by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.
Hello readers,
Bruno Gabrielli here again and today I want to welcome you on the Making Azure Data Explorer Queries More Efficient – Part 2.
In Making Log Analytics Queries More Efficient – Part 1 I started discussing about one of the most common scenario with customer’s created queries: query performance also referred as query speed or query efficiency. in the same post, I quickly introduced/covered concepts such as:
Today I would like to go more in depth spreading the word from , Principal Program Manager in the Azure Monitor, about query performance DOs and DONTs.
First and foremost, let me re-emphasize the importance of early filtering out your record by time. This will make your queries faster every time and in any case. As an additional note I would like to underline that with small datasets you might not see such a big performance improvements. Running poor written queries on datasets with more than 100M records is where you hit performance issues.
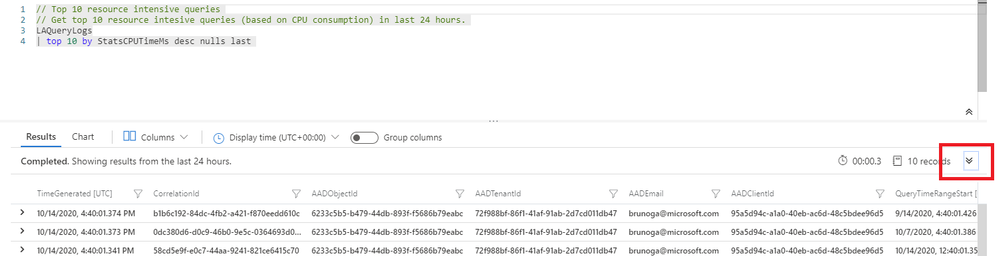
Second, I would like to focus your attention on a built-in feature about query performance awareness: the Query performance pane. This feature is embedded in the Log Analytics portal and it is giving you the statistics for any single query you run from there. You can access it directly from the query result pane by clicking the down arrow:

This expands the corresponding panel containing lots of very useful and important info such as below:

Then, let’s move on with something important about using string operators in your queries. The list of available string operators is huge, but there are a couple of things to remember:
- All operators which use has (has_cs, has_any, hassuffix, etc), search on indexed terms of four or more characters, and not on substring matches. A term is created by breaking up the string into sequences of ASCII alphanumeric characters.
- For better performance, when there are 2 operators that do the same task, DO use the case-sensitive version:
- DO use == instead of =~.
- DO use in instead of in~.
- DO use contains_cs instead of contains.
With all the above said, for faster results, if you’re testing for the presence of a symbol or alphanumeric word that is bound by non-alphanumeric characters, or the start or end of a field, DO use has, has_any or in. has and has_any work faster than contains, startswith, or endswith and can give you much more performance improvements.
If you really need to perform case-insensitive comparisons, DONT use tolower(Col) == “lowercasestring“. DO use the =~ Kusto operator in this case.
The 2 images below, show the same query. The first one is about using the recommendations above:

The second one is about not:

Next one is about using values contained in collected fields. The recommendation here is to materialize the given column at ingestion time whenever possible. Think about the case of custom ingestion using HTTP Data Collector API. Creating the specific field(s) with the necessary value(s), will make you pay only once for the extraction.
The following is a part of a PowerShell script that I created for testing the HTTP Data Collector. You can clearly see that at lines 63 I am parsing the Organizational Unit ($ouResult variable) that I DO later use at line 65 as materialized field value:

Moving on, what about analyzing or manipulating the same data/value(s) more than once in the same query? DO use the materialize() function? Sticking with the public documentation description of this function, it allows caching a subquery result during the time of query execution in a way that other subqueries can reference the partial result. That should clarify enough the way this function works. Using cache has always resulted to be faster than reading data.
In this screenshot there’s the DO approach together with the query performance data and returned data:

Here we have the same concept created using the DONT approach.

Despite the 2 queries returned exactly the same dataset, the latter was more expensive in term of performance for the underlying query engine and it took more time to return you the whispered data. Once again: the bigger your dataset is, the greater performance improvements you’ll get.
When using materialize there are things you should always consider:
- Materialize cache size limit is 5Gb.
- The limit is applied per cluster node and to all the same queries running in parallel.
- Reaching the cache limit will force query execution to be aborted with an error.
Did I make you curious enough?
That is exactly what I wanted  . Now you can read all this and even more about query best practices at Query best practices and Optimize log queries in Azure Monitor official Microsoft documentation pages.
. Now you can read all this and even more about query best practices at Query best practices and Optimize log queries in Azure Monitor official Microsoft documentation pages.
Thanks for reading,
Bruno.
Disclaimer
The sample scripts are not supported under any Microsoft standard support program or service. The sample scripts are provided AS IS without warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.
Background:
Azure DevOps provides developer services to support teams to plan work, collaborate on code development, and build and deploy applications. Developers can work in the cloud using Azure DevOps Services or on-premises using Azure DevOps Server. Azure DevOps Server was formerly named Visual Studio Team Foundation Server (TFS). Azure cloud services can be managed in Azure DevOps by using the PowerShell cmdlets that are available in the Azure PowerShell tools, so that you can perform all of your cloud service management tasks within the service. Management certificates allow you to authenticate with the classic deployment model. Many programs and tools (such as Visual Studio or the Azure SDK) use these certificates to automate configuration and deployment of various Azure services.
Purpose:
This blog is to guide you to create a management certificate and use it to manage your Azure Classic resources such as Cloud Service in Azure DevOps.
Part 1. Create a management certificate by openssl. (Refer to the document https://docs.microsoft.com/en-us/azure/application-gateway/self-signed-certificates#create-a-root-ca-certificate)
1. Sign in to your computer where OpenSSL is installed and run the following command. This creates a password protected key.
openssl ecparam -out test.key -name prime256v1 -genkey
2. Use the following commands to generate the csr and the certificate.
openssl req -new -sha256 -key test.key -out test.csr
3. When prompted, type the password for the root key, and the organizational information for the custom CA such as Country/Region, State, Org, OU, and the fully qualified domain name (this is the domain of the issuer).
openssl x509 -req -sha256 -days 365 -in test.csr -signkey test.key -out test.crt
4. Generate the pfx certificate by the crt file which can be used in the Azure DevOps pipeline.
openssl pkcs12 -export -out frankmgmt.pfx -inkey test.key -in test.crt
5. Create a cer file by the pfx certificate which can be uploaded to the Azure Portal as management certificate.
openssl pkcs12 -in frankmgmt.pfx -out test.cer -nodes
Part 2. Upload the cer file to the management certificate of subscription.
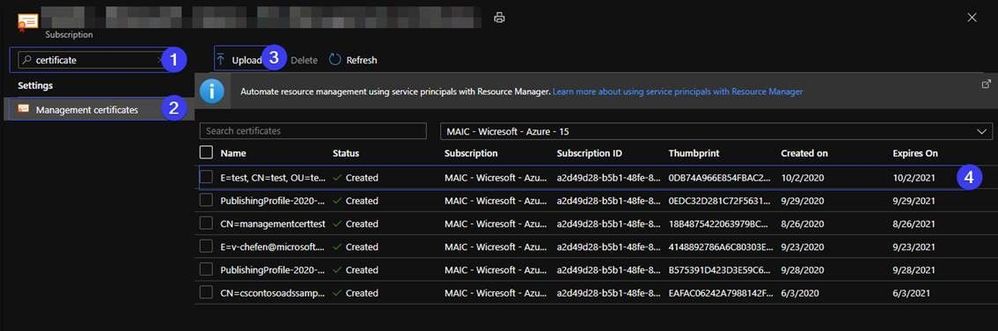
1. Search the certificate in the Subscription.
2. Pick the Management certificates.
3. Upload the cer file to the management certificate.
4. You will find the management certificate in the Azure Portal.
 1
1
Part 3. How to use the management certificate to verify the Azure Service Manager (ASM) resources in Azure DevOps pipeline.
1. In the Library, find the secure files and upload the pfx certificate as secure file.

2. Create Powershell script like below for test.
param ($input1)
Write-Host "Script test.ps1 ..."
$PSVersionTable
[System.Net.ServicePointManager]::SecurityProtocol = [System.Net.SecurityProtocolType]::Tls12;
$SigningCert = New-Object System.Security.Cryptography.X509Certificates.X509Certificate2
$SigningCert.Import($input1, "<password>", [System.Security.Cryptography.X509Certificates.X509KeyStorageFlags]"DefaultKeySet")
Set-AzureSubscription -SubscriptionName "<subscription name>" -SubscriptionId "<subscription id>" -Certificate $SigningCert
Select-AzureSubscription -SubscriptionName "<subscription name>"
3. Create two events in the pipeline, Download Secure file and PowerShell Script.

4. Download secure file.

5. Set up the script path and arguments of Powershell Script.

6. We can successfully get the cloud service deployment information by Get-AzureDeployment command.
Here is an example we used to get the deployment details in the cloud service. https://docs.microsoft.com/en-us/powershell/module/servicemanagement/azure.service/get-azuredeployment?view=azuresmps-4.0.0
Get-AzureDeployment

by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.
Hello bot developers,
In our previous blogpost, we have seen the magic of Bot Telemetry Logger middleware, like what does it offer and how does it work in harmony with the Application Insights. Today, I will be talking about the Bot Analytics blade.
If we compare these two telemetry; “Bot Telemetry Logger” reflects how Bot Service perceives traffic coming from and being sent to the Bot and “Bot Analytics” reflects the perspective of the bot itself. While they can be used in concert, they are different sets of data.
Bot Analytics blade can be accessed through Azure Portal, if you put “analytics” at the end of your URL like “https://ms.portal.azure.com/…./botServices/[botname]/analytics” . It is a built-in extension powered by application Insights, and provides conversation-level reporting on user, message, and channel data.
I witness some number of customer complaints that, it may not show the expected data, when our customers perform some Power BI reporting. I.e. when you use Bot Telemetry logger, the number of Users is not the same as in the “Bot Analytics” reports. Well, it may be normal because of the fact that, they are making analytics from different perspectives. Let me take you deeper cause of this:
Built-in “Bot Analytics Blade” uses a different schema when compared to other SDK based telemetry tools like “Bot Telemetry Logger”. It uses different queries, to report “User”/”Message”/”Channel Data” information. For example, it reaches out to user information from the “CustomEvents” table through “customDimensions” field, where the custom event is named as “Activity”. it is essentially using following query, for “User” reporting:
customEvents
| where name == ‘Activity’
| extend from = customDimensions[‘from’]
| extend from = tostring(iff(isnull(from), customDimensions[‘From ID’], from))
| extend channel = customDimensions[‘channel’]
| extend channel = tostring(iff(isnull(channel), customDimensions[‘Channel ID’], channel))
| extend activityType = customDimensions[‘Activity type’]
| where activityType != ‘{Microsoft.Bot.Schema.ActivityTypes.ConversationUpdate}’
| summarize event_count = dcount(from) by channel
| project customDimensions_channel = channel, event_count
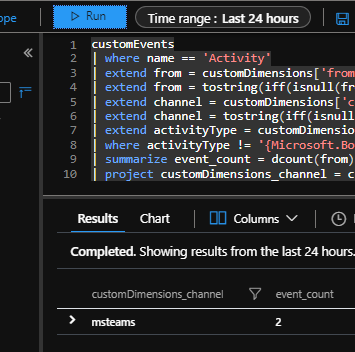
If you run this query, on the “Application Insights Project” which you configured for bot analytics, you will see that the results are similar with the “Bot Analytics Blade”. See it below, when we run it on Application Insights, for last 24 hours:

And here is a screenshot from “Bot analytics blade” , which show the exact same information.

On the other hand, “Bot Telemetry logger” has a different schema for user reporting. You may remember from our previous blogpost that it use the actual “user_Id” field when logging to “customEvents” table. This field is left empty for the “Bot Analytics” logger.
See below query that in the first row, we see the “user_Id”s logged by “Bot Telemetry Logger”, and in the second row, we see the other “customEvents”, logged by “Azure bot analytics” which has null “user_Id” field:

These logging schemas do not overlap or mix-up, because bot telemetry logger does not log any customEvent with a name “Activity”:

See Bot Telemetry logger, name constants here.
There are no plans to unify the two telemetry schemas at this time. They were designed independently, so you need to know how they log, to understand what you should expect. By that way, you can generate meaningful PowerBI reports from your Application insights data.
Hope you like my blogpost,
Stay tuned for the next one,
Mert
by Contributed | Nov 12, 2020 | Technology
This article is contributed. See the original author and article here.
1. Update to SAP on Azure Documentation
Several important updates to Azure documentation have been made recently.
Customers and Partners are recommended to regularly review the SAP on Azure documentation pages as new features and configurations are continuously improved.
The main SAP on Azure site https://azure.microsoft.com/en-us/solutions/sap/
SAP on Azure Resources https://azure.microsoft.com/en-us/solutions/sap/resources/
SAP on Azure Updates on the main Azure site https://azure.microsoft.com/en-us/updates/?query=sap
SAP on Azure Documentation “Getting Started” https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/get-started
Important Update for Linux High Availability customers – set the Linux kernel parameter net.ipv4.tcp_keepalive_time=300. It is recommended to set this parameter on DB, Application Servers and Central Services VMs. This now aligns with SAP Note: 1410736 – TCP/IP: setting keepalive interval
https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/high-availability-guide-suse
RHEL 8.1 is now supported on Azure VMs https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/high-availability-guide-rhel-pacemaker
The Microsoft documentation has been changed to recommend using the azure-lb resource agent. This is further explained in this SAP Note
2922194 – Linux Utility NetCat Running SUSE Pacemaker Stops Responding https://launchpad.support.sap.com/#/notes/0002922194
HA Scenarios are documented here https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/sap-high-availability-architecture-scenarios
Updates to Storage Configurations for Hana and AnyDB databases. Note some updates to blocksizes, host cache settings and new UltraDisk configurations
Considerations for Azure Virtual Machines DBMS deployment for SAP workload – Azure Virtual Machines | Microsoft Docs – https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/dbms_guide_general
SQL Server Azure Virtual Machines DBMS deployment for SAP workload – Azure Virtual Machines | Microsoft Docs https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/dbms_guide_sqlserver
Oracle Azure Virtual Machines DBMS deployment for SAP workload – Azure Virtual Machines | Microsoft Docs https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/dbms_guide_oracle
IBM Db2 Azure Virtual Machines DBMS deployment for SAP workload – Azure Virtual Machines | Microsoft Docs https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/dbms_guide_ibm
SAP HANA Azure virtual machine storage configurations https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/hana-vm-operations-storage
SAP documentation on storage configuration can be found here:
HANA – https://help.sap.com/viewer/2c1988d620e04368aa4103bf26f17727/2.0.05/en-US/4c24d332a37b4a3caad3e634f9900a45.html
SAP ASE (Section 3.7) – https://help.sap.com/doc/4f95c9e3741a1014955595407d8604de/CURRENT_VERSION/en-US/Inst_nw7x_unix_ase_abap.pdf
Oracle – https://help.sap.com/viewer/4b99f675d74f4990b75a8630869a0cd2/CURRENT_VERSION/en-US/9c578484622840bea589ff0eaf1ffa7a.html
DB2 – https://help.sap.com/viewer/4fbd902c7c76410bb82c6311dd4dc94b/CURRENT_VERSION/en-US/713eb64f45c6448c8dbe8a51b85680ee.html
2. Azure Linux OMS Agent Now Supports Python3
Older versions of the Azure Linux OMS Agent did not run or deploy after the Python release was updated to Python3 using the package python3-azure-mgmt-compute.
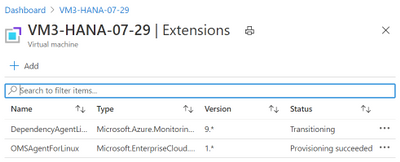
This issue is now resolved and the Linux OMS Agent now supports modern Python releases on Suse 12.x and Redhat.
Customers who are running Suse 15.1 will still be unable to use the full functionality as the Dependency Agent is not released for Suse 15.1 or Oracle Linux.
https://docs.microsoft.com/en-us/azure/azure-monitor/platform/agents-overview#supported-operating-systems
The Dependency Agent will stay in “Transitioning” status and the only data populated into Log Analytics will the in the “Heartbeat” and “InsightsMetrics” tables. Check this blog site regularly for updates on the Dependency Agent for Suse 15.1

3. High LOGWRITE Waitstat on SQL Server TDE Databases Due to Certificate Revocation List Not Accessible
The majority of customers running SAP on SQL Server on Azure are encrypting database using SQL Server TDE AES-256. An important feature of the SQL TDE mechanism is the Certificate Revocation List https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/encryption-hierarchy?view=sql-server-ver15
Several support cases have been analyzed recently where Firewall policies have blocked access to network resources that are checked by the Certificate Revocation mechanism.
The problem manifests as intermittent slow LOGWRITE and on AlwaysOn systems a the command TM REQUEST may be waiting on HADR_SYNC_COMMIT. The problem occurs on a regular periodic basis. SQL Server will run very slowly for approximately 180 seconds and them return to normal
There are two solutions to this problem:
- Turn off Certification Revocation (not recommended)
- Ensure that the Firewall is configured to allow access to the addresses in the whitelist in this link
https://docs.microsoft.com/en-us/azure/app-service/environment/firewall-integration
4. Recommended Blogs for SAP on Azure Customers & Consultants
Many new useful blogs have been created by Microsoft for SAP customers
SAP on Azure: Load Balancing Web Application Servers for SAP BOBI using Azure Application Gateway
https://blogs.sap.com/2020/09/17/sap-on-azure-load-balancing-web-application-servers-for-sap-bobi-using-azure-application-gateway/
SAP on Azure: Tomcat Clustering using Static Membership for SAP BusinessObjects BI Platform
https://blogs.sap.com/2020/09/04/sap-on-azure-tomcat-clustering-using-static-membership-for-sap-businessobjects-bi-platform/
Four Node AlwaysOn Cluster Across Azure Regions : https://blogs.sap.com/2020/10/20/sap-on-azure-sap-netweaver-7.5-on-ms-sql-server-2019-high-availability-and-disaster-recovery-with-4-nodes-alwayson-cluster/
SAP On Azure : HIGH AVAILIABILITY setup for SAP NETWEAVER with SAP ASE 16 DB on WINDOWS SERVER https://blogs.sap.com/2020/04/27/sap-on-azure-high-availiability-setup-for-sap-netweaver-with-sap-ase-16-db-on-windows-server/
SAP HANA HSR Multi-tier Longer Chains on Azure Geographic Clusters. Tertiary solutions are explained by Apparao in this blog
https://www.linkedin.com/pulse/sap-hana-hsr-multi-tier-longer-chains-azure-geographic-apparao-sanam/
Oracle customers can use this new upcoming blog series to setup and configure Oracle Linux 8.2, Oracle DB 19.8 with ASM and Dataguard.
https://techcommunity.microsoft.com/t5/running-sap-applications-on-the/sap-on-oracle-setup-on-azure-part1/ba-p/1865024
End to End Monitoring on the internal Microsoft SAP system. This includes the ability to read events such as ST22 shortdumps and correlate these events with infrastructure availability
https://www.microsoft.com/en-us/itshowcase/monitoring-sap-end-to-end-on-azure
5. Oracle Linux & PTP Timer – Especially for Oracle ASM Systems
Oracle Linux customers may receive errors in Oracle error logs similar to the text below. If this is seen it is recommended to edit the chrony.conf file and add the PTP timer
Warning: VKTM detected a forward time drift.
Time drifts can result in unexpected behavior such as time-outs.
Please see the VKTM trace file for more details
Check chrony configuration with the following command
chronyc sources -v
In chrony.conf, add line below,
refclock PHC /dev/ptp0 poll 3 dpoll -2 offset 0
And restart the chronyd, systemctl restart chronyd.service
[root@oracle77 ~]# chronyc sources -v
210 Number of sources = 5
.– Source mode ‘^’ = server, ‘=’ = peer, ‘#’ = local clock.
/ .- Source state ‘*’ = current synced, ‘+’ = combined , ‘-‘ = not combined,
| / ‘?’ = unreachable, ‘x’ = time may be in error, ‘~’ = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) –. | | yyyy = measured offset,
|| | | zzzz = estimated error.
|| | |
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
#* PHC0 0 3 377 12 +5187ns[+8446ns] +/- 1124ns ßLocal PTP clock source is added
^- undefined.hostname.local> 2 6 77 57 -251us[ -236us] +/- 81ms
^- tick.hk.china.logiplex.n> 2 6 77 55 -884us[ -887us] +/- 63ms
^? stratum2-01.hkg01.public> 2 7 1 46 -822us[ -827us] +/- 54ms
^- time.cloudflare.com 3 6 77 55 -2205us[-2208us] +/- 43ms
***************************************************************************************
6. Azure CLI Commands After Python3 Update on Suse
After updating to the latest Python3 release Azure CLI may stop working. The error message will be similar to “No module named azure.cli.__mail___; ‘azure.cli’ is a package and cannot be directly executed”
The message appears after updating to the latest Python/Python3 libraries and the package for the Azure SDK (python-azure-mgmt-compute on SLES12 ; python3-azure-mgmt-compute on SLES15)
Follow this procedure to resolve the problem on Suse 15.1:
- sudo zypper install –oldpackage azure-cli-2.0.45-4.22.noarch
- sudo zypper rm -y –clean-deps azure-cli
- Follow the standard installation procedure as detailed here https://docs.microsoft.com/en-us/cli/azure/install-azure-cli-zypper?view=azure-cli-latest
For more information review https://github.com/Azure/azure-cli/issues/13209#issuecomment-652164784
On Suse 12.x the problem presents differently
# az login
Traceback (most recent call last):
File “/usr/lib64/python3.4/runpy.py”, line 170, in _run_module_as_main
“__main__”, mod_spec)
File “/usr/lib64/python3.4/runpy.py”, line 85, in _run_code
exec(code, run_globals)
Follow this procedure to resolve the problem on Suse 12.x:
- Run this command to check the Python3 path
which python3
/usr/local/bin/python3
- If the python3 path is /usr/local/bin/python3 then run this command
sudo ln -sf /usr/local/bin/python3 /usr/bin/python3
- Run az self-test
7. SAP License Key May Become Invalid on Azure VMs
Some customers may notice that the SAP License Key on their systems may become invalid and SAP starts running on a temporary license key. This issue is explained in these SAP Notes.
https://launchpad.support.sap.com/#/notes/2937144 2937144 – Linux on Microsoft Azure: Upgrade to RHEL 8, SLES 12 SP5 or SLES 15 SP1 results in invalid SAP license
2975682 – Azure – SAP license invalid after reboot of VM due to changed hardware key with Linux guest OS https://launchpad.support.sap.com/#/notes/0002975682
https://launchpad.support.sap.com/#/notes/2243692 2243692 – Linux on Microsoft Azure (IaaS) VM: SAP license issues
8. SAP Note for Proximity Placement Groups
A new SAP Note discusses how to reduce latency between Database and SAP Application servers. Note 2931465 includes instructions on how to run /SSA/CAT. This utility is the most reliable and best way to measure latency between the database and application server. Ideally the result in the Acc DB and E. Acc DB columns should be below 100.
Only the Database and Applications servers for a single SID should be in PPG. The ASCS does not need to be in PPG. PPG should be kept as small and compact as possible. The communication between the SAP Application and the ASCS is not highly latency sensitive
2931465 – Reduce network latency (RTT) using Proximity placement groups on Microsoft Azure https://launchpad.support.sap.com/#/notes/2931465
https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/sap-proximity-placement-scenarios
9. Update on Support Matrix for SAP on Azure
In recent months many new features have become available for SAP customers. The list below is a very brief overview of recommended features and updated documentation
- RHEL 8.1 – is released and Generally Available for Azure
- Suse 15.2 is now certified for Netweaver and Hana
- Recommended stack for Oracle Customers – Oracle Linux OL 8.2 + Oracle 19.8c + Grid + ASM. ASM is highly recommended for all new Oracle systems. Oracle 18 is not recommended and will be EOL soon
- Windows 2019 – fully supported for NetWeaver and most standalone SAP components. Hyper-V support matrix can be found here
- Azure Backup for Hana now supports RHEL https://docs.microsoft.com/en-us/azure/backup/sap-hana-backup-support-matrix
- Azure now supports shared disks https://docs.microsoft.com/en-us/azure/virtual-machines/disks-shared-enable?tabs=azure-cli
- A new page documents HA scenarios including using Azure Shared Disks https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/sap-high-availability-architecture-scenarios
10. Saptune Version 2 – Update to Saptune 2 Recommended
Suse has updated Saptune for both Suse 12.x and 15.x
Run the command rpm -qa | grep -i saptune to check the version of Saptune
The blog below explains how to update and migrate to Saptune 2. Saptune 2 contains important updates to improve supportabilty and stability.
https://blogs.sap.com/2019/12/16/suse-lets-migrate-saptune-to-version-2/
https://blogs.sap.com/2019/05/03/a-new-saptune-is-knocking-on-your-door/
11. Azure Monitor for SAP
Azure Monitor for SAP is now in preview and supports VMs and HLI. Hana and SQL Server Databases are supported currently. Telemtry from Pacemaker Cluster is also collected and displayed. Azure Monitor for SAP is a free of charge service
A very small collector VM is required. Further documentation can be found here
https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/azure-monitor-overview
12. SAP on Azure – Customer Success Stories
Cathay Pacific has recently completed moving their SAP S4HANA system to Azure M-series. SAP application servers are running on E-series. As part of the project S4HANA was upgraded to 1809.
Orica has completed their global S4HANA global transformation with more than 50 countries on a single instance
Azure Load Balancer – switch from Netcat to more reliable Socat was completed this in the Q1’20.
SAP HANA upgrade to SPS 5 in progress
SuSE 12 Support Pack 5 upgrade in progress
Gen2 VM Migration – S/4HANA Database migrated to Gen 2 VM [M208ms_v2 (208 vcpus, 5700 GiB memory)] for both nodes in Cluster and in DR VM [E32s_v4 (32 vcpus, 256 GiB memory)].
Azure Application Proxy is used for Fiori launchpad and 1,400+ applications deployed. Azure Backup is used for SQL Server and HANA, Azure Site Recovery for DR and Azure Monitor for SAP Solutions for Production systems
More information can be found here: https://customers.microsoft.com/en-us/story/orica-mining-oil-gas-azure
13. Troubleshooting Checklist for Hana Performance Issues
Customers experiencing performance or reliability issues with SAP Hana installations are highly recommended to follow the troubleshooting process. The list below is a basic checklist that should be followed before raising a support case to Microsoft and SAP:
- Check the VM type used and verify Hana Certification https://www.sap.com/dmc/exp/2014-09-02-hana-hardware/enEN/iaas.html#categories=Microsoft%20Azure
- Check the Storage Configuration Guide has been followed https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/hana-vm-operations-storage
- Ensure the root disk is large enough. Very small root disks can cause performance problems
- Check Write Accelerator is enabled on Log Disks
- Check host cache settings is as per the Storage Configuration Guide
- Check Accelerated Networking enabled https://docs.microsoft.com/en-us/azure/virtual-network/create-vm-accelerated-networking-cli
- Check PPG is configured and run /SSA/CAT as per 2931465 – Reduce network latency (RTT) using Proximity placement groups on Microsoft Azure https://launchpad.support.sap.com/#/notes/2931465
- Install and run the latest Minicheck – check the “C” column. Any “X” in the C column should be investigated.
1999993 – How-To: Interpreting SAP HANA Mini Check Results https://launchpad.support.sap.com/#/notes/1999993
2600030 – Parameter Recommendations in SAP HANA Environments https://launchpad.support.sap.com/#/notes/2600030
14. R3load Based Hana System Copy – Tables >2 Billion Rows
SAP do not generally recommend copying Hana based systems with R3load and there are multiple issues that can occur when performing Homogeneous or Heterogenous system copies using R3load.
One issue is how to handle tables with more than 2 Billion rows. Hana supports 2 Billion rows per table partition.
2369936 – Overview of system copy options for systems based on SAP HANA
2784715 – SWPM: Using R3load-based migration for SAP System on HANA when tables contain more than 2 billion rows
15. Very Large Busy Hana VMs Freeze Due to Memory Exhaustion
Very large busy Hana VMs may sometimes freeze due to Linux kernel memory exhaustion.
The procedure below should be reviewed and discussed with the Linux vendor and implemented if appropriate
Steps to implement solution:
Set these kernel parametners
vm.min_free_kbytes = 65536
vm.zone_reclaim_mode = 0
(a) Get the current value of parameter “vm.min_free_kbytes”
[ root ] # sysctl vm.min_free_kbytes
(b) Increase minimal free memory and monitor for next 5 working days.
[ root ] # sysctl -w vm.zone_reclaim_mode=1
# sysctl -w vm.min_free_kbytes=Y
Example : # sysctl -w vm.min_free_kbytes=98304
(c) monitor in next 5 working days to see if message “Error 11 Resource temporarily unavailable” and/or
“Freeing unused kernel memory” still being reported.
[ root ] # egrep -i “Error 11|Resource temporarily unavailable|Freeing unused kernel memory” /var/log/messages
(d) If messages “Error 11 Resource temporarily unavailable” and/or
“Freeing unused kernel memory” are still reported, continue to increase another 50% ( value Z )
the value vm.min_free_kbytes using command “sysctl -w vm.min_free_kbytes”
[ root ] # sysctl -w vm.min_free_kbytes = Z
(e) If message “Error 11 Resource temporarily unavailable” and/or
“Freeing unused kernel memory” are/is no longer reported, make the
change settings permanently, add an appropriate line to the /etc/sysctl.conf
Refer: https://www.cyberciti.biz/faq/howto-set-sysctl-variables/
Information for Redhat 8.1 can be found here https://www.redhat.com/cms/managed-files/Handout%20Performance%20Analysis%20and%20Tuning%20Red%20Hat%20Enterprise%20Linux%202019.pdf
An additional note that should be reviewed on large Hana systems is listed below
1980196 – Setting Linux Kernel Parameter /proc/sys/vm/max_map_count on SAP HANA Systems
https://launchpad.support.sap.com/#/notes/1980196
Additional Links & Notes
Azure Files NFS 4.1 is now in Preview https://azure.microsoft.com/en-us/updates/azure-files-support-for-nfs-v41-is-now-in-preview/ Azure Files NFS removes the need for a highly available NFS VM infrastructure
SAP on Azure Free Online Training Course. Exam AZ-120: Planning and Administering Microsoft Azure for SAP Workloads
https://docs.microsoft.com/en-us/learn/certifications/exams/az-120
A free Certification Exam offer is here https://docs.microsoft.com/en-us/learn/certifications/microsoft-build-cloud-skills-challenge-2020-free-certification-exam-offer
Older JVM have been desupported and are not Customer Specific Maintenance only. 2981029 – Desupport of platform combinations for SAP JVM 5 and 6 https://launchpad.support.sap.com/#/notes/2981029
When testing Suse Pacemaker cluster the following procedure is useful
Simulating a Cluster Network Failure https://www.suse.com/support/kb/doc/?id=000018699
New Azure Hana Large Instances are available https://docs.microsoft.com/en-us/azure/virtual-machines/workloads/sap/hana-available-skus
S224OM [4 socket, 9TB (3TB DRAM + 6TB Optane)] – OLTP Scale Up
S896 [16 socket, 12TB] – OLTP with Scale Up and Scale Out
S672 [12 socket, 9TB] – OLTP with Scale Up and Scale Out
S448 [8 socket, 6TB] – OLTP with Scale Up and Scale Out
S672M [12 socket, 18TB] – OLTP Scale Up
S448M [8 socket, 12TB] – OLTP Scale Up
Important News About SAP Kernels can be found here
https://wiki.scn.sap.com/wiki/display/SI/SAP+Kernel%3A+Important+News
2880246 – SAP Kernel 722 EX2: General Information and Usage https://launchpad.support.sap.com/#/notes/0002880246
Important or Interesting SAP Notes
2950585 – SAP ASCS/ERS fails in Windows Failover Cluster https://launchpad.support.sap.com/#/notes/0002950585
2944287 – How to harden SAP systems regarding NTLM relay exploits? https://launchpad.support.sap.com/#/notes/0002944287
2931465 – Reduce network latency (RTT) using Proximity placement groups on Microsoft Azure https://launchpad.support.sap.com/#/notes/0002931465
2890138 – AL11 Alias Mapping for Windows File share on SAP running on Linux https://launchpad.support.sap.com/#/notes/0002890138
2887797 – Permissions problems to access SAPMNT share on Windows https://launchpad.support.sap.com/#/notes/0002887797
2937583 – SAP NW JAVA is not coming up after disabling TLS 1.0 and enabling TLS 1.2
https://launchpad.support.sap.com/#/notes/0002937583
2922820 – DBSL Support for SQL Server 2019 https://launchpad.support.sap.com/#/notes/0002922820
2917949 – Apply JDBC driver 8.2 https://launchpad.support.sap.com/#/notes/0002917949
2906652 – Deliver Microsoft JDBC Driver 8.2 https://launchpad.support.sap.com/#/notes/0002906652
A good presentation on Suse deployment for SAP
https://www.suse.com/c/trust-suse-for-maximizing-sap-system-availability-part-1-of-2/
Thanks to Sarah Young for providing these links on Azure Security
Top 10 Best Practices for Azure Security (documentation) – https://aka.ms/azuresecuritytop10
Top 10 Best Practices for Azure Security (video) – https://youtu.be/g0hgtxBDZVE
Microsoft Cloud Adoption Framework for Azure – https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/?WT.mc_id=modinfra-9720-socuff
Microsoft Security Documentation site – https://docs.microsoft.com/en-us/security/
Microsoft Cybersecurity Reference Architecture (MCRA) Slides – http://aka.ms/mcra
Microsoft’s lead security architect’s useful documents list – https://aka.ms/markslist
Azure Security Podcast – https://aka.ms/azsecpod
Azure Security Community Webinars – https://aka.ms/SecurityWebinars

Recent Comments