by Contributed | Feb 8, 2021 | Technology
This article is contributed. See the original author and article here.
My name is Susan and a small group of us have joined together to provide you documentation on how to view a kernel filter driver in procmon on the stack, that is normally obfuscated. A special thanks to my colleague, Becky Burns for documentation collaboration; and a special shout out to Denis Pasos and Ron Stock for both creating a leaky kernel filter driver, and documentation collaboration.
Symptoms or Error
If you need to get Procmon’s filter to run below us in the filter stack, it has a setting for that. Procmon is typically used to figure out what is happening on the machine, but you do not get to see the activity of things such as virus scanners because they happen at a lower level than the procmon filter. In our case, we have a driver called Leakyflt.sys but in procmon it only shows as FLTMGR.sys but we want to know which driver it is without performing more tracing.
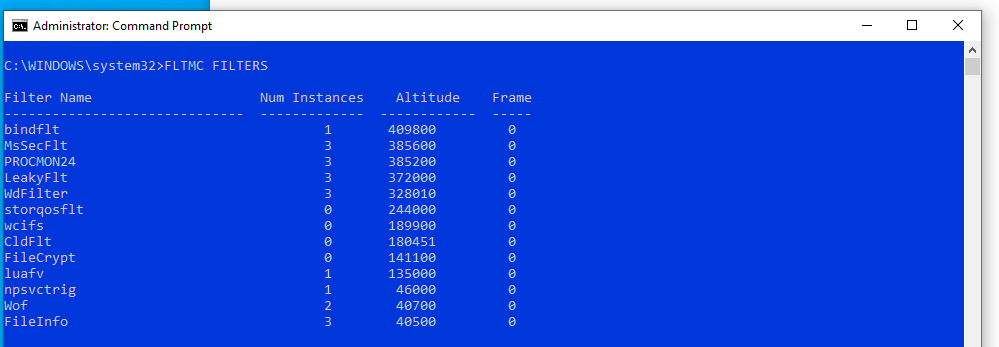
From an administrative command prompt, we see the driver LeakyFlt at altitude 372000:
In this example below, you will see Procmon’s altitude at 385200 as well as Legacy Filter Drivers such as vdorctl, and dgmaster:

From Procmon, in the stack it looks like

Solution
Changing the “Altitude” that procmon will run, putting it lower in the filter stack. In doing so, you will be able to see all the activity that you want from most filter drivers.
To change the altitude of procmon, you will want to perform the following steps:
- Install Procmon (assuming you have not already installed it) https://docs.microsoft.com/en-us/sysinternals/downloads/procmon
- From an Administrative Command prompt, run FLTMC to see the Altitude of the filter drivers:

In the screenshot, the lowest filter driver altitude is 37200
Open Registry Editor (RegEdit)
Navigate to registry key: HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesPROCMONXX
In Example: PROCMON24 (name may have a different number on your machine)

Expand to HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesPROCMONXXInstancesProcess Monitor XX instance. (i.e., Process Monitor 24 Instance)
- Change the Altitude Regkey value to lower than your lowest filter driver.
For this example: change the Altitude value to 40000 (which will show you virtually everything that is happening on the machine). Alternatively, you could set the altitude to 372000 if you suspected a specific driver.
Ex. Default altitude currently set to 385200

Right click on Altitude, change value to 40000, click OK


- You must also set the security on the “Process Monitor XX Instance” key and add deny rights for everyone for “delete” and “set value“. Reason being that procmon will try to change its value back right away. You will have to select “Disable inheritance” to be able to set them at the Process Monitor XX Instance level.
Right click on Process Monitor 24 Instance, select Permissions…

Click Add

In “Enter the object names to select:” type Everyone, click Check Names, then click OK.

Select Everyone, Click Advanced.

Select Everyone, click Edit.

Click Show advanced permissions.

Change Type: to Deny, check Set Value, check Delete, click OK.
(if Read Control is checked, uncheck it)

With Everyone highlighted, select Disable inheritance, click OK

Choose Convert inherited permissions into explicit permissions on this object.

Click OK.

Click Yes

Click OK

Exit Registry Editor

- If you have already started procmon before doing these changes, you will need to restart the machine. If not, you should be able to just start procmon.
From an elevated command prompt, run the command fltmc instances and verify that the procmon drivers are running at the altitude that you set (ex. 40000).

Then reproduce the scenario you want to capture. Your capture will be even larger than normal.
Notice now when we review the new procmon, and view Stack we see the name of the driver LeakyFlt.sys.
Note: You can leave the setting as it just lowers the threshold of what we see. And more is always better when it comes to legacy kernel drivers. Once you get a procmon with that enabled, you can look at the stack and see it.
Note 2: Will the deny permission for Everyone only impacts that instance? Will it not interfere with other applications/permissions on the machine?
It only affects that procmon instance; not all procmons. So, if they installed e.g., something that had their own procmon instance it would not impact it. You can take ownership of the key to delete the key when you are done.

by Scott Muniz | Feb 8, 2021 | Security
This article was originally posted by the FTC. See the original article here.
You might have seen that the President recently sent a new immigration bill to Congress. What does that mean for you if you’re a non-citizen in the United States? Right now, the truthful answer is likely nothing — at least not yet. But scammers won’t tell you that.
Instead, we’ve already heard about scammers trying to profit off this news by offering so-called immigration services in response to this immigration bill. Someone might say that they can help you with a new pathway to citizenship, or that they can help you can skip the line if you’re a farmworker or a Dreamer. In either case, for a fee.
But none of this is true. First, there is no new immigration law yet — at this point, it is just a proposal. Second, only notarios and dishonest attorneys will tell you they can help you get immigration status based on a bill. They are eager to charge you now for immigration help even though they know the bill may never become law.
This is what we know right now:
If you spot an immigration scam, report it to the Federal Trade Commission at ReportFraud.ftc.gov. You can report the scam anonymously or ask your attorney to report the scam with their contact information instead. Each report helps protect your community against immigration scams.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

by Contributed | Feb 8, 2021 | Technology
This article is contributed. See the original author and article here.
Welcome to part 2 of the four-part blog series on navigating Oracle to Postgres migrations. I am super stoked to let you know the first post in the series—announcing the new Oracle to Postgres migration guide for Azure—had 1000s of views and was featured in the 389th edition of the Postgres Weekly newsletter. I feel happy that many of you personally messaged me to let me know that the migration guide is helping your migration projects. Thank you for all the feedback.
Oracle to Postgres migrations are hard, multi-step projects—especially for complex applications. From my experience working with those of you who have already done an Oracle to Postgres migration—specifically migrations to our Azure Database for PostgreSQL managed service—many of you spend more than 60% of the entire migration project in the conversion (step 4) and migration (step 6) phases. In the first post in this Oracle to Postgres migration series, I dove deep into the different steps of an Oracle to Postgres migration. In the same spirit, let’s dive into some practical examples of how our Oracle to Postgres migration guide can help you migrate your database storage objects.
What are database storage objects?
Any object in a relational database that defines how data is stored, represented, and accessed is a database storage object. Database storage objects include: Schemas, Tables, Types, Constraints, Indexes, Sequences, Views, Synonyms, Database Links, etc. While each of these objects may mean different things in Postgres (compared to Oracle), it is important for you to know the best practices of migrating each of these objects from your Oracle database to Postgres.
In this post, you will learn about:
- Best practices to move some of these database objects, excerpted from the migration guide
- Some of my favorite examples of what to watch out for. I have burnt my fingers quite a few times when migrating a few of these database storage objects. I don’t want you to have to burn your fingers too.

The good news is that converting/migrating database storage objects from Oracle to Postgres is relatively easy compared to more complex DB objects such as packages, functions, procedures, etc. (typically known as DB code objects). One of the open source tools that we employ in Oracle to Postgres migrations is the wonderful Ora2Pg utility. If you’re not yet familiar, Ora2Pg is a free, open source tool used to migrate an Oracle database to a PostgreSQL compatible schema. Ora2pg does a great job in converting DB storage objects automatically and has improved a lot over the years to cater to different combinations of these storage objects. The key to a successful migration lies in understanding how to convert these database storage objects, knowing why Ora2pg does conversions in a certain way, and ensuring that your converted workload works optimally in Postgres.
What is the deal with schemas in Oracle vs. Postgres?
Let’s dive into an example right away. In Oracle, users and schemas are essentially the same thing. When you create a user (using the “create user” command), Oracle also creates a schema container to hold all objects that user creates. Whereas in Postgres, all objects created by a user need to be explicitly created in a schema within the database. All Postgres users are global to the entire server by itself. This blog post on schemas in Oracle vs. Postgres depicts this difference well.
You’re essentially going from –
|——————————————|
| Oracle server |
|——————————————|
| Database 1 | Database 2 | DATABASE
|———————|———————|
| User 1 | User 2 | User 1 | User 2 | USERS/SCHEMAS
|———-|———-|———-|———-|
| t1,t2,t3 | t1,t2,t3 | t1,t2,t3 | t1,t2,t3 | TABLES
——————————————-
TO
|————————————————–|—|
| PostgreSQL instance | |
|————————————————–| U |
| Database 1 | Database 2 | S |
|————————-|———————— | E |
| Schema 1 | Schema 2 | Schema 1 | Schema 2 | R |
|————|————|————|————| S |
| t1,t2,t3 | t1,t2,t3 | t1,t2,t3 | t1,t2,t3 | |
————————————————-
The top things to consider when going through database level changes (such as the schema example above) are:
- Would your front-end application work with changes described above? If not, what would you need to change? Some apps are interfaced with an ORM layer that make these database/schema level changes easy to take in. You may need to rearchitect some apps to work with this paradigm shift.
- With these types of database level changes, are you going to get the required performance you need from the app and meet your SLAs? This is almost always answered via thorough testing at the end of the conversion exercise. Eventually, it also makes sense to test the entire stack once data migration is complete as well.
Bottom line, the schema-based semantics are quite different between Oracle and Postgres. So, you have to figure out whether your app is going to work as expected with a different schema, or whether you need to make some adjustments in your application. Don’t worry, though—catching these differences and implementing them are very easy once you get a hang of it.
Given schemas and users are the same thing in Oracle, there are multiple gotchas to take care of. All these gotchas with examples like above are given in the chapter on “Migrating from Oracle Security Model” in page 61 of the Oracle to Postgres migration guide.
A fun story on numeric vs. BIGINT
When it comes to migrating tables, data type differences between Oracle and PostgreSQL take up a lot of mindshare. Before I tell you where to find specifics on table partitioning, migrating index organized tables, etc. from Oracle, let me walk you through a practical experience with data types to show you how important testing each conversion is.
Oracle has a very rich set of number related data types (think INT, DOUBLE, FLOAT etc.) with an ability to store scale and precision. However, when querying the Oracle dictionary tables to get details on data types for each table column, Oracle stores each of these numeric subtypes as a NUMBER with appropriate scale and precision. Sometimes, irrespective of what the subtype is, these columns get converted to numeric during the conversion process.
Well, here is the kicker. In Oracle, the largest number data type holds 38 digits. In Postgres, the largest numeric datatype can hold 131,072 digits. If you don’t follow the tips and best practices in the Oracle to Postgres migration guide—and if the primary key index on this number column in Oracle is translated to a numeric in Postgres—you will pay a performance penalty in Postgres. The good news is, the data type migration best practices in the “Data type conversions” section of our Oracle to Postgres migration guide will help you avoid gotchas like this.
Experiment with Numeric types
Let’s do an interesting experiment to see the impact of creating an index on a numeric column vs. a BIGINT column in Postgres. In the example below, I am creating 2 two-column tables, one with the ID set to numeric and the other with ID set to BIGINT. I am inserting 1M rows in each and comparing how long it takes to do a self-join count on both.
CREATE TABLE public.arthiaga_numeric(id numeric NOT NULL, name character varying(200));
#Insert 1M rows
INSERT INTO public.arthiaga_numeric(id, name)
SELECT generate_series(1,1000000), md5(random()::text);
INSERT 0 1000000
Query returned successfully in 3 secs 585 msec.
#Add primary key
ALTER TABLE public.arthiaga_numeric ADD PRIMARY KEY(id);
ALTER TABLE
Query returned successfully in 1 secs 262 msec.
#Do a self-join count
select count(*) from public.arthiaga_numeric a, public.arthiaga_numeric b where a.id=b.id;
Successfully run. Total query runtime: 1 secs 123 msec.
Experiment with BIGINT
CREATE TABLE public.arthiaga_bigint(id bigint NOT NULL, name character varying(200));
#Insert 1M rows
INSERT INTO public.arthiaga_bigint(id, name)
SELECT generate_series(1,1000000), md5(random()::text);
INSERT 0 1000000
Query returned successfully in 3 secs 710 msec.
#Add primary key
ALTER TABLE public.arthiaga_bigint ADD PRIMARY KEY(id);
ALTER TABLE
Query returned successfully in 1 secs 107 msec.
#Do a self-join count
select count(*) from public.arthiaga_bigint a, public.arthiaga_bigint b where a.id=b.id;
Successfully run. Total query runtime: 1 secs 3 msec.
For a million-row table with two basic columns, you already see an 11% improvement in query response times when I create an index on a BIGINT column as opposed to a numeric column in PostgreSQL. As you can see –
Count query with BIGINT for a 1M row table
|
Completes in 1.003 seconds
|
Count query with NUMERIC for a 1M row table
|
Completes in 1.123 seconds
|
Imagine the performance penalties you will need to pay for larger and more complex table structures. Imagine the end-to-end performance impact when query response times are high across multiple tables in a workload. I would encourage you try this experiment on larger and more complex tables to see bigger performance gains yourself. For certain workloads, we have measured very high improvements in query response times (north of 80%) by just switching to use the right data type in Postgres.
The key thing to know is, from a table migration standpoint, you should keep an eye on data types, partitioning schemes, indexes, constraints, LOBs, temporary tables, sequences etc. when migrating from Oracle to Postgres. You can learn about all of these aspects in the Oracle to Postgres migration guide.
Next up, let’s look at a couple more of my most favorite learnings based on my experience with migrating DB storage objects in Oracle to Postgres migrations.
NULLs in Postgres, anyone?
Postgres handles NULLs in strings in a completely different way compared to Oracle—period! I highly recommend paying attention to and updating your SQL queries to cater to subtle differences in the treatment of NULLs. To avoid last-minute issues during cutover phases, you’ll definitely want to test (and test, and test) earlier in the process. If you’re migrating from a typical Oracle workload, there is a high chance you will hit this issue in the way Oracle treats NULLs in strings vs. Postgres. Let’s look at an example.
Let’s use the same table created above for this experiment. I will just remove the primary key and add a composite unique constraint to one of the tables above to keep the explanation simple.
CREATE TABLE public.arthiaga_bigint(id bigint NOT NULL, name character varying(200));
#Add composite unique constraint across columns
alter table public.arthiaga_bigint add constraint uniq_bigint unique (id, name);
#Insert more rows
INSERT INTO public.arthiaga_bigint(id, name) VALUES (1, 'Arun');
INSERT INTO public.arthiaga_bigint(id) VALUES (2);
INSERT INTO public.arthiaga_bigint(id) VALUES (2);
INSERT INTO public.arthiaga_bigint(id) VALUES (3);
INSERT INTO public.arthiaga_bigint(id) VALUES (3);
#Table select
select * from public.arthiaga_bigint;
 Figure 1: Non-uniqueness in PostgreSQL due to NULLs.
Figure 1: Non-uniqueness in PostgreSQL due to NULLs.
Guess what the select returns, despite the unique constraint?
- The duplicate inserts in Oracle will fail, given that Oracle supports null comparison.
- In Postgres, two nulls aren’t the same, and hence despite the unique constraint, the duplicate insert goes through without issues.
As a result, when you’re migrating to Postgres, you will need to handle such exceptions in your application. And if you don’t handle these exceptions in your app, you are in for a lot of surprises.
The same point is applicable for NULLs within strings as well: Postgres does not support NULLs within strings, whereas Oracle does.
Sequence caching in Postgres vs. Oracle
Oracle shares a sequence cache across multiple user sessions in the database. In PostgreSQL, the sequence cache is not shared across session and is instead at a per session level.
This blog post on explaining sequence caching behavior differences in Oracle vs. Postgres does a great job on showing this behavior via an example. In the example, any new session in Postgres will get its own set of cached values for a particular sequence range. Whereas in Oracle, sequences are shared across sessions. If your application depends on shared cache values for sequences, it would be good to think about changing the design in the app itself given this difference.
While these are just a few examples based on my experience, the Oracle to Azure Database for PostgreSQL migration guide covers database storage object conversion topics in depth.
Cheat sheet: where to find info about database storage objects in the migration guide
This cheat sheet on where to find details about database storage objects in our Oracle to Postgres migration guide should be useful:
- Data type conversions, with best practices – starting page 241.
- Partitioning schemes – starting page 198.
- Indexes – starting page 294.
- Constraints – starting page 184.
- LOBs – starting page 223.
- Temporary tables – starting page 171.
- Sequences – starting page 252.
- Tablespaces – starting page 76.
- User-Defined types – starting page 270.
As you can see, this guide has a LOT of content and is improved frequently. While these page numbers can change in a future version of this guide, you can still search for the chapters listed above.
If you’re looking to migrate from Oracle to Postgres, some links & resources
Now that you have:
- seen what the migration journey looks like in part 1 of this Oracle to Postgres blog series and
- gotten a rundown of migrating database storage objects to Postgres in this part 2 blog post
you might want to also check out the Oracle to Azure Database for PostgreSQL migration guide. Let me know if it’s useful. And especially let me know if you see ways to make it even more useful.
If you want to chat about migrations to PostgreSQL in general—or have questions about our PostgreSQL managed service on Azure—you can always reach our product team via email at Ask AzureDB for PostgreSQL. I also love all the updates on our Twitter handle (@AzureDBPostgres) and recommend following us for more Postgres news and updates. We would love to hear from you.
Happy learning. 






Recent Comments