This article is contributed. See the original author and article here.
This is the second post of a series dedicated to the implementation of automated Continuous Optimization with Azure Advisor Cost recommendations. For a contextualization of the solution described in this and following posts, please read the introductory post.
Introduction
As we saw in the previous post, if we want to build higher confidence on Azure Advisor right-size recommendations and better inform decisions, we need to combine Advisor recommendations with additional data coming from other sources:
- First, we need Virtual Machines performance metrics to give visibility about why Advisor is recommending a downsize or shutdown. We need at least the last 7 days of aggregated metrics. There are many ways of collecting performance metrics for VMs in Azure – Azure Monitor platform metrics, Azure Log Analytics or Azure Diagnostics guest agent, or even a third-party monitoring solution. As we want to combine all data together into a single repository, using the Azure Log Analytics agent is the simplest approach, as performance metrics will automatically land where they will later be queried from. Of course, if you do not (or don’t want to) monitor your VMs with the Log Analytics agent, you can still ingest into Log Analytics the performance metrics aggregates coming from your favorite source. This series will only cover the Log Analytics agent scenario, though.
- To validate whether a SKU recommended by Advisor can actually be used for a specific VM, we must check how many data disks and network interfaces are being used, as all SKUs have limits regarding these resources. The quickest and simplest way to get that information is to query Azure Resource Graph (ARG) for all our VMs.
- Finally, if we want to validate if the current disk IOPS and throughput profile are supported in the recommended SKU, we must collect data about all VM disks, namely disk type (OS vs. data) and host caching options. Again, we will call ARG to the rescue! And having disks data, we can easily get an extra recommendation not yet supported by Advisor – guess what (more details in the next post :smiling_face_with_smiling_eyes:)!
Now let’s look at each of these data sources in detail and start building our Azure Optimization Engine pipeline.
Collecting Virtual Machine performance metrics
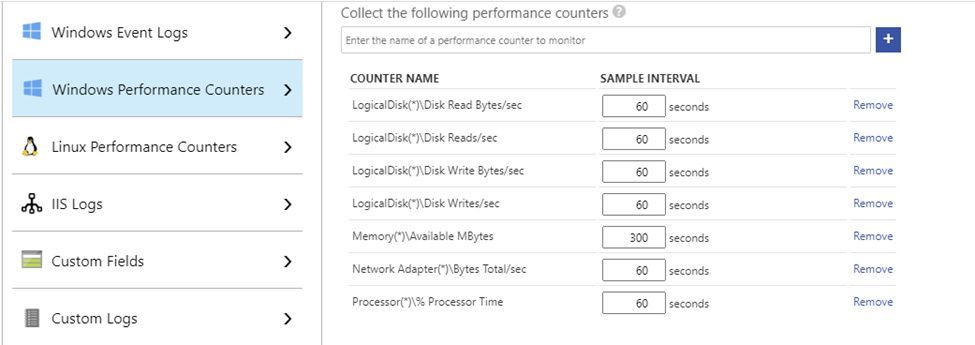
I am not going into the details of configuring the Log Analytics agent in your Azure Virtual Machines, as you have very good guidance in the official documentation. For collecting performance metrics with the Log Analytics agent, you have two options: the VM Insights solution and the agent native Perf solution. This series covers the latter option, as it provides more control over the metrics and collection intervals and we also want to optimize Azure consumption in the optimization tool itself ;) So, besides having all your VMs onboarded to Log Analytics, go to the Advanced Settings > Data blade and configure at least the following counters (if you already had your VMs being monitored by Log Analytics, then you just need to check if all needed counters are there):
- Windows
- LogicalDisk(*)Disk Read Bytes/sec
- LogicalDisk(*)Disk Reads/sec
- LogicalDisk(*)Disk Write Bytes/sec
- LogicalDisk(*)Disk Writes/sec
- Memory(*)Available MBytes
- Network Adapter(*)Bytes Total/sec
- Processor(*)% Processor Time
- Linux
- LogicalDisk(*)Disk Read Bytes/sec
- LogicalDisk(*)Disk Reads/sec
- LogicalDisk(*)Disk Write Bytes/sec
- LogicalDisk(*)Disk Writes/sec
- Memory(*)Available MBytes Memory
- Network(*)Total Bytes
- Processor(*)% Processor Time
Disk counters need to be separated in both read and write dimensions, because of the impact of read/write host caching definitions – when looking at disk performance, we must consider cached vs. non-cached virtual machine disk throughput/IOPS limits. For the same reason, we need to collect metrics for all disk instances, because host caching is defined per disk. Network throughput is collected as totals, because network bandwidth limits are independent of network adapter or direction. Processor metrics are collected for all CPU instances, because overall percentages can be misleading (e.g., 50% total CPU usage may be a result of 100% usage in 1 core and 0% in another). Each performance counter instance collected at a 60 second interval consumes about 430 KB per computer per day in Log Analytics. In a scenario with 4 logical disks and 4 CPU cores, each computer would generate 27 performance counter instances (20 for logical disk, 1 for memory, 1 for network adapter and 5 for processor). If all performance counters were collected at the same 60 seconds frequency, each computer would generate ~11 MB of data per day. Of course, you can adjust the collection interval for some counters, if you want your solution to be costs-savvy (see example below).

Collecting Virtual Machine and Managed Disks properties
Collecting VM and disks properties with ARG is super easy. The VM queries are straightforward and self-explanatory:
resources
| where type =~ ‘Microsoft.Compute/virtualMachines’
| extend dataDiskCount = array_length(properties.storageProfile.dataDisks), nicCount = array_length(properties.networkProfile.networkInterfaces)
| order by id asc
… for ARM VMs and …
resources
| where type =~ ‘Microsoft.ClassicCompute/virtualMachines’
| extend dataDiskCount = iif(isnotnull(properties.storageProfile.dataDisks), array_length(properties.storageProfile.dataDisks), 0), nicCount = iif(isnotnull(properties.networkProfile.virtualNetwork.networkInterfaces), array_length(properties.networkProfile.virtualNetwork.networkInterfaces) + 1, 1)
| order by id asc
… for Classic VMs.
For Managed Disks, the query is more complicated, because we want to distinguish between OS and Data disks:
resources
| where type =~ ‘Microsoft.Compute/disks’
| extend DiskId = tolower(id), OwnerVmId = tolower(managedBy)
| join kind=leftouter (
resources
| where type =~ ‘Microsoft.Compute/virtualMachines’ and array_length(properties.storageProfile.dataDisks) > 0
| extend OwnerVmId = tolower(id)
| mv-expand DataDisks = properties.storageProfile.dataDisks
| extend DiskId = tolower(DataDisks.managedDisk.id), diskCaching = tostring(DataDisks.caching), diskType = ‘Data’
| project DiskId, OwnerVmId, diskCaching, diskType
| union (
resources
| where type =~ ‘Microsoft.Compute/virtualMachines’
| extend OwnerVmId = tolower(id)
| extend DiskId = tolower(properties.storageProfile.osDisk.managedDisk.id), diskCaching = tostring(properties.storageProfile.osDisk.caching), diskType = ‘OS’
| project DiskId, OwnerVmId, diskCaching, diskType
)
) on OwnerVmId, DiskId
| project-away OwnerVmId, DiskId, OwnerVmId1, DiskId1
| order by id asc
No support for Classic VM disks, though, as they are unmanaged resources lying as a page blob in some Azure Storage container. Contributors are welcome!
For larger environments, we’ll need to implement pagination as ARG only returns the first 1000 rows for each query (the ARG runbooks scripts below will show you how).
Deploying the Azure Optimization Engine (data collection)
Now that we have some ground about the data we need to collect, we can finally start deploying the Azure Optimization Engine (AOE) solution! We are just looking at data collection for the moment – no augmented recommendations yet – but we will deploy here all the necessary foundations for the complete solution to be presented in the upcoming posts. In the links below, you’ll be directed to the AOE repository, where you’ll find sooner or later the complete working solution.
The AOE solution is made of the following building blocks:
- ARM template deploying Azure Automation account, runbooks and all required automation assets, Storage Account, SQL Database and, if needed, Log Analytics workspace. You can choose to reuse an existing Log Analytics workspace in case you were already monitoring your VMs before.
- Export-AdvisorCostRecommendationsToBlobStorage runbook – collects from Advisor API the most recent Cost recommendations and dumps them as CSV into a blob container.
- Export-ARGVirtualMachinesPropertiesToBlobStorage runbook – collects from ARG the whole list of VMs and respective properties and dumps them as CSV into a different blob container.
- Export-ARGManagedDisksPropertiesToBlobStorage runbook – collects from ARG the whole list of Managed Disks and respective properties and dumps them as CSV into a different blob container.
- Ingest-OptimizationCSVExportsToLogAnalytics runbook – scans a blob container and ingests all the unprocessed CSV blobs into a custom Log Analytics table (content type specific). To keep track of the CSV and number of CSV lines already processed, this runbook depends on a SQL Database, where it also gets details about the custom Log Analytics table corresponding to each CSV type.
- Deploy-AzureAutomationEngine.ps1 – full deployment script which kicks off the ARM template deployment and sets up the SQL Database at the end.
So, to deploy the AOE, you just need to run the Deploy-AzureAutomationEngine script in an elevated prompt and authenticating to Azure with a user account having Owner permissions over the chosen subscription and enough privileges to register Azure AD applications (see details). You’ll be asked several details about your deployment options, including whether you want to reuse an existing Log Analytics workspace or start with a new one.
The deployment will take some minutes to complete and you’ll be then be asked to enter a password for the Run As certificate for the Automation account. A couple of minutes more and the script will hopefully terminate successfully. In the event of an error, you can re-deploy with the same parameters, as the process is idempotent. You can check the Automation Account schedules created by the deployment (see picture below), which will trigger in a matter of a 1-2-hour timeframe.

Some minutes after all the ingestion runbooks run, you’ll be able to query in Log Analytics for those tables. We’ll make use of these records to generate our recommendations.

Once successfully deployed, and assuming you have your VMs onboarded to Log Analytics and collecting all the required performance counters, we have everything that is needed to start augmenting Advisor recommendations and even generate custom ones! Let it boil for some weeks and keep tuned – in the next post, we’re discussing how AOE produces the actual recommendations and we’ll going to finally see some light! 
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments