This article is contributed. See the original author and article here.
While onboarding customers to Azure they ask what permissions do we need to assign to our IT Ops or to partners and I’ve seen customer gets confused when we ask them for Azure AD permission for some task and they say we’ve provided owner access on Azure Subscription why Azure AD permission is required and how this is related. So thought of writing this blog to share how many permission domains are there when you use Azure.
We will talk about these RBAC Domain:
Classic Roles
Azure RBAC Roles
Azure AD Roles
EA RBAC
MCA RBAC
Reserved Instance RBAC
Classic Roles
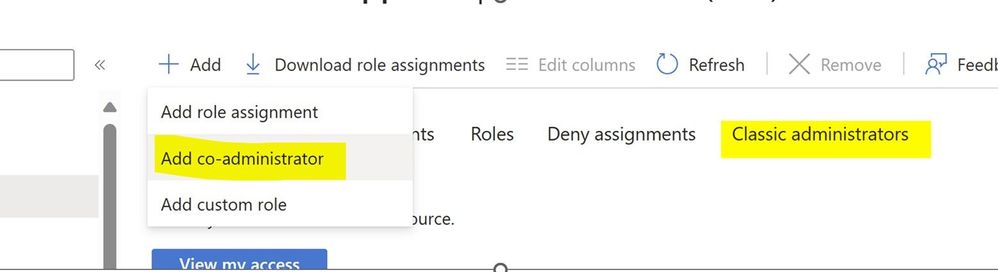
So let us talk about RBAC first – When I used to work in Azure Classic portal it used to be fewer roles. Mostly Account Admin, Co-Admin and Service Admin. The person who created subscription would become service Admin and if that person wanted to share the admin privilege, then he used to assign co-administrator role to the other guy
So when you go to Subscription -> IAM blade you’ll still see this. I have seen customers trying to provide owner access just try to use this Add Co-administrator button. Now you know the difference. This is not mean for providing someone access to ARM resource.
Azure RBAC
Let us talk about ARM RBAC now. When we moved to Azure RBAC from classic. We started with more fine-grained access control. With each service there was a role e.g. virtual machine contributor for managing VMs, Network contributor for managing network and so on. So, the user gets stored in Azure AD itself, but the permissions are maintained at subscription, resource group, management group level or resource level.
In each RBAC we have Actions which basically tells the role what it can perform.
The actions are part of the control plane. Which you get access to manage the service and its settings or configurations. We also have data plane actions. Which provides you the actual data access. Let us take an example of Azure Blob storage, if you get reader role you would be able to see the resource itself but will not be able to see the actual data in blob storage if you authenticate via Azure AD. If you want to see the actual data, then you can get storage blob data contributor role assigned to the ID and you can see the actual data. Similarly, there are services which expose data actions e.g. Azure Key vault, Service Bus.
Getting into where this RBAC roles can be assigned at Resource, Resource Group level or management group level is another discussion which I will cover in another blog post.
Azure AD Roles
This is used when you deal with Azure AD itself or services of which roles are stored in Azure AD like SharePoint, Exchange, or Dynamics 365. Dealing with Azure AD roles might be required during multiple instances, for example using service which creates service principals in the backend like app registration. Azure Migrate, Site recovery etc. would require Azure AD permissions to be assigned to your ID.
This RBAC Domain is separate from the Azure RBAC, this gets stored in Azure AD itself and managed centrally from roles and administrator’s blade.
The person who created the tenant gets a global admin role and then we have fine grained access based on the roles.
Though Azure AD roles are different than Azure RBAC which we assign to subscriptions, a global admin can elevate himself and get access to all the subscriptions in his tenant through a toggle.
Once you enable this toggle you get the user access administrator role at the root scope under which all the management group gets created. So eventually you can access all the subscriptions.
This is a rare and exceptional procedure that requires consultation with your internal team and a clear justification for its activation.
EA RBAC
If you are an enterprise customer and have signed up for the EA Agreement from Microsoft, as a customer in order to create subscriptions and manage billing you need to log on to EA portal which is now moved to Azure portal. Hence we’ve set of 6 RBAC permissions which can be used from cost management + billing section in Azure portal.
Enterprise administrator
EA purchaser
Department administrator
Account owner
Service administrator
Notification contact
Which set of permission is assigned at specific hierarchy can be explained through the below image. this is copied from Microsoft learn documentation mentioned below.
Below is the sample screenshot which you see when you click on cost management + billing portal. Here you will see Accounts, Departments, subscriptions.
MCA RBAC
If you have purchased MCA, then you get hierarchy for permissions to be assigned. Top level permissions are assigned at the billing scope and then billing profile level.
Billing account owner and Billing profile owner are the most common role you will use. More roles are mentioned in the article below which you can go through.
Reserved Instance RBAC
A common request from customers I get, I have got contributor/owner access to the subscription still I do not see the reserved Instance which is purchased by my colleague. Few years back the person who purchased reservation used to be the one who provided access to others by going to individual reservation. This is still possible but now you can get access to all reservations in the tenant.
Reservations when purchased by an admin he can see/manage it and seen by EA Admin or a person with reservation administrator role.
You can do this via PowerShell too, check this document for more information.
More information regarding who got access to RI is mentioned in the article below.
This article is contributed. See the original author and article here.
Hack Together: The Microsoft Fabric Global AI Hack
The Microsoft Fabric Global AI Hack is your playground for creating and experimenting with Microsoft Fabric. With mentorship from Microsoft experts and access to the latest tech, you will learn how to build AI solutions with Microsoft Fabric! The possibilities are endless for what you can create… plus you can submit your hack for a chance to win exciting prizes! ?
Learn how to create amazing apps with RAG and Azure Open AI
Are you ready to hack and build a RAG Application using Fabric and Azure Open AI?
?Join us for the Fabric AI Hack Together event and learn the concepts behind RAG and how to use them effectively to empower with your data with AI.
? You’ll get to hear from our own experts Pamela Fox (Principal Cloud Advocate at Microsoft) and Alvaro Videla Godoy (Senior Cloud Advocate at Microsoft) who will introduce you to the challenge, provide links to get started, and give you ideas an inspiration so you can start creating amazing AI solutions with minimal code and maximum impact. :fire:
?? You’ll also get to network with other hackers, mentors, and experts who will help you along the way. Come with ideas or come for inspiration, we’d love to hear what you’re planning to build!
This article is contributed. See the original author and article here.
If you’re using Azure Database for MySQL and have encountered issues with name resolution or the Domain Name System (DNS) when attempting to connect to your server from different sources and networks, then this blog post is for you! In the next sections, I’ll explain the causes of these types of issues and what you need to do to resolve them.
What are DNS issues?
DNS is a service that translates domain names (e.g., servername.mysql.database.azure.com) into IP addresses (e.g., 10.0.0.4) to make it easier for us to identify remember and access websites and servers.
However, at time the DNS service can fail to resolve the domain name to the IP address, or it might resolve it to the wrong IP address. This can result in errors such as “Host not Known” or “Unknown host” when you specify the server name for making connections.
Diagnosing DNS issues
To diagnose DNS issues, use tools such as Ping or nslookup to verify that the host name is being resolved from the source. To test using ping, for example, on the source, run the following command:
ping servername.mysql.database.azure.com
If the server’s name is not resolving, a response similar to the following should appear:
Fig 1: Ping request not returning IP
To test using nslookup, on the source, run the following command:
nslookup servername.mysql.database.azure.com
Again, if the server name is not resolving, a response similar to the following should appear:
Fig 2: nslookup to DNS request not returning IP
If on the other hand the commands return the correct IP address of the server, then the DNS resolution is working properly. If the commands return an error or a different IP address, then there is a DNS issue.
To verify the correct IP address of the server, you can check the Private DNS zone of the Azure Database for MySQL Flexible server. The Private DNS zone is a service that provides name resolution for private endpoints within a virtual network (vNet). You can find the Private DNS zone in the properties of the overview blade of the server, as shown in the following figure:
Fig 3: Checking the private DNS zone in the Properties of overview blade
In the Private DNS zone, you can see the currently assigned IP address to the MySQL Flexible server, as shown in the following figure:
Fig 4: Private DNS Zone overview
Resolving DNS issues
The solution to fix DNS issues depends on the source and the network configuration of the server. In this blog, I will cover two common scenarios: when the source is using the default (Azure-provided) DNS, and when the source is using a custom DNS.
Scenario 1: Source is using the default (Azure-provided) DNS
The default (Azure-provided) DNS can only be used by sources in Azure that have private endpoint, vNet integration, or have IPs defined from a vNet. If you are using the default DNS and you are getting a DNS issue, you need to check the following:
vNet of the source: Check the vNet of the source (also check NIC level configuration in case of Azure VM) and make sure that it is set to Azure-provided DNS. You can check this on the vNet > DNS servers blade, as shown in the following figure:
Fig 5: DNS servers blade in virtual network
Private DNS zone of the server: Go to the Private DNS zone of the MySQL Flexible server and add the vNet of the source to the Virtual Network Link blade, as shown in the following figure:
Fig 6: Adding virtual network link to private DNS zone
After these steps, you should be able to ping and nslookup the server’s name from the source and get the correct IP address.
Scenario 2: Source is using a custom DNS
This is the most commonly used scenario by the users. This pattern can be used in a hub-and-spoke model and also for name resolution from on-premises servers. In this scenario, a custom DNS server is deployed in a hub vNet that is linked to the on-premises DNS server. It can also be deployed without having on-prem connectivity, as shown in the following figure:
Fig 7: Network diagram showing access through custom DNS server in Hub and Spoke network.
In this scenario, the MySQL Flexible server is deployed in a delegated subnet in Spoke2. Spoke1, Spoke2, and Spoke3 are connected through the Hub vNet. Spoke1 and Spoke3 have a custom DNS server configured which is deployed in the Hub vNet. Since both spoke vNets (1 and 3) are connected through the Hub vNet, clients can directly connect with the MySQL Flexible server with IP address only and DNS name resolution would not work.
To fix this issue, perform the following steps:
Conditional forwarder: Add a conditional forwarder on the custom DNS for mysql.database.azure.com domain. This conditional forwarder must point to the Azure DNS IP address: 168.63.129.16, as shown in the following figure:
Fig 8: Adding conditional forwarder for mysql.database.azure.com
Virtual network link: You need to add a virtual network link in the Private DNS zone for the custom DNS server’s vNet, as described in the previous scenario.
On-premises DNS: If you have clients on-premises that need to connect to the Flexible server FQDN, then you need to add a conditional forwarder in the on-premises DNS server pointing to the IP address of the custom DNS server in Azure for mysql.database.azure.com. Alternatively, you can use the same custom DNS IP in additional DNS servers on on-premises clients.
Conclusion
In this blog, I have shown you how to solve DNS issues with Azure Database for MySQL using different DNS scenarios. I hope this helps you to enjoy the benefits of using Azure Database for MySQL for your applications.
We are always interested in how you plan to use Flexible Server deployment options to drive innovation to your business and applications. Additional information on topics discussed above can be found in the following documents:
“Help technical users who had problem installing update KB5034441 2024-01-09 “0x80070643 – ERROR_INSTALL_FAILURE” Workaround: It might be necessary to increase the size of the WinRE partition in order to avoid this issue and complete the installation.”
“The content in this repository is highly valuable for beginners, as it not only introduces the concepts of generative AI but also provides hands-on examples and code snippets to help users understand and implement the techniques. The lessons cover a wide range of topics, including language models, semantic search, transformers, and more, giving learners a holistic understanding of generative AI.
Moreover, the repository is actively maintained and has received significant community engagement, with over 23.6k stars and 15k forks. This level of community activity demonstrates the value and popularity of the content. Additionally, the presence of 50 contributors indicates a collaborative environment where users can benefit from the expertise and insights of others in the field.
I have personally found this content to be highly informative and well-structured, making it an ideal resource for individuals looking to explore generative AI. I believe that this repository will greatly benefit those who are new to the field and provide them with a solid foundation to build upon.
As an MVP, I have written a blog post discussing the significance of generative AI and its potential applications in healthcare. In the blog post, I have highlighted the “Generative AI for Beginners” repository as an excellent starting point for individuals interested in learning more about this field. I have shared practical examples and insights from the repository to showcase the practicality and versatility of generative AI in the healthcare domain.
Additionally, I have organized a virtual event for the local developer community, where I conducted a workshop using the lessons from the “Generative AI for Beginners” repository. The event aimed to introduce beginners to the world of generative AI and provide them with hands-on experience in building their own models. The event received positive feedback, with participants expressing their appreciation for the comprehensive and beginner-friendly content provided by Microsoft.”
“This is a content that compiles all the installation methods for implementing Microsoft 365 security and compliance, and can be used as a reference when writing work or blog articles. It is also a very useful content for planning and proposals, as it serves as a guideline for design and includes license information, which is helpful when planning the order of implementation and construction.”
(In Japanese: Microsoft 365のセキュリティ、コンプライアンスの実装についてすべての設置方法がまとまっており、仕事やブログ記事を書く際にリファレンス的に参照することが可能なコンテンツ。企画、提案の際にも設計の指針になり、ライセンス情報も同コンテンツに記載があるため導入構築順などを計画する際にも役立つ非常に有用なコンテンツ。)
“This is a valuable article that delves deeper into the Microsoft Global Network and provides an answer to the question, ‘Does this connection architecture connect to the internet or not?”
(In Japanese: Microsoft Global Network について一歩踏み込んで「この接続アーキテクチャはインターネットに出るのか否か」に答えを与えてくれる、ありがたい記事です。)
This article is contributed. See the original author and article here.
Power Platform and Low Code are a fast-growing practice area for many partners and we want to hear from you about how you are building and expanding this practice and the type of services you offer, so that we can share back broad trends and insights with the partner community.
We are currently conducting a survey to identify and define the value partners realize through their relationship with Microsoft and Power Platform. This research is being done by IDC’s Channels and Alliances Research Group on behalf of Microsoft. Please use this link to take the survey: https://aka.ms/PowerPartnerProfitabilitySurvey. It takes approximately 10-15 minutes and we recommend that it is completed by your Power Platform practice lead. The questions included are related to Microsoft and Power Platform revenue growth, profit across resale, services and/or software, investments in your Power Platform practice, and Microsoft activities/programs that drive success.
We’re interested in learning about your practice development and the profitability of your Power Platform business. The information you provide will be aggregated and used in an IDC eBook, and will help Microsoft improve its partner strategy and programs related to Power Platform.






















Recent Comments