by Contributed | Feb 21, 2021 | Technology
This article is contributed. See the original author and article here.
Hi,
Recently, I built the Azure Solution Architect Map , the Azure Security Architect Map and the Azure Infrastructure Architect Map aimed at helping Architects finding their way in Azure. Here are all the maps in my series of Architecture Maps:
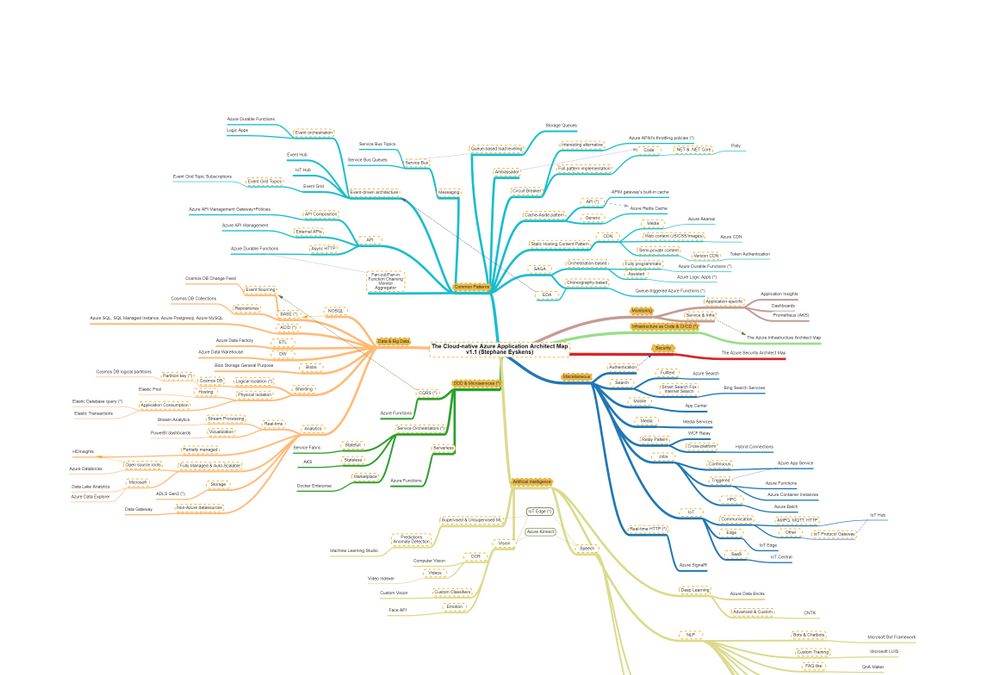
I’m now coming with the next map in this series, namely: the Cloud-native Azure Application Architect Map.
As usual, this map is by no means the holy grail and is just there to highlight some good fit between Azure Services and Design Patterns. This map is certainly subject to controversy as they are thousands of ways to design and develop and application. My goal is only to highlight some possibilities.
As usual, here is a screenshot of the map:

The map focuses on the following areas:
- Data & Big Data
- Common Design Patterns: SAGA, Circuit Breaker, Event-driven Architecture, etc.
- Domain-driven Design & Microservices: yes I clubbed them together :)
- Artificial Intelligence: NLP, Supervised & Unsupervised ML etc.
- Miscellaneous: things that come back regularly when developing applications such as real-time HTTP, search, job scheduling etc.
How to read this map?
Whenever you see the attachment icon  , it means that I have attached an explanation on a given rationale or service. If you see a (*) next to a node, it is kind of a must read information. So for instance, in the following screenshot:
, it means that I have attached an explanation on a given rationale or service. If you see a (*) next to a node, it is kind of a must read information. So for instance, in the following screenshot:

I want to catch your attention on why I make an association between DDD and Microservices:

as well as why I make an association between CQRS and DDD:

You might of course disagree with this but at least, you understand my rationale.
The link icon  is a pointer to the corresponding Microsoft documentation.
is a pointer to the corresponding Microsoft documentation.
Note that I haven’t dived into AKS or Service Fabric since this guys would deserve a dedicated map and are not Azure services like others, they are a universe by themselves.
With this tool, any Cloud-native Application Architect should quickly grasp the application landscape of Azure.
Update: the online MindMapMaker tool deletes maps that are older than a year, therefore, just visit the last version.
Here are all the maps in my series of Architecture Maps:
by Contributed | Feb 21, 2021 | Technology
This article is contributed. See the original author and article here.
Initial Update: Sunday, 21 February 2021 16:32 UTC
We are aware of issues within Log Search Alerts in Australia Southeast region and are actively investigating. Some customers may experience delayed or missed Log Search Alerts.
- Work Around: None
- Next Update: Before 02/21 19:00 UTC
We are working hard to resolve this issue and apologize for any inconvenience.
-Jeff

by Contributed | Feb 20, 2021 | Technology
This article is contributed. See the original author and article here.
In my day to day, I get to work with many customers migrating their data to Postgres. I work with customers migrating from homogenous sources (PostgreSQL), and also from heterogenous database sources such as Oracle and Redshift. Why do people pick Postgres? Because of the richness of PostgreSQL—and features like stored procedures, JSONB, PostGIS for geospatial workloads, and the many useful Postgres extensions, including my personal favorite: Citus.
A large chunk of the migrations that I help people with are homogenous Postgres-to-Postgres data migrations to the cloud. As Azure Database for PostgreSQL runs open source Postgres, in many cases the application migration can be drop-in and doesn’t require a ton effort. The majority of the effort usually goes into deciding on and implementing the right strategy for performing the data migration. For those of you who cannot afford any downtime during the Postgres migration process, there are of course data migration services that can help. But if you can afford some downtime for the migration during a specific maintenance window (e.g. during weekends, nights, etc.), then simple Postgres utilities such as pg_dump and pg_restore can be used.
In this post, let’s walk through the tradeoffs to consider while using pg_dump and pg_restore for your Postgres database migrations—and how you can optimize your migrations for speed, too. Let’s also explore scenarios in which you need to migrate very large Postgres tables. With large tables, using pg_dump and pg_restore to migrate your database might not be the most optimal approach. The good news is we’ll walk through a nifty Python tool for migrating large database tables in Postgres. With this tool we observed the migration of a large Postgres table (~1.4TB) complete in 7 hrs. 45 minutes vs. more than 1 day with pg_dump/pg_restore.
Faster migrations with pg_dump & pg_restore
pg_dump is a standard and traditional utility for backing up a PostgreSQL database. pg_dump takes a consistent snapshot of your Postgres database, even if the database is being actively used. pg_dump gives you multiple command-line options (I call them flags) that you can use to control the format and the content of the data you’re backing up. Some of the common and most useful command-line options for pg_dump enable you to do things like:
- Fine-grained control of dumping specific schemas, specific tables, just the data, etc.
- Control of the format of the dump; options include plain-text or the custom or directory formats, which are compressed by default.
- Using the
–jobs/-j command line option, which provides the ability to specify the number of concurrent threads to use for the dump. Each thread dumps a specific table, and this command line option controls how many tables to dump simultaneously.
You can use the pg_restore utility to restore a PostgreSQL database from an archive created by pg_dump. Similar to pg_dump, pg_restore also provides a lot of control over how you restore the archive. For example, you can restrict the restore to specific database objects/entities, specify parallel jobs for the restore, and so on.
TIP: Place the client machine on which you perform pg_dump/pg_restore as close as possible to the source and the target database, to avoid performance issues with bad network latency. If only one of the two is possible, you can choose either. Just be sure to place the client machine as close as possible to the target database, or the source database, or both.
In summary, pg_dump and pg_restore are the most commonly used, native, robust, and proven utilities for homogenous (Postgres to Postgres) database migrations. Using these utilities is the default way to perform data migrations when you can afford downtime (within some acceptable maintenance window).
With the wealth of command-line options that pg_dump and pg_restore provide, it is important to use those options in an optimal way based on the scenario at hand. Let’s walk through some of the scenarios you may face, to understand how best to use pg_dump and pg_restore.
What if you need to migrate more than 5 large Postgres tables?
Suppose your Postgres database has multiple (say, more than 5) decently-sized (greater than 5GB) tables. You can use the -j flag to specify the number of threads to use when performing a pg_dump and pg_restore. Doing so not only maximizes resource (compute/memory/disk) utilization on the source and target servers, but it also scales the available network bandwidth. (However you should be cautious that pg_dump and pg_restore don’t become network hogs and don’t affect your other workloads.) Thus, using pg_dump and pg_restore can provide significant performance gains.
If you’re performing an offline migration with no other load on the Postgres servers, you can specify that the number of jobs is a multiple of the number of cores in the system, which will maximize compute utilization on servers. However, if you’re performing a dump/restore just for backup/restore reasons on servers that have production load, be sure to specify a number of jobs that doesn’t affect the performance on the existing load.
You can use directory format (-Fd), which would inherently provide a compressed dump (using gzip). We have sometimes seen over 5X compression while using the -Fd flag. For larger databases (e.g. over 1 TB), compressing the dump can reduce the impact of disk IOPs getting bottlenecked on the server from which you are capturing a dump.
Below are sample pg_dump and pg_restore commands that use 5 jobs for the dump and restore respectively:
pg_dump -d 'postgres://username:password@hostname:port/database' -Fd -j 5 -f dump_dir
pg_restore --no-acl --no-owner -d 'postgres://username:password@hostname:port/database' --data-only -Fd -j5 dump_dir
How to migrate if most of your tables are small, but one of your tables is very large?
Suppose your database has a single large table (over 5GB) while the rest of the tables are small (less than 1 GB). You can pipe the output of pg_dump into pg_restore so you needn’t wait for the dump to finish before starting restore; the two can run simultaneously. This avoids storing the dump on client which is a good thing, since avoiding storing the dump on the client can significantly reduce the overhead of IOPs needed to write the dump to the disk.
In this scenario, the -j flag might not help because pg_dump/pg_restore run only a single thread per table. The utilities will be throttled on dumping and restoring the largest table. Also, unfortunately, when you use the -j flag, you cannot pipe the output of pg_dump to pg_restore. Below is an example command showing the usage:
pg_dump -d 'postgres://username:password@hostname:port/source_database' -Fc | pg_restore --no-acl --no-owner -d 'postgres://username:password@hostname:port/target_database' --data-only
The techniques in the above 2 sections can drastically improve your data migration times with pg_dump and pg_restore, particularly when one or more large tables are involved. In addition, this post about speeding up Postgres restores walks through similar techniques and gives you step-by-step guidance on how to achieve ~100% performance gains with pg_dump/pg_restore. This is one of my favorite Postgres blogs on pg_dump and pg_restore, hence sharing for reference. 
pg_dump/pg_restore is single threaded at a single table level, which can slow down migrations
Even when you use the above optimizations, since pg_dump and pg_restore can use only a single thread each when migrating a single table, the entire migration can get bottlenecked on a specific set of very large tables. For databases over 1 TB with a couple of tables representing majority of the data, we’ve seen pg_dump and pg_restore take multiple days, which leads to the following question.
How can I use multiple threads to migrate a single large table in PostgreSQL?
You can leverage multiple threads to migrate a single large table by logically chunking/partitioning the Postgres table into multiple pieces and then using a pair of threads—one to read from source and one to write to the target per piece. You can chunk the table based on a watermark column. The watermark column can be a monotonically increasing column (e.g., id column) (OR) a timestamp column (e.g., created_at, updated_at, etc).
There are many commercial tools out there that implement the above logic. In the spirit of sharing, below is a Python script, called Parallel Loader, that is a sample implementation of the above logic. You can find the Parallel Loader script on GitHub if you want to use it yourself.
#suppose the filename is parallel_migrate.py
import os
import sys
#source info
source_url = sys.argv[1]
source_table = sys.argv[2]
#dest info
dest_url = sys.argv[3]
dest_table = sys.argv[4]
#others
total_threads=int(sys.argv[5]);
size=int(sys.argv[6]);
interval=size/total_threads;
start=0;
end=start+interval;
for i in range(0,total_threads):
if(i!=total_threads-1):
select_query = '"COPY (SELECT * from ' + source_table + ' WHERE id>='+str(start)+' AND id<'+str(end)+") TO STDOUT"";
read_query = "psql "" + source_url + "" -c " + select_query
write_query = "psql "" + dest_url + "" -c "COPY " + dest_table +" FROM STDIN""
os.system(read_query+'|'+write_query + ' &')
else:
select_query = '"COPY (SELECT * from '+ source_table +' WHERE id>='+str(start)+") TO STDOUT"";
read_query = "psql "" + source_url + "" -c " + select_query
write_query = "psql "" + dest_url + "" -c "COPY " + dest_table +" FROM STDIN""
os.system(read_query+'|'+write_query)
start=end;
end=start+interval;
How to invoke the Parallel Loader Script
python parallel_migrate.py "source_connection_string" source_table "destination_connection_string" destination_table number_of_threads count_of_table
With the Parallel Loader script, you can also control the number of threads used for migrating the large table. In the above invocation, the number_of_threads argument controls the parallelism factor.
Example invocation of the Parallel Loader Script
python parallel_migrate.py "host=test_src.postgres.database.azure.com port=5432 dbname=postgres user=test@test_src password=xxxx sslmode=require" test_table "host=test_dest.postgres.database.azure.com port=5432 dbname=postgres user=test@test_dest password=xxxx sslmode=require" test_table 8 411187501
The above implementation uses the monotonically increasing id column of a table to chunk it out and stream data from the source table to the target table using parallel threads. You can find some pre-requisites and recommendations for using Parallel Loader on this GitHub repo.
Comparing performance of Parallel Loader vs. pg_dump & pg_restore, for large Postgres tables
To compare the performance of pg_dump and pg_restore to the Parallel Loader script, I migrated a 1.4 TB Postgres table (with indexes) from one Postgres database to another in Azure in the same region, using both techniques.
You can see in the table below that the Parallel Loader script performed over 3X faster than pg_dump and pg_restore for this Postgres to Postgres data migration.
|
Parallel Loader
|
pg_dump & pg_restore
|
Time to migrate 1.4TB Postgres database (with indexes) in same Azure region
|
7 hours 45 minutes
|
> 1 day
|
 Figure 1: We observed a network throughput of ~9.5GB every 5 minutes for the migration, peaking at 27.9GB per 5 minutes.
Figure 1: We observed a network throughput of ~9.5GB every 5 minutes for the migration, peaking at 27.9GB per 5 minutes.
Parallel Loader uses the COPY command for faster performance
Note that Parallel Loader uses the COPY command across each thread for reading data from the source and writing data to the target database. The COPY command is the best way for bulk ingestion in Postgres. We have seen ingestion throughputs of over a million rows per second with the COPY command.
 Figure 2: Screenshot that shows the activity (pg_stat_activity) consisting of COPY commands on the target database. These COPY commands are generated by the Parallel Loader script while migrating a large table. Each COPY command translates to a single thread generated by the script.
Figure 2: Screenshot that shows the activity (pg_stat_activity) consisting of COPY commands on the target database. These COPY commands are generated by the Parallel Loader script while migrating a large table. Each COPY command translates to a single thread generated by the script.
Bottom line: you can use pg_dump/pg_restore in conjunction with Parallel Loader for faster Postgres data migrations
The pg_dump/pg_restore utilities are fantastic tools for migrating from a Postgres database to another Postgres database. However, they can drastically slow down when there are very large tables in the database. To solve that problem, you can use the approach explained in this post: to parallelize single large table migrations to Postgres by using the Parallel Loader script. We’ve seen customers use a combination of Parallel Loader and pg_dump/pg_restore to successfully migrate their Postgres databases. Parallel Loader can take care of the large tables while pg_dump/pg_restore can be used to migrate the rest of your Postgres tables.
More useful data migration resources:
by Contributed | Feb 20, 2021 | Technology
This article is contributed. See the original author and article here.
What do you see when you look up at the stars?
Pinholes of light in an endless canvas? A ribbon of constellations? Or a sea of enticing destinations and mysteries to explore?
If you’re an explorer at heart, you’re in luck.
More spacecraft are lifting off than ever before, and we’re collecting data from farther and farther away. As the industry continues to shift and adapt with new technologies, this is the perfect time to consider a career in space exploration. In fact, Microsoft recently launched Azure Space to extend the capabilities of Azure beyond the stratosphere and use insights from space discovery to solve our biggest problems here at home.
Find your flight path
If you’re thinking really big now, awesome. Chart a course for your interstellar success with introductory, self-paced paths and modules on Microsoft Learn. Consider them early missions in an ongoing journey and prepare yourself for launch.
“I think that being a developer is an essential literacy skill—just like reading, writing, and math—that everyone should be exposed to and have the option to integrate into the things that they’re passionate about. Our space-themed Microsoft Learn paths were created for learners just like you, to inspire you to take your ideas beyond what you thought was possible and apply what you learn to whatever you love.”
Dr. Sarah Guthals
Principal Program Manager, Azure Education
|
Mission 1: Discover the role of Python in space exploration
Take your first giant leap with an introduction to Python and its role in the solutions that NASA creates. Get to know the programming tools that you’ll use, learn and practice core programming concepts, and get more familiar with machine learning and AI. Along the way, you’ll hear experiences and advice from actual NASA employees.
Mission 2: Learn how to predict rocket launch delays with machine learning
If you’ve completed your first mission, installed Python and Microsoft Visual Studio Code, and are able to code simple programs in Python, you’re ready to dive into machine learning. Solve a real-life challenge that NASA faces before a launch and see how machine learning can help with other related issues in space discovery.
Mission 3: Learn how to use Python and AI to classify space rocks
Once you have a basic understanding of how Python is used for data science and machine learning, go deeper and learn how to create an AI model that can classify the type of space rock in a random photo.
Mission 4: Plan a mission to the Moon and bring some space rocks home
Now you’re really taking off. Learn how to prepare data for analysis, represent it clearly, and explore it using Python and pandas. Can you get your rocket to the Moon and bring it back full of space rocks?
Test the limits of AI with Bugs and the gang
If you’re mentoring younger students or teaching them about computer science and AI, check out the Space Jam: A New Legacy coding workshops. In these online workshops inspired by the upcoming movie, students aged eight and older learn how to build a playable prototype of a video game and explore careers in game design.
If you’re using the workshop to teach, take your lesson further with the educator resources in the Microsoft Store Space Jam: A New Legacy curriculum. However, these workshops are also a great way to help any curious kid in your life learn more about what you do and get them excited to try their own project.
And, let’s be honest, sometimes the stuff that’s made for kids is pretty fun for us too. ;)

by Contributed | Feb 20, 2021 | Technology
This article is contributed. See the original author and article here.
Val Verde school district in Southern California has been a pioneer in education for more than two decades.
One of the first districts on the internet in Southern California and one of the first 10 Google Certified schools, Val Verde has always been at the forefront of the future. They’ve been diving into new technology since acquiring a fleet of freshly released NeXT workstations in 1985.
Home to 20,000 students across 22 schools, Val Verde’s been a Microsoft-centric shop for the last 15-20 years but also dove into Google and Chromebooks early on.
Today, their district is a hybrid of Microsoft Office 365 for admin and teaching staff, with Chromebooks and G Suite for students who have been one-to-one with Chromebooks district-wide for the last two and a half years.
So it makes sense that Val Verde were super early adopters of Microsoft 365 Universal Print for an entire school district.
Leading the charge into the Universal Print beta were Matt Penner, Director of Information and Instructional Technology, and Brian Falk, Network Service Manager: Val Verde’s two futurists with over 20 years of IT experience.
An opportunity presented by remote working
When the uncertainty of a global pandemic hit, Val Verde was well poised to transition to a remote working setup for their staff and teachers. One wrinkle was how Matt and Brian’s IT team could support printing for the Microsoft-centric Val Verde business and teaching staff with their on-premises server set-up. Printing was a breeze for the students on Google and Chromebook, but those using Microsoft couldn’t access the on-premises print infrastructure.
It was a speedbump, but Matt and Brian smelled opportunity: “Our grand vision — this has been several years in the making — is that you can work on anything you want, wherever you want, anytime you want,” says Matt.
Backed by a likewise visionary superintendent, last year Matt and Brian were able to roll out 980 laptops completely on Azure during their school district’s Covid-19 closure.
“We’ve been moving everything to the cloud,” says Matt. “Managing it all through Azure. Our goal is to put all of our servers in Azure.”
Farming a multi-site data network up to the cloud
What makes a vision a vision is how insurmountable it may seem, which was the case for Brian. The central head of network solutions responsible for all of Val Verde’s dozens of schools and thousands of students, Brian only had three IT engineers on his team and no CISO. Supporting their entire district remotely while delivering security and efficiency meant tasks such as swapping hard drives because the SCSI board failed needed to quickly become a thing of the past.
“We are no longer in the data center game,” says Matt. “That is not our core value expertise. Our expertise is school districts and we’ll take PaperCut, Laserfiche, Azure, Google, and 20,000 Chromebooks and make them all work together because that’s what we’re good at.”
“So let’s farm that up to Azure. Just the simple cost, too, of DR and everything else. We’ve got all that, but that’s not where the value-add is. Not when Microsoft and some of these other companies can do it much better and at much better efficiencies of scale than we can.”
A plan that was years in the making
Just 12 months ago, moving from on-premises to cloud on such a large scale for a multi-site school district wasn’t on a lot of radars. “Nobody was looking at this, says Brian. “And I think the pandemic started changing some mindsets.”
Fortunately for Brian, Matt, and Val Verde, they had already begun changing their mindset before their district’s closure.
“Matt and I have had this discussion for almost three years about how we were going to move to the cloud, how we were going to get disassociated from our local networks. The pandemic, for us, has just been the catalyst to make that happen so much quicker.” – Brian Falk
Brian states the realization to enact their vision was instant: “On March 13th (2020) when we were all sent home due to the pandemic, we found that those physical devices were a huge hindrance to us and caused us all sorts of problems.” “Having to have that local Active Directory that nobody could access anymore, having to have those local file servers that nobody could access anymore, having those printers that just sat there and became stagnant because they were not accessible. We had to then enact the plan that we’d been looking at. We started enacting it almost immediately.”
Matt and Brian didn’t look to their own field for inspiration, they looked to corporate enterprises like Netflix and Amazon and followed their blueprint, rather than what others were doing in education. “I don’t think there’s a lot of people looking to do this,” says Matt on jumping into the Universal Print beta. “We’re hearing from Microsoft, ‘You’re like the only district in California who’s doing this’.” But it’s not about being lured to the bleeding edge by a shining lure: “We just like to push the envelope in a way that makes sense, that’s sustainable.”
Printing in the cloud with Microsoft and PaperCut
The announcement of Microsoft’s Universal Print was timely for Brian, as their print network was an additional pain-point during their closure: “Suddenly we have all these Azure devices that are trying to talk to on-prem printers in a classic, old print server traditional way.”“As we came into the pandemic we started testing on our Azure deployment, and we started seeing that there were some real challenges to trying to print the old-fashioned way, using the traditional print servers and being able to connect and talk to our printing. So we started digging to see what was out there and, of course, Universal Print popped up.”
Matt and Brian had already been managing their printing for tracking and reporting with PaperCut since 2016. The memory of successfully setting up cloud printing so easily for their superintendent’s Google Pixelbook came into play when they were looking into Universal Print: “I remember Matt and I were sitting in a meeting and we started Googling some stuff on Universal Print,” says Brian. “Right there on Universal Print’s page was a list of solution providers they were working with and there was PaperCut. We remembered the Google issue and the Google printing and we’re like, ‘If PaperCut made that so simple, then this was going to be easy with them as well.’
”Jumping into the Universal Print beta immediatelyWaiting patiently since Universal Print was announced, Brian says the pair leaped the second it was available for their licensing level: “It released, and within a day we were into the beta.”
“Within the first couple of hours we had the PaperCut connector downloaded and we were starting to work there,” says Brian. What they really appreciated was the immediate support from Microsoft and PaperCut: “Something that is the greatest part is when you’re sitting there and you’re dealing with a beta and they say, ‘Hold on, let’s get the developers on.’”
Living the cloud printing vision free of the old ‘magic network’ and VPNs
After that, the implementation was a breeze: “It went so smooth. We put in over fourteen hundred printers that we uploaded into Universal Print and we did it in batches. We didn’t want to do fourteen hundred printers all at once. But I think in the period of one week we had fourteen hundred printers into Universal Print.“

With Microsoft’s Universal Print and PaperCut, Brian states that Val Verde’s staff are now living their vision of being on a magic network, with their printing needs spoken for as well: “That teacher needs to print off ten lesson plans and they’re at home. They print off the ten lesson plans and whoever is in the office, picks them up for them and they’re done. It’s so easy.”
The risk of being a visionary is if you’re traversing unexplored territory, who knows when you might step into quicksand and begin floundering. That’s where the difference-maker was with Universal Print and PaperCut, despite being in beta: “To have direct access into your development team was amazing,” says Brian. “We kind of look at ourselves with this little school district out in the middle of nowhere. And here you guys are saying, ‘Yeah, we’ll talk with you. We’ll work through this with you.’”
Universal Print’s general availability is right around the corner and will be a part of Microsoft 365 enterprise and education and Business Premium. Add PaperCut in the mix and you unlock new print management powers – like full tracking and feature-packed print release. Microsoft 365 customers who would like to try Universal Print now in their organizations can start at https://aka.ms/up_trynow.
Find out more about PaperCut’s Microsoft Universal Print Connector


Recent Comments