This article is contributed. See the original author and article here.
Azure Synapse Analytics is a big data analytics service that enables you to analyze data on Azure storage using SQL language. You can use SQL endpoints (provisioned and serverless) to analyze your data using SQL language.
SQL is very powerful analytic language that can be used to implement various types of time series analysis on big data. In this article, you will see how to use some slightly advanced or not well known SQL language concepts to analyze COVID cases using Synapse SQL serverless endpoint and Azure Open Dataset.
Prerequisite
To try this sample, you need to have Azure Synapse Analytics workspace. If you don’t have one you can easily deploy it using Azure portal or this Deployment template. Synapse workspace automatically deploys one serverless Synapse SQL endpoint that is everything we need for this kind of analysis. With the workspace you are also getting easy-to-use web UI called Synapse Studio that enables you to start analyzing files in your browser.
NOTE: You need Synapse SQL serverless (on-demand) query endpoint to execute the code in this article. The functionalities used in this article are still not available in provisioned endpoint.
COVID dataset
In this sample is used the latest available public data on COVID-19 cases worldwide from the European Center for Disease Prevention and Control (ECDC). Each row/entry contains the number of new cases reported per day and per country. For more information about this dataset, see here. Dataset is updated on daily basis and placed as a part of Azure Open Dataset.
OPENROWSET function
Synapse SQL endpoint in Synapse Analytics enables you to use OPENROWSET T-SQL function to analyze data on Azure Data Lake storage. This is easy to use function where you need to provide URL of some publicly available file on Azure storage and you will get the content of the file. Example of OPENROWSET function that reads the content of a parquet file placed on Azure storage is shown in the following example:
select *
from openrowset(bulk 'https://****.blob.core.windows.net/.../cases.parquet',
format='parquet') as cases
If you provide a file URL (for example https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases….) after the BULK keyword and specify that you are using parquet format, you will get the content of file.
This file is publicly available, so you don’t need some credential to read the content of the file. If the file is protected using Azure AD authentication or SAS token, follow the instructions in this article to setup permissions.
Analyzing COVID dataset
Probably the easiest tool that you can use to analyze the file is Synapse Studio – Web UI where you can write a T-SQL query and see the results in browser.
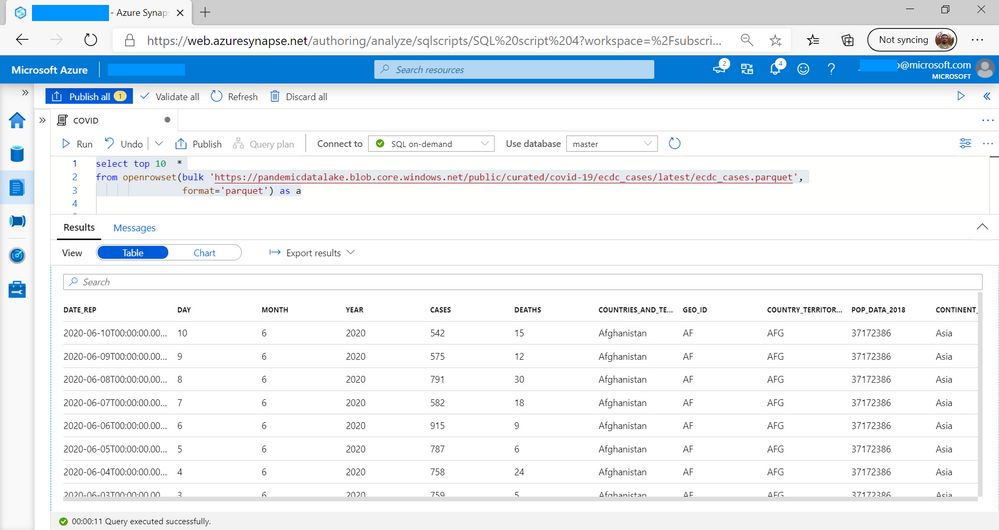
We can begin analysis by exploring the columns in data set on first 10 records:

Here I can see that some of the columns interesting for analysis are DATE_REP and CASES.
Synapse SQL provides powerful SQL query language where we can do any type of reporting on data set using standard where, group by, having, and order by SQL query option. As an example, the following report shows the number of cases per continents.

With rollup option is handy option that instructs Synapse SQL to automatically return sub-totals for each aggregated column, so you don’t need to calculate this on the client side. I can work with multiple categories (for example if you group by continent and country).
Now let’s see how we can analyze COVID data with SQL.
Displaying time series data
I would like to analyze number of cases reported in Serbia, so I would need to filter the results using GEO_ID column. Once I filter data and sort them by date reported, I can easily show number of daily reported cases as a chart in Synapse Studio:

Synapse Studio enables me to easily select few columns and display them on chart to do some easy data exploration.
Analyze cumulative data (running totals)
Analysis of the previous figure shows the daily cases, but we might want to see cumulative cases over time. Therefore, we would need to sum all cases up to current data and repeat this for every day. Fortunately, SQL has window aggregate function that can do this analysis:
CUMULATIVE = SUM(CASES) OVER (ORDER BY date_rep)
OVER clause instructs Synapse SQL to calculate sum on a window of rows relative to the current rows and sum all values ordered by date_rep. The result of the previous query with this window aggregate option are shown in the following figure:

Cumulative values are showing sum of cases up to the DATE_REP time. We can easily show these values on the chart in Synapse Studio:

Calculating daily changes
SQL language provides two useful window functions LAG and LEAD that enable us to fetch some value from one of the previous or next rows and compare them with the value in current row. As an example, let’s assume that we want to find daily over day changes in the number of reported cases in Serbia. Using the following formula (tomorrow_cases – today_cases)/today_cases, or simplified tomorrow_cases/today_cases -1. We can use the following functions to get the values from the surrounding rows:
LEAD(CASES) OVER (ORDER BY date_rep)
LAG(CASES) OVER (ORDER BY date_rep)In the OVER clause we need to specify sort order of the rows so these functions can know what criterion to use to find the previous row. By default, they find 1 previous or next row, but this can be changed by adding parameter in LAG/LEAD functions.
I will use these functions to find DoD change in Serbia based on formula above:

I have removed days with number of cases less than 50 to avoid noise because DoD rates have high peaks and variations in these days due to small denominators and big day-to-day variations.
Conclusion
SQL language enables you to do powerful analytics over data stored on your Azure Data Lake. In this examples you have seen how to use Synapse SQL endpoint in Azure Synapse Analytics to perform some advanced analytics on your COVID data.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments