This article is contributed. See the original author and article here.
This week the Azure Data Factory team is releasing the following new features in the ADF UX:
Array support for mapping data flow parameters
Array data types are now supported in mapping data flow parameters. You can pass in a list of an existing data type! Learn more on how to parameterize your mapping data flows.

Debug from job cluster
When operationializing your mapping data flows, you can now choose to run a pipeline debug run using either a running interactive debug cluster or with a just-in-time cluster using the integration runtime configuration of the activity.

Use the data flow debug session if you are running a single data flow with a small amount of data. This allows for you to test your business logic without having to wait a few minutes for a new cluster to start up.
For more advanced pipelines that move large amounts of data or have multiple concurrent data flow that run in parallel, use the activity runtime settings to spin up a new cluster. This allows for you to test different performance tuning options before you publish or merge your changes.
Filter by run id
When monitoring your pipelines, you can now look for an individual run by entering the run id into the filter search box. This can be useful for troubleshooting when you have many pipeline runs occurring in a factory.

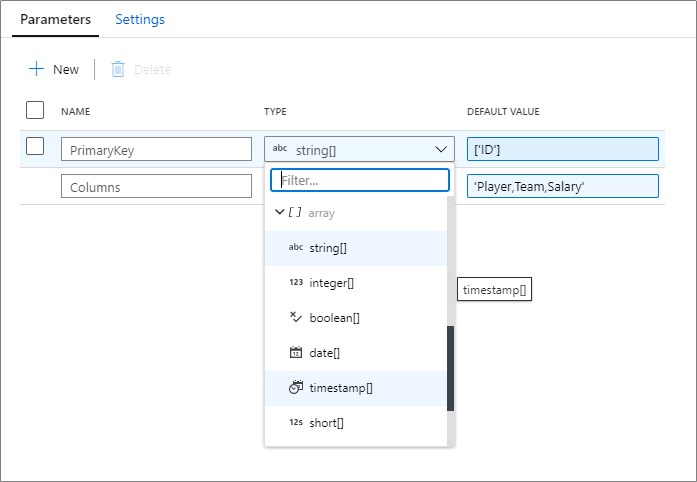
Parameterize key columns
When writing to database sinks using data flows, you may have upsert, updates or deletes enabled on the destination. If so, you must specify a primary key or list of primary keys. For scenarios where the number of primary keys is dynamic, you can now enter a custom expression that takes in an array of column names at run-time. For more information, learn about the alter row transformation.

Updated feedback experience
Lastly, we have updated the feedback form in the ADF UX. Feel free to let us know what you think about some of these new features!

Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments