This article is contributed. See the original author and article here.
Hi,
In this article, I will walk you through some typical challenges when building AKS platforms. I will also reflect on the AKS impact over the Hub & Spoke topology, which is widely adopted by organizations.
Quick recap of the Hub & Spoke
I won’t spend much time on this because, most of you already know what the Hub & Spoke model is all about. Microsoft has already documented this here, although the proposed diagram is a little bit naïve, but the essentials are there. The Hub & Spoke model, is a network-centric architecture where everything ends up in a virtual network in a way or another. This gives companies a greater control over the network traffic. There are many variants, but the spokes are virtual networks dedicated to business workloads, while the hubs play a control role, mostly to rule and inspect east-west (spoke to spoke & DC to DC) and south-north traffic (coming from outside the private perimeter and going outside). On top of increased control over the network traffic, the Hub & Spoke model aims at sharing some services across workloads, such as DNS to name just one.
Most companies rely on network virtual appliances (NVA) to rule the network traffic, although we see a growing adoption of Azure Firewall.
Today, most PaaS services can be plugged to the Hub & Spoke model in a way or another:
- Through VNET Integration for outbound traffic
- Through Private Link for inbound traffic
- Through Microsoft-managed virtual networks for many data services.
- Natively, such as App Service Environments, Azure API Management, etc. and of course AKS!!
That is why we see a growing adoption of this model. The ultimate purpose of Hub & Spoke is to isolate workloads from Internet and have an increased control over internet-facing workloads, for which it is functionally required to be public (ie: a mobile app talking to an API), a B2C offering, an e-business site, etc.
The Hub & Spoke model gives companies the opportunity to:
- Route traffic as they wish
- Use layer-4 & 7 firewalls
- Use IDS/IPS and TLS inspection
- Do network micro-segmentation and workload isolation
Some companies push the micro-segmentation very far, by for example, allocating a dedicated virtual network for each and every asset, which is only peered with the required capabilities (internet in-out, dc, etc.), while others share some zones across applications. However, no matter what they do, they will still rely on network security groups and next gen firewalls to govern their traffic.
AKS, the elephant in the Hub & Spoke room
AKS is not a service like others, it has a vast ecosystem and a different approach to networking. An AKS cluster is typically meant to host more than a single application, and you can’t afford to “simply” rely on the Hub & Spoke to manage network traffic. Kubernetes is aimed at abstracting away infrastructure components such as nodes, load balancers etc. Most K8s solutions are based on dynamic rules and programmable networks…this is light years away from the rather static approach of NSGs and NVAs. A single AKS cluster might host hundreds of applications…That is why I consider AKS as the elephant in the Hub & Spoke room here. Somehow, AKS “breaks” the hub & spoke model, at least for East-West traffic. South-North traffic remains more controllable using traditional techniques, as it involves the cluster boundaries (IN and OUT).
Network plugins
Before talking about how you can isolate apps in AKS, let’s have a look at the different networking options for the cluster itself:
- Kubenet: K8s native network plugin. Often used by companies because of its IP friendliness. Only nodes get a routable IP while pods get NAT IPs. Kubenet comes with some limitations, such as max 400 nodes per cluster incurred by the underlying route table, whose the UDR limit is (400 routes max). Note that 400 nodes is a theoretical limit because you are likely to add your own routes on top of the AKS ones, which will reduce even more the max number of nodes you can have. Also, if you provision new node pools during cluster upgrades, that limit will even be lower. At this stage, you can’t use virtual nodes with Kubenet. NAT is also supposed to incur a performance penalty but I never perceived any visible effect. By default, you can’t leverage K8s network policies with Kubenet, but Calico Policy comes to the rescue. At last, because of NAT, you can’t use NSGs and NVAs the same way you would do with VMs or Azure CNI (more on that later).
- Azure CNI: The Azure Container Network Interface for K8s. In a nutshell, with Azure CNI, every pod instance gets a routable IP assigned, hence a potential high usage of IPs. With Azure CNI, you can leverage Azure Networking as if AKS was just a bunch of mere VMs. You also have K8s network policies available
- Bring your own CNI: features will vary according to the CNI vendor. Mind the fact that you won’t have MS support for CNI-related issues.
- AKS CNI Overlay (early days in 10/2022): this makes me thing of some sort of managed Kubenet. It has the benefits of Kubenet (IP friendly) but overcomes some of its limitations.
We will see later what impact the network plugin may have over traffic management, but let us focus first on a more concrete example.
South-North and East-West traffic
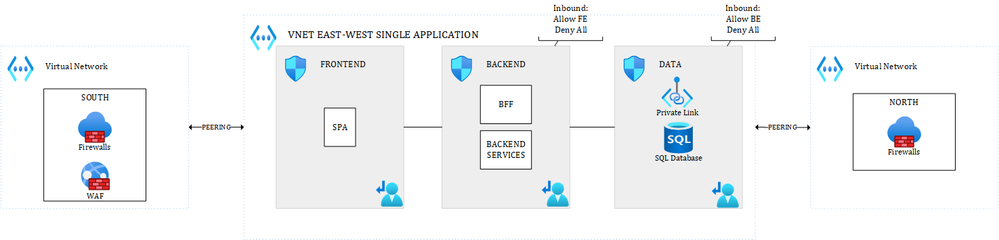
In a typical Hub & Spoke approach, a N-TIER architecture for a single application could look like this (simplified views):
Figure 1 – East-West and South-North traffic – Multiple Hubs
where the different layers of the application are talking to each other through the system routes and controlled by Network Security Groups (which is commonly accepted). Only traffic coming from outside the VNET (South) or leaving the VNET (North) would be routed through an NVA or Azure Firewall. In the above diagram, there are dedicated hubs for North & South traffic.
An alternative to this could be:

Figure 2 – Alternative for East-West and South-North traffic – Single Hub
where you’d have a single hub for South-North traffic, and where you might optionally route internal VNET traffic (East-West) of that single application to an NVA or Azure Firewall, if you really want to enforce IDPS everywhere and/or TLS inspection.
With UDRs and peering, everything is possible. The number of hubs you want to use depends on you. While multiple hubs improve visibility, they incur extra costs (at least one firewall or NVA per hub, and even more for HA and/or DR setup). Costs can rise pretty quickly.
For East-West traffic involving multiple applications, you would simply handle this with a hub (either the main hub, either an integration hub) in the middle (very typical this one):

Figure 3 – East-West traffic with the Hub in the middle
Whatever you put (VMs, ASE, APIM, other PaaS services…) inside the different subnets, all of this makes perfect sense in a Hub & Spoke network, but what about AKS?
As a reminder, an AKS cluster is a set of node pools (system and user node pools). A best practice is to have at least one dedicated system node pool and 1 or more user node pools. While it is a best practice, this is by no way enforced by Azure. Each node pool, except the system one, will result in 0 to n nodes (virtual machines), depending on the defined scaling settings. Ultimately, these nodes will end up in one or more subnets, as illustrated below:

Figure 4 – Subnets for worker nodes
Before diving into East-West traffic, let us focus on South-North for a second, because that is the easiest. You can simply peer VNET(s) to the AKS one to filter out what comes inside the cluster (where you’ll also have an ingress controller), and what goes outside of the cluster (where you could have an egress controller). Egress traffic could be initiated by a pod reaching out to Azure data services, other VNETs or Internet.
Regarding East-West and the above diagram, a few questions arise:
- Are you going to have one subnet for system node pools and one for user node pools?
- Are you going to combine altogether?
- Will it be one subnet per user node pool???
Note that, there is already one sure thing: you cannot use different VNETS to rule East-West traffic across applications hosted in the same cluster.… Your best possible boundary is the subnet. But, even though subnets could be used as a boundary, should you use NSGs, NVAs, etc. for internal traffic?? That is for sure not a cloud native approach to rely on this, but it does not mean you can’t use them. Let’s first make the assumption that you want to go the cloud native way. For this, you’d rely on:
- A service mesh such as Istio, Linkerd, Open Service Mesh, NGINX Service Mesh, etc. to apply layer-7 policies (access controls, mTLS, etc.)
- K8s network policies or Calico Network policies to apply layer-4 policies. Note that Calico also integrates with Istio.
And you would rely on this, independently of the underlying nodes that are being used by the cluster. This approach is fine, as long as:
- You master Service Meshes et Network Policies, which is not an easy task :).
- The process initiating or receiving traffic is a container running in the cluster.
Relying “only” on a Service Mesh and Network Policies to manage internal cluster traffic, can still let some doors opened to the following types of attacks:
- Escape from containers type of vulnerabilities, where the process would have access to the underlying OS. In such a case, the execution context will be insensitive to your mesh & network policies
- Operators logged onto the cluster worker nodes themselves, or host-level processes. Same as above, they could perform lateral movements escaping the control of your mesh & network policies.
With proper Azure Policy in place, you can manage to mitigate item number 1, at least to make sure that containers do not run as root, are not able to escalate privileges etc. Also, making sure images only come from trusted registries and are built on trusted base images, etc. will greatly help, but working on container CAPS is the best way to go. Of course, if there is an OS-level vulnerability or an admission controller vulnerability, you could still be at risk.
Item number 2 can be mitigated with strict access policies, making sure that not everybody has access to the private SSH keys. This is more of a malicious insider threat, which you should handle like any other malicious insider threat.
But by the way, why would you even want to go the Cloud native way and use a Service Mesh combined to Calico (or K8s network policies)?
– To build a zero-trust environment, based on layer-4 and layer-7 rules.
– To rely 100% on automation, since everything is “as code”, leading to predictable and repeatable outputs
– To benefit from the built-in elasticity and resilience of K8s, where pods can be re-scheduled in case of adverse event to any node that can accommodate the required resources.
– To benefit from smart load balancers that understand application protocols such as gRPC, HTTP/2, etc.
– To benefit from rolling upgrades and modern deployment techniques such as blue/green, A/B testing, etc.
– To have a greater visibility thanks to the built-in observability mechanisms that are part of service meshes
– To have more robust applications, which you can stress with chaos engineering techniques, again built-in in multiple meshes
All of these are very valid reasons to go the Cloud native way, but most organizations are just not ready yet for this mindset shift.
Risks highlighted above might be acceptable under the following circumstances:
– You host multiple applications, which are closely related to each other (same family, same business line, etc.)
– You host a single application in the cluster (yes, it happens)
– You host multiple applications belonging to a single tenant
It is of course up to you to define where to put the limits. However, if you host multiple assets belonging to different customers, in other words, if you have a true multi-tenant cluster, you will want to make sure a given customer cannot access another one. In that case, relying only on Service Meshes and K8s network policies might be more risky, and this is where subnet segregation and NSGs might come into play.
Multitenant clusters
Let us explore the possibilities for true multi-tenant clusters. Something you can end up with would look like this:

Figure 5 – Multitenancy in AKS – Possible setup
I got rid of the South-North traffic to focus only on East-West. You could isolate each tenant in a dedicated subnet and define the NSG rules you want. UDRs can be added on top.
When network plugin matters
With such a topology, network plugins matter. Let’s see how:

Figure 6 – POD to POD with Kubenet
With the Kubenet plugin, when POD1 and POD2 talk together, the NSGs will see the NAT IP, not even the underlying node IP onto which the pod is running. Because the mapping between each AKS node and a POD CIDR range is unpredictable, there is no way you could use the pod or underlying node IP in the NSG. With Kubenet, you’d be forced to allow the entire POD CIDR range for every subnet you have, else you might even block pods belonging to the same tenant to talk together. To isolate tenants, you’d then need to rely on:
– NSGs for the subnet ranges, not to rule how pod can/cannot talk together but to isolate tenant nodes from each other and mitigate lateral movements in case of container escape and direct access to underlying VMs.
– K8s network policies to prevent lateral movements from within the cluster. Optionally, adding layer-7 policies with a mesh
You would have to combine both NSGs and K8s network policies.
With CNI:

Figure 7 – POD to POD with CNI
POD1 and POD2 would see each other’s assigned routable IP, as well as NSG. Therefore, whitelisting internal subnet traffic only at the level of the NSG, would do the job. However, I would discourage the use of POD IPs in NSG rules because POD IPs are very volatile. Out of the box, there is no way to assign a static IP to a POD. This can be achieved with some CNI plugins but I don’t think it is a good idea. I would recommend to work with subnet-wide rules and/or node-level rules, not deeper. Of course, you can also use internal K8s network policies to apply fine-grained rules.
Managing resilience and availability
Ok, but, how do you make sure pods from tenant1 are not scheduled to tenant2 nodes? Well, there are multiple ways to achieve this in K8s. You can use node selectors, node affinity, taints & tolerations. By attaching appropriate taints or labels to your node pools, ie: tenant=tenant1, tenant=tenant2, etc., you could achieve this easily.
Great but, isn’t there something that bothers you here? What about the elasticity and K8s’built-in features to re-schedule pods on healthy nodes in case of node failures? With these siloes in place, you’d put your availability at risk….Well, this indeed not ideal, but there are some possiblities:
- Define each node pool as zone-redundant to maximize each tenant’s resilience
- Define each node pool with minimum 2/3 nodes (one per zone) to maximize each tenant’s active/active availability
Because all nodes belonging to the same node pool are tainted/labelled the same way, K8s would still be able to re-schedule pods accordingly should a given node suffer form hardware/software failure. Of course, such a setup would require many nodes (mind Kubnet’s 400 limit) and would incur huge costs.
CNI or Kubenet, impact on Egress
What will a data service (or anything else) see when a POD calls it?

Figure 8 – Egress traffic
- with Kubenet, the NSG around the data subnet will see the underlying node IP
- with CNI, the NSG will see the POD IP
Remember that with Kubenet, for internal traffic, even if it involves multiple nodes on different subnets, NSGs will see the NAT IP. However, for traffic leaving the cluster, the underlying node IP is seen. With CNI, it makes no difference whether traffic targets an internal or external service.
Combining best of both worlds
Beyond being multi-tenant or not, one setup which can be interesting is the following:

Figure 9 – Combining Cloud native with traditional approach
where you isolate key cluster features such as ingress & egress. For example, with a dedicated egress subnet for the Istio (for example) egress controller, could help you enforce Istio egress rules everywhere, by allowing only that subnet to get out of the cluster, while still giving flexibility to the ones managing the cluster.
Conclusion
The cost friendliest and the most cloud native approach to handle East-West traffic, consists in relying on K8s built-in mechanisms and ecosystem solutions such as Service Meshes & Calico, to make abstraction of the infrastructure and leverage the full K8s potential in terms of elasticity, resilience and self-healing capabilities. However, we have seen some limits of that approach, in some very specific scenarios. I would still advocate to work the cloud native way, unless you really deal with highly sensitive workloads and/or true multi-tenancy.
South-North traffic is not a game changer, whether you go cloud native or not. You will keep using WAFs and Azure Firewall/NVAs to manage that type of network traffic. Bringing back NSGs (and potentially NVAs) for East-West traffic can be challenging and the chosen network plugin dramatically impacts the NSG/UDR configuration. It can also potentially harm other non-functional requirements such as high availability, scalability and maintainability.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments