
by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.

How to fix the borderless window “problem” in Windows Virtual Desktop
Robin Hobo is an Enterprise Mobility MVP and Senior Solutions Architect from the Netherlands who advises companies about the modern workplace. Robin is broadly oriented and has in-depth knowledge of various solutions like Windows Virtual Desktop (WVD) and Microsoft EM+S (including Microsoft Endpoint Manager – Microsoft Intune). For more, check out Robin’s blog and Twitter @robinhobo

Set the custom Focusing status in Microsoft Teams from To Do using Power Automate
Office Apps & Services MVP Ståle Hansen is the Founder and Principal Cloud Architect at CloudWay. With more than a decade of experience with Skype for Business, Ståle is now focused on Teams and Hybrid Microsoft 365. In 2018, Ståle received an honorary award from Microsoft Norge for his longtime commitment for knowledge-sharing. For more, check out his Twitter @StaleHansen

Check The Quality Of All Power BI Data Models At Once With Best Practice Analyzer Automation (BPAA)
Dave Ruijter is a Data Platform MVP from the Netherlands, and he is a public speaker and consultant. His aim is to help organizations realize the full potential of the Azure cloud and the Microsoft Power Platform. He brings a decade’s worth of experience to the table and is a passionate Power BI evangelist, eager to share his knowledge and experiences from the field. For more, check out his blog or Twitter @daveruijter

Azure Automation: Scale-Down VM Size
George Chrysovalantis Grammatikos is based in Greece and is working for Tisski ltd. as an Azure Cloud Architect. He has more than 10 years’ experience in different technologies like BI & SQL Server Professional level solutions, Azure technologies, networking, security etc. He writes technical blogs for his blog “cloudopszone.com“, Wiki TechNet articles and also participates in discussions on TechNet and other technical blogs. Follow him on Twitter @gxgrammatikos.

WPF: HOW TO CONVERT BITMAP TO BYTES
Asma Khalid is an Entrepreneur, ISV, Product Manager, Full Stack .Net Expert, Community Speaker, Contributor, and Aspiring YouTuber. Asma counts more than 7 years of hands-on experience in Leading, Developing & Managing IT-related projects and products as an IT industry professional. Asma is the first woman from Pakistan to receive the MVP award three times, and the first to receive C-sharp corner online developer community MVP award four times. See her blog here.
by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.
In this blog post, we will explain how you can use Azure Data Explorer (will be referred to in this blog post as ADX from now on) as a secondary log store and when this might be appropriate for your .
One of the common questions that we get from customers and partners is how to save money on their Azure Sentinel bill, retention costs being one of the areas that can be optimized. As you may know, data retention in Sentinel is free for 90 days, after that, it is charged.
Customers normally need to keep data accessible for longer than three months. In some cases, this is
just due to regulatory requirements, but in some other cases they need to be able to run investigations on older data. ADX can be a great service to leverage in these cases, where the need to access older data exists, but at the same time customers want to save some costs on data retention.
What is Azure Data Explorer (ADX)?
ADX is a big data analytics platform that is highly optimized for all types of logs and telemetry data analytics. It provides low latency, high throughput ingestions with lightning speed queries over extremely large volumes of data. It is feature rich in time series analytics, log analytics, full text search, advanced analytics (e.g., pattern recognition, forecasting, anomaly detection), visualization, scheduling, orchestration, automation, and many more native capabilities.
Under the covers, it is a cluster comprised of engine nodes that serve out queries and data management service nodes that perform/orchestrate a variety of data related activities including ingestion and shard management. Some important features include:
- It offers configurable hot and cold caches backed by memory and local disk, with data persistency on Azure Storage.
- Data persisted in ADX is durably backed by Azure Storage that offers replication out of the box, locally within an Azure Data Center, zonally within an Azure Region.
- ADX uses Kusto Query Language (KQL) as the query language, which is what we also use in Azure Sentinel. This is a great benefit as we can use the same queries in both . Also, and as we will explain later in this article, we can perform cross-platform queries that aggregate/correlate data sitting across ADX and Sentinel/Log Analytics.
From a cost perspective, it offers reserved instance pricing for the compute nodes and autoscaling capabilities, which adjust the cluster size based on workload in execution. Azure Advisor also integrates with ADX to offer cost optimization recommendations.
You can learn much more about ADX in the official documentation pages and the ADX blog.
When to use ADX vs Azure for long term data
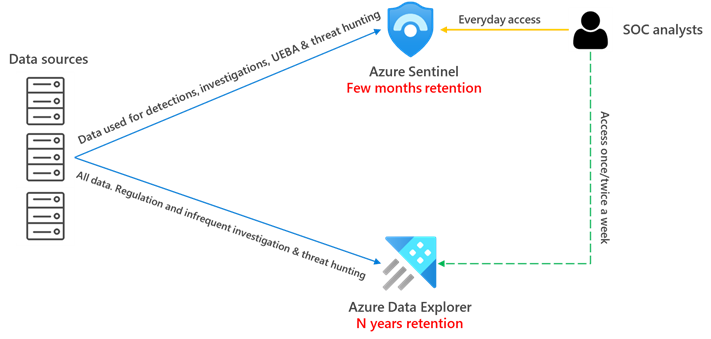
Azure Sentinel is a SaaS service with full SIEM+SOAR capabilities that offers very fast deployment and configuration times plus many advanced out-of-the-box security features needed in a SOC, to name a few: incident management, visual investigation, threat hunting, UEBA, detection rules engine powered by ML, etc.
That being said, security data stored in Sentinel might lose some of its value after a few months and SOC users might not need to access it as frequently as newer data. Still, they might need to access it for some sporadic investigations or audit purposes but remaining mindful of the retention cost in Sentinel. How do we achieve this balance then? ADX is the answer 
With ADX we can store the data at a lower price but still allowing us to explore the data using the same KQL queries that we execute in Sentinel. We can also use ADX proxy feature, which enables us to perform cross platform queries to aggregate and correlate data spread across ADX, Application Insights, and Sentinel/Log Analytics. We can even build Workbooks that visualize data spread across these data stores. ADX also opens new ways to store data that provide us with better control and granularity (see Management Considerations section below).
As a summary, in the context of a SOC, ADX provides the right balance of cost/usability for aged data that might not benefit anymore from all the security intelligence built on top of Azure .
Log Analytics Data Export feature
Let’s take a look at the new Data Export feature in Log Analytics that we will use in some of the architectures below (full documentation on this feature here).
This feature lets you export data of selected tables (see supported tables here) in your Log Analytics workspace as it reaches ingestion, and continuously send it to Azure Storage Account and/or Event Hub.
Once data export is configured in your workspace, any new data arriving at Log Analytics ingestion endpoint and targeted to your workspace for the selected tables, is exported to your Storage Account hourly or to EventHub in near-real-time. NOTE: There isn’t a way to filter data and limit the export to certain events – for example: when configuring data export rule for SecurityEvent table, all the data sent to SecurityEvent table is exported starting at configuration time.
Take the following into account:
- Both the workspace and the destination (Storage Account or Event Hub) must be located in the same region.
- Not all log types are supported as of now. See supported tables here.
- Custom log types are not supported as of now. They will be supported in the future.
Currently there’s no cost for this feature during preview, but in the future, there will be a cost associated with this feature based on the number of GB transferred. Pricing details can be seen here.
Architecture options
There are several options to integrate Azure Sentinel and ADX.
- Send the data to Sentinel and ADX in parallel
- Sentinel data sent to ADX via Event Hub
- Sentinel data sent to ADX via Azure Storage and Azure Data Factory
Send the data to Sentinel and ADX in parallel

This architecture is also explained here. In this case, only data that has security value is sent to Azure Sentinel, where it will be used in detections, incident investigations, threat hunting, UEBA, etc. The retention in Azure Sentinel will be limited to serve the purpose of the SOC users, typically 3-12 months retention is enough. All data (regardless of its security value) will be sent to ADX and be retained there for longer term as this is cheaper storage than Sentinel/Log.
An additional benefit of this architecture is that you can correlate data spread across both data stores. This can be especially helpful when you want to enrich security data (hosted in Sentinel), with operational data stored in ADX (see details here).
Adopting this architecture means that there will be some data that is stored in both Log Analytics and ADX, because what we send to Log Analytics is a subset of what is sent to ADX. Even with this data duplication, the cost savings are significant as we reduce the retention costs in Sentinel.
Azure Sentinel data sent to ADX via Event Hub
Combining the Data Export feature and ADX, we can choose to stream our logs to Event Hub and then ingest them into ADX. The high-level architecture would look like this:

With this architecture we have the full Sentinel SIEM experience (Incident management, Visual investigation, Threat hunting, advanced visualizations, UEBA,…) for data that needs to be accessed frequently (for example, 6 months) and then the ability to query long term data accessing directly the data stored in ADX. These queries to long term data can be ported without changes from Sentinel to ADX.
Similar to the previous case, with this architecture there will be some data duplication as the data is streamed to ADX as it arrives into Log Analytics.
How do you set this up you might ask? Here you have a high-level list of steps:
1. Configure Log Analytics Data Export to Event Hub. See detailed instructions here.
Steps 2 through 6 are documented in detail in this article: Ingest and query monitoring data in Azure Data Explorer
2. Create ADX cluster and database. The database is basically a workspace in Log Analytics terminology. Detailed steps can be found here. For guidance around ADX sizing, you can visit this link.
3. Create target tables. The raw data is ingested first to an intermediate table where the raw data is stored. At that time, the data will be manipulated and expanded. Using an update policy (think of this as a function that will be applied to all new data), the expanded data will then be ingested into the final table that will have the same schema as the original one in Log Analytics/Sentinel. We will set the retention on the raw table to 0 days, because we want the data to be stored only in the properly formatted table and deleted in the raw data table as soon as it’s transformed. Detailed steps for this step can be found here.
4. Create table mapping. Because the data format is json, data mapping is required. This defines how records will land in the raw events table as they come from Event Hub. Details for this step can be found here.
5. Create update policy and attach it to raw records table. In this step we create a function (update policy) and we attach it to the destination table so the data is transformed at ingestion time. See details here. This step is only needed if you want to have the tables with the same schema and format as in Log Analytics.
6. Create data connection between EventHub and raw data table in ADX. In this step, we tell ADX where and how to get the data from. In our case, it would be from EventHub, specifying the target raw table, what is the data format (json) and the mapping to be applied (created in step 4). Details on how to perform this here.
7. Modify retention for target table. The default retention policy is 100 years, which might be too much in most cases. With the following command we will modify the retention policy to be 1 year: .alter-merge table <tableName> policy retention softdelete = 365d recoverability = disabled
After all these steps are completed, you should be able to see your data in the table with the same schema you had in Log Analytics/Sentinel.
Additional cost components of this architecture are:
- Log Analytics Data Export – charged per exported GBs
- Event Hub – charged by Throughput Unit (1 TU ~ 1 MB/s)
Sentinel data sent to ADX via Azure Storage and Azure Data Factory

In this approach we use the Data export feature mentioned at the beginning of the article to export the data to Azure Storage and then Azure Data Factory will run a periodic job to export the data to ADX. This option allows us to copy data from Azure Storage only when it’s close to its retention limit in Log Analytics/Sentinel. Therefore, with this architecture there is not data duplication and we only use ADX to access data older than the retention set in Sentinel. In one hand, this solution is more complex, but on the other hand it offers the biggest cost savings.
Here you have a high-level list of steps on how to build this solution:
1. Configure Log Analytics Data Export to Azure Storage. See detailed instructions here.
2. Create ADX cluster and database. Same as in previous architecture. Detailed steps can be found here.
3. Create target tables. Same as in previous architecture. Detailed steps for this step can be found here.
4. Create table mapping. Same as previous architecture. Details for this step can be found here.
5. Create update policy and attach it to raw records table. Same as previous architecture. See details here.
6. Setup Azure Data Factory pipeline:
- Create linked services for Azure Storage and Azure Data Explorer.
- Create dataset from Azure Storage.
- Create data pipeline with copy operation based on LastModifiedDate properties. Guidance on how to do that can be found here.
Additional cost components of this architecture are:
- Log Analytics Data Export – charged per exported GBs.
- Azure Storage – charged by GBs stored.
- Azure Data Factory – charged per copy activities run.
Management considerations in ADX
These are some of the areas where ADX offers additional controls:
- Cluster size and SKU. You must carefully plan for the number of nodes and the VM SKU in your cluster. These factors will determine the amount of processing power and the size of your hot cache (SSD and memory). The bigger the cache, the more data you will be able to query at a higher performance. We encourage you to visit the ADX sizing calculator, where you can play with different configurations and see the resulting cost. ADX also has an auto-scale capability that makes intelligent decisions to add/remove nodes as needed based on cluster load (see more details here)
- Hot/cold cache. In ADX you have greater control on what data tables will be in hot cache and therefore will return results faster. If you have big amounts of data in your ADX cluster, it might be advisable to break down tables by month, so you have greater granularity on which data is present in hot cache. See here for more details.
- Retention. In ADX we have a setting that defines when will the data be removed from a database or from an individual table. This is obviously an important setting to limit our storage costs. See here for more details.
- Security. There are several security settings in ADX that help you protect your data. These range from identity management, encryption, , etc. (see here for details). Specifically around RBAC, there are ways in ADX to restrict access to databases, tables or even rows within a table. Here you can see details about row level security.
- Data sharing. ADX allows you to make pieces of data available to other parties (partner, vendor), or even buy data from other parties (more details here).
Summary
As you have seen throughout this article, you can stream your telemetry data to ADX to be used as a long-term storage option with lower cost than Sentinel/Log Analytics, and still have the data available for exploration using the same KQL queries that you use in Sentinel
Please post below if you have any questions or comments.
by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.
Synapse serverless SQL pool is query engine that enables you to query a variety of files and formats that you store in Azure Data Lake and Azure Cosmos DB. One very common text encoding format is UTF-8 encoding where the most common characters used in Latin western languages are optimally encoded with a single byte. Not very common western, Cyrillic, Turkish and other characters are encoded with 2 bytes, and special characters are encoded with more characters. UTF-8 encoding is popular because it is more optimal for majority of western languages, has the same storage efficiency as UTF-16 in most of the character sets.
Serverless SQL pool enables you to read UTF-8 encoded text, but you need to be careful to avoid conversion error that might be caused by wrong collations.
At the time of writing this post, Synapse SQL forces conversion of UTF-8 characters to plain VARCHAR characters if UTF-8 collation is not assigned to VARCHAR type. This behavior might cause unexpected text conversion error. In this article you will learn when this unexpected conversion can happen and how to avoid it.
What is collation?
Collation is property of string types in SQL Server, Azure SQL, and Synapse SQL that defines how to compare and sort strings. In addition, it describes encoding of string data. If collation name ends with UTF8 it represents strings encoded with UTF-8 collation, and otherwise you have something like UTF-16 encoded string.
In the following example is shown how to specify collation associated to string columns in external table definition:
CREATE EXTERNAL TABLE population (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
)
WITH (
LOCATION = 'csv/population/population.csv',
DATA_SOURCE = sqlondemanddemo,
FILE_FORMAT = QuotedCSVWithHeaderFormat
);
This table references CSV file and string columns don’t have UTF8 collation. Therefore, CSV file should not be UTF-8 encoded. Mismatch between encoding specified in collation and encoding in the files would probably cause conversion error. In this case, if your population data contains UTF-8 characters, they would be incorrectly converted once you read data. Therefore, you might need to use some UTF-8 collation instead of Latin1_General_BIN2 after COLLATE clause.
What are the UTF-8 encoded characters?
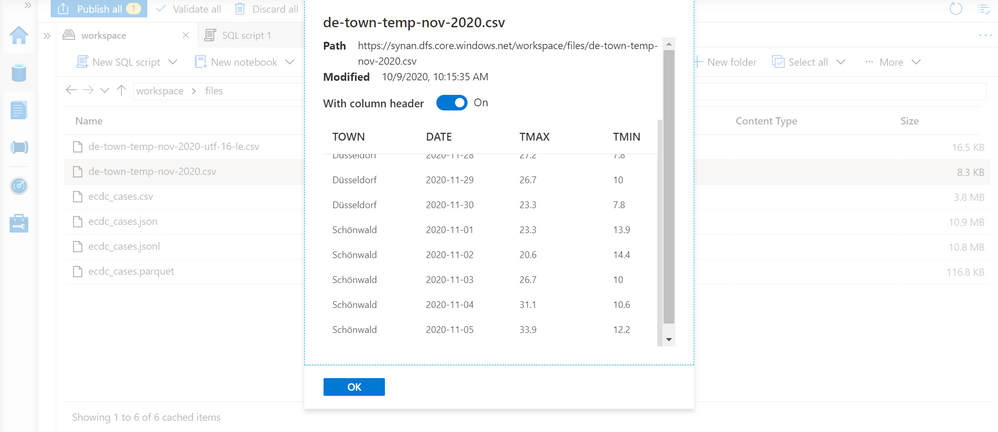
UTF-8 encoding represents most of the characters using 1 byte, but there are some characters that are not common in western languages. One example might be characters ü and ö in German words Düsseldorf and Schönwald.
Let us imagine that we have a CSV file encoded as UTF-8 text with the names of the towns containing these characters. If we preview the content of this file in Synapse Studio, we will get the following result:

Synapse Studio enables us to select this file and read the content using T-SQL queries with OPENROWSET function. Running a T-SQL query on database with default or any non-UTF8 collation might not return expected results:

You might see that the towns Düsseldorf and Schönwald are not same as in the preview on the previous picture.
In Synapse SQL, you must use some UTF-8 collation to return data for UTF-8 files. Otherwise, non-common characters would be suddenly converted.
At the time of writing this post, Synapse SQL silently forces conversion of UTF-8 characters to non-UTF-8 characters, which might cause conversion error. In future this behavior will be changed, and you will get explicit error if collation of string column that is returned by OPENROWSET is not UTF-8 and underlying text is UTF-8 encoded.
There are two ways to resolve this text conversion issue:
- Setting default collation for all string columns as database collation.
- Setting collation on every string column that OPENROWSET function returns.
Setting database collation
If you are working with UTF-8 data, the best way to configure your database is to set default collation on every database. You can set collation as part of CREATE DATABASE T-SQL statement:
CREATE DATABASE mydb
COLLATE Latin1_General_100_CI_AS_SC_UTF8;
If you have existing database, you can easily change collation on database:
ALTER DATABASE mydb
COLLATE Latin1_General_100_CI_AS_SC_UTF8;
From this point, every OPENROWSET will return correctly converted data.
Note that you would need to drop and re-create external tables if you have not explicitly specified collation. New default database collation will be applied only when table is created.
Specifying explicit collations
Instead of defining default database collation, you can explicitly specify collation when you declare column type using WITH clause.
OPENROWSET function enables you to explicitly specify columns and their types in WITH clause:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'latest/ecdc_cases.parquet',
DATA_SOURCE = 'covid',
FORMAT = 'parquet'
) WITH ( date_rep DATE, cases INT,
geo_id VARCHAR(6) COLLATE Latin1_General_100_CI_AS_SC_UTF8 ) as rows
If you are reading parquet files that have UTF-8 encoded text, or UTF-8 encoded text files, you would need to add UTF-8 collation in the type specification.
If you are defining tables, you can explicitly specify collation in column definition:
CREATE EXTERNAL TABLE population (
[country_code] VARCHAR (5) COLLATE Latin1_General_100_CI_AS_SC_UTF8,
[country_name] VARCHAR (100) COLLATE Latin1_General_100_CI_AS_SC_UTF8,
[year] SMALLINT,
[population] BIGINT
)
WITH (
LOCATION = 'csv/population/population.csv',
DATA_SOURCE = sqlondemanddemo,
FILE_FORMAT = QuotedCSVWithHeaderFormat
);
This way you can be sure that your table will return correct text regardless of database collation.
Conclusion
Matching column collation of string columns and encoding in files is important to avoid unexpected conversion errors. Currently serverless SQL pool silently converts UTF-8 data to non-UTF-8 data even if it knowns that there is a mismatch causing potential conversion error. This conversion would be treated as explicit error in the future, so make sure that you are using proper collations in OPENROWSET function and external tables to avoid errors.
Mitigation the issue is extremely easy, and you just need to alter database to use default UTF8 collation.
by Contributed | Nov 13, 2020 | Technology
This article is contributed. See the original author and article here.
It’s been sometime since we connected last so lots of news to cover this week. News this week includes: PowerShell support for Server Migration with Azure Migrate is now generally available, Updates to managing user authentication methods, New recommendations from Azure Advisor are now available, Microsoft announces the redesign of the Microsoft account Security page, QnA Maker introduces deep learning and as always our Microsoft Learn Module of the Week.
PowerShell support for Server Migration with Azure Migrate now Generally Available
Azure Migrate’s Server Migration tool provides an easier way to migrate servers and applications to Azure virtual machines. The new PowerShell based management interface for the Server Migration tool allows for the ability configure and manage replication of servers to Azure and migrate them to Azure virtual machines using Azure PowerShell cmdlets. These newly introduced PowerShell cmdlets can perform migrations in an automated repeatable manner as scale. In addition, the new Azure Migrate Azure PowerShell module adds PowerShell support for Server Migration tool’s agentless method of migrating VMware virtual machines to Azure. See the read further documentation on migrating virtual machines to Azure through Azure PowerShell here: Building a migration plan with Azure Migrate
Managing user authentication methods Updated

New features for managing users’ authentication methods has been released and include: a new experience for admins to manage users’ methods in Azure Portal, and a set of new APIs for managing FIDO2 security keys, Passwordless sign-in with the Microsoft Authenticator app, and more. Further detials surrounding this new enablement can be found here: New features for managing users’ authentication methods
New recommendations from Azure Advisor are now available
Azure Advisor now includes the following best practice recommendations to help improve performance and reliability of deployed Azure resources:
- Performance:
- Deploy VMs closer to the Windows Virtual Desktop deployment location—close proximity improves the user experience and connectivity (Read more)
- Upgrade to the latest version of the Immersive Reader SDK—this provides updated security, performance and an expanded set of features for customizing and enhancing the integration experience
- Reliability:
- Latest version of the Azure Connected Machine agent—upgrade for the best Azure Arc experience (Read more)
- Do not override hostnamewhen configuring Application Gateway this ensures website integrity
Advancing Password Spray Attack Detection
Microsoft has added new additions to their family of credential compromise detection capabilities with the introduction of machine learning technology and global signal to create incredibly accurate detection of a password spray nuanced attack. This is a great example of where worldwide, multi-tenant detection combines with rapidly evolving detection technology to keep organizations and end users safe from this very common attack. Further details surrounding this addition can be found here: The Evolution of Password Spray Detection
Microsoft Account Security Page Redesign
Microsoft recently launched a redesign to thier Account Security page making it easier to access account security information. Updates include easier management and visibility of enabled sign-in methods, more secure discovery of methods and consistent design across consumer and enterprise management. Further details surrounding the updates can be found here: Microsoft Account Security Page Redesign
Deep Learning made available within QnA Maker (Public Preview)
The new managed QnA Maker offering now includes the following capabilities:
- Precise phrase/short answer extraction from longer answer passages to deliver the precise information you need in a more user-friendly way
- Deep learnt ranker with enhanced relevance of results across all supported languages to provide even more accurate results to end-users
- Simplified resource management by reducing the number of resources deployed
- End-to-End region support for Authoring + Prediction
Additional details can be found here: QnA Maker Deep Learning preview
MS Learn Module of the Week

Manage identity and access in Azure Active Directory
Learn how to work with subscriptions, users, and groups by configuring Microsoft Azure Active Directory for workloads. This learning path can help you prepare for the Microsoft Certified: Azure Security Engineer Associate certification. The 9 module learning path can be completed here: Azure Active Directory Identity Management
Our team always appreciates your input on the Microsoft services news we share. Let us know in the comments below if there are any news items you would like to see covered in next week show. Az Update streams live every Friday so be sure to catch the next episode and join us in the live chat.

Recent Comments