This article is contributed. See the original author and article here.
Synapse serverless SQL pool is query engine that enables you to query a variety of files and formats that you store in Azure Data Lake and Azure Cosmos DB. One very common text encoding format is UTF-8 encoding where the most common characters used in Latin western languages are optimally encoded with a single byte. Not very common western, Cyrillic, Turkish and other characters are encoded with 2 bytes, and special characters are encoded with more characters. UTF-8 encoding is popular because it is more optimal for majority of western languages, has the same storage efficiency as UTF-16 in most of the character sets.
Serverless SQL pool enables you to read UTF-8 encoded text, but you need to be careful to avoid conversion error that might be caused by wrong collations.
At the time of writing this post, Synapse SQL forces conversion of UTF-8 characters to plain VARCHAR characters if UTF-8 collation is not assigned to VARCHAR type. This behavior might cause unexpected text conversion error. In this article you will learn when this unexpected conversion can happen and how to avoid it.
What is collation?
Collation is property of string types in SQL Server, Azure SQL, and Synapse SQL that defines how to compare and sort strings. In addition, it describes encoding of string data. If collation name ends with UTF8 it represents strings encoded with UTF-8 collation, and otherwise you have something like UTF-16 encoded string.
In the following example is shown how to specify collation associated to string columns in external table definition:
CREATE EXTERNAL TABLE population (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
)
WITH (
LOCATION = 'csv/population/population.csv',
DATA_SOURCE = sqlondemanddemo,
FILE_FORMAT = QuotedCSVWithHeaderFormat
);
This table references CSV file and string columns don’t have UTF8 collation. Therefore, CSV file should not be UTF-8 encoded. Mismatch between encoding specified in collation and encoding in the files would probably cause conversion error. In this case, if your population data contains UTF-8 characters, they would be incorrectly converted once you read data. Therefore, you might need to use some UTF-8 collation instead of Latin1_General_BIN2 after COLLATE clause.
What are the UTF-8 encoded characters?
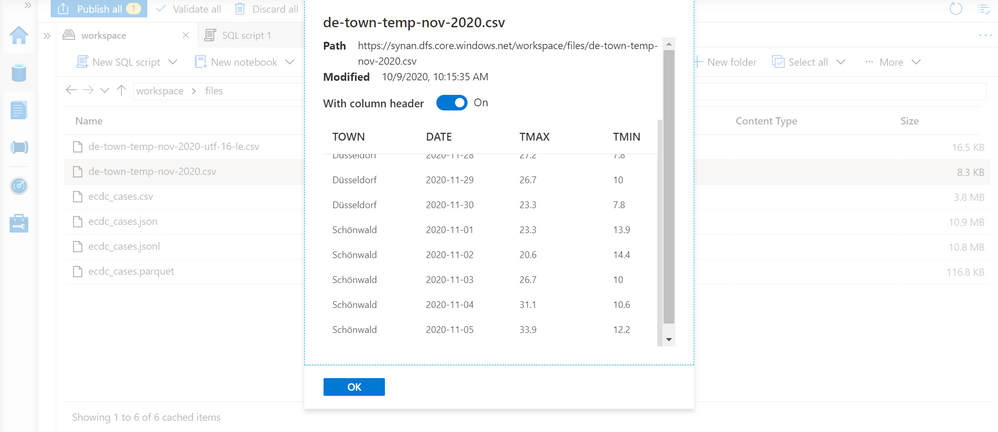
UTF-8 encoding represents most of the characters using 1 byte, but there are some characters that are not common in western languages. One example might be characters ü and ö in German words Düsseldorf and Schönwald.
Let us imagine that we have a CSV file encoded as UTF-8 text with the names of the towns containing these characters. If we preview the content of this file in Synapse Studio, we will get the following result:

Synapse Studio enables us to select this file and read the content using T-SQL queries with OPENROWSET function. Running a T-SQL query on database with default or any non-UTF8 collation might not return expected results:

You might see that the towns Düsseldorf and Schönwald are not same as in the preview on the previous picture.
In Synapse SQL, you must use some UTF-8 collation to return data for UTF-8 files. Otherwise, non-common characters would be suddenly converted.
At the time of writing this post, Synapse SQL silently forces conversion of UTF-8 characters to non-UTF-8 characters, which might cause conversion error. In future this behavior will be changed, and you will get explicit error if collation of string column that is returned by OPENROWSET is not UTF-8 and underlying text is UTF-8 encoded.
There are two ways to resolve this text conversion issue:
- Setting default collation for all string columns as database collation.
- Setting collation on every string column that OPENROWSET function returns.
Setting database collation
If you are working with UTF-8 data, the best way to configure your database is to set default collation on every database. You can set collation as part of CREATE DATABASE T-SQL statement:
CREATE DATABASE mydb
COLLATE Latin1_General_100_CI_AS_SC_UTF8;
If you have existing database, you can easily change collation on database:
ALTER DATABASE mydb
COLLATE Latin1_General_100_CI_AS_SC_UTF8;
From this point, every OPENROWSET will return correctly converted data.
Note that you would need to drop and re-create external tables if you have not explicitly specified collation. New default database collation will be applied only when table is created.
Specifying explicit collations
Instead of defining default database collation, you can explicitly specify collation when you declare column type using WITH clause.
OPENROWSET function enables you to explicitly specify columns and their types in WITH clause:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'latest/ecdc_cases.parquet',
DATA_SOURCE = 'covid',
FORMAT = 'parquet'
) WITH ( date_rep DATE, cases INT,
geo_id VARCHAR(6) COLLATE Latin1_General_100_CI_AS_SC_UTF8 ) as rows
If you are reading parquet files that have UTF-8 encoded text, or UTF-8 encoded text files, you would need to add UTF-8 collation in the type specification.
If you are defining tables, you can explicitly specify collation in column definition:
CREATE EXTERNAL TABLE population (
[country_code] VARCHAR (5) COLLATE Latin1_General_100_CI_AS_SC_UTF8,
[country_name] VARCHAR (100) COLLATE Latin1_General_100_CI_AS_SC_UTF8,
[year] SMALLINT,
[population] BIGINT
)
WITH (
LOCATION = 'csv/population/population.csv',
DATA_SOURCE = sqlondemanddemo,
FILE_FORMAT = QuotedCSVWithHeaderFormat
);
This way you can be sure that your table will return correct text regardless of database collation.
Conclusion
Matching column collation of string columns and encoding in files is important to avoid unexpected conversion errors. Currently serverless SQL pool silently converts UTF-8 data to non-UTF-8 data even if it knowns that there is a mismatch causing potential conversion error. This conversion would be treated as explicit error in the future, so make sure that you are using proper collations in OPENROWSET function and external tables to avoid errors.
Mitigation the issue is extremely easy, and you just need to alter database to use default UTF8 collation.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments