contribute to the project? ;)
The final post of this series will discuss how we can automate continuous optimization with the help of all the historical data we have been collecting and also how the AOE can be extended with additional recommendations (not limited to cost optimization).
Thank you for having been following! See you next time! ;)
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments