![[Mentorship Spotlight] Community Mentoring: Paula & Kelvin](https://www.drware.com/wp-content/uploads/2020/09/medium-53)
by Scott Muniz | Sep 8, 2020 | Uncategorized
This article is contributed. See the original author and article here.
This month, we’re thrilled to kick off a new Mentorship spotlight series. We interviewed Paula Sillars, a network administrator and infrastructure tech support professional in Australia who shared about her mentorship experience with Singapore-based mentee Kelvin Chua via the Humans of IT Community Mentors mobile app. Stay tuned for our next post to hear Kelvin’s perspective as a mentee on the app.
Meet our featured mentor from Australia, Paula Sillars:

Q: Tell us a little about yourself.
A: I am a network administrator and infrastructure tech support professional. I have been working on it pretty much since I left school. I was a bit of a computer geek at school, so I ended up working at a University in the library systems department and that was sort of my first real job. From there I moved into managed services probably about 20 years ago. Now, I am an IT Manager based in Gold Coast, Australia.
Q: What does mentoring mean to you?
A: Sharing my knowledge and experience with others – but also opening someone up so they don’t feel like they are alone in their experience. You want to feel comfortable speaking with a person that is outside your normal work environment. Someone that you can bounce ideas off of and ask questions without fear of judgment from your colleagues. In some ways, it is like being a confidante, and a mentoring relationship should be a completely secure one. There is balance with having input from someone that is outside of your circle who can give you a different perspective. Maybe what I say will spark something new for this person.
Q: When did you first start as a mentor?
A: This is interesting because I always just shared my love and passion for tech with others and didn’t realize until speaking at the last Microsoft Ignite conference that others would find that valuable. I had always been fortunate to have many male allies at work that were supportive in teaching me and never making me feel alone that I didn’t realize other women could benefit from hearing my story and how I navigated my career over the last 20 years. When I discovered the Microsoft Humans of IT Community Mentors app, I knew that I wanted to get started. I think I’ve always naturally gravitated towards helping or mentoring others – even early on in my career I would take the junior engineers under my wing and help where I could. I always made myself available so people could have support whether it was “official” (i.e a formal mentorship) or not.
Q: What is the key to being an effective mentor?
A: Being empathetic – try to put yourself in that person’s position. The mentee doesn’t always know what they are asking. Don’t be judgmental. Keep the responses open so that the person can think about the response and come to their own conclusions, while you are more of a guide. The format that the Microsoft Humans of IT community uses works great because it gives you and the mentee time to absorb and ponder about the feedback. That helps me to be the most effective with the information I provide.
Q: What has inspired you to be a mentor?
A: Two years ago, I spoke at Microsoft Ignite and I was surprised by how many people were encouraged and interested in my story. That was what first inspired me to look for ways to share my story and help others. The Human of IT community and their free mentorship app made it so easy to get started!
Q: How did you get matched with each other?
A: Kelvin found my profile on the app and reached out to me – on the surface, it seemed like we really didn’t have much in common: Our backgrounds are different, we’re from different countries (Australia and Singapore) with very different cultures. However, our unique lived experiences actually worked out really well since we can share our diverse perspectives. Plus, logistically it was great because Kelvin was able to ask me questions through the app in his own time zone, and then when I had time during my break in my own time zone I then could read, think about and respond to his question.
Q: Tell us about your experience mentoring Kelvin?
A: It was really quite rewarding – while I do help other people at work, I don’t have any technical reports so working with Kelvin was amazing to have someone to share ideas with and formally mentor.
Q: What has been your experience with the app?
A: I am excited to do more – the process is not onerous; it was fast and convenient to interact when you have time. Plus, it was great to have something meaningful to do during my breaks!
What is your favorite feature?
A: The chat function – I used it the most, and it was the most helpful.
Note to readers: When you accept a mentorship request as a mentor, or have your mentorship requested by your mentor (if you’re a mentee), a private chat window will automatically open and remain open for 30 days so that you can conveniently communicate with your mentor. The duration of your mentorship can be extended for up to 90 days total if you and your mentor/mentee wish to continue communicating on the app beyond the initial 30 days.
Who is an example of a great mentor that inspired you?
A: I have a few in mind. Example 1: This isn’t necessarily a formal mentor, but I was working with a colleague, really looked up to him – a good bloke and a really smart guy. One time we were working at a data center and I didn’t think I could solve a particular issue and I blurted something like “Oh, I am not sure about that, I am not very technical”. He stopped me and said, “You’re out of your mind – you bring so much to the table and to the team – you’ve got amazing communication skills, you do the documentation, customers love you, so don’t put yourself down.” I was stunned because I was always working on teams that were specialized and I personally felt like I was never the most technical. This was the first time that someone that had no reason to tell me this actually said something, and it made me realize that I do bring a lot to the team that the others don’t have. After all these years, that has really stuck with me – it was so powerful that someone took the time to give me perspective and has greatly impacted my own outlook since.
Example 2: Early in my career, I was with a new customer – and he made totally inappropriate comments to me so I went back and told my boss. My boss called the customer and told him, “You made our associate so uncomfortable that we do not want to do business with you anymore.” My boss went to bat for me – that really made me feel important and that what I was doing was important. I so appreciate that I’ve had people help stand up for me in my career, and so I wanted to do the same for others.
Want to start your journey as a mentor and/or mentee?
1. Download the Microsoft Community Mentors app (make sure you’re on the latest v3.0!)
2. Log in with your Tech Community credentials (Note: You will need to be a member of the Humans of IT Community). If you are not already a member, you will be prompted to complete your Tech Community registration and officially join the Humans of IT community.
3. Create your profile and look for your future mentor and/or mentee!
Happy mentoring!
#HumansofIT
#Mentorship
#CommunityMentors
by Scott Muniz | Sep 8, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
A few months ago I wrote a post on how to use GraphQL with CosmosDB from Azure Functions, so this post might feel like a bit of a rehash of it, with the main difference being that I want to look at it from the perspective of doing .NET integration between the two.
The reason I wanted to tackle .NET GraphQL with Azure Functions is that it provides a unique opportunity, being able to leverage Function bindings. If you’re new to Azure Functions, bindings are a way to have the Functions runtime provide you with a connection to another service in a read, write or read/write mode. This could be useful in the scenario of a function being triggered by a file being uploaded to storage and then writing some metadata to a queue. But for todays scenario, we’re going to use a HTTP triggered function, our GraphQL endpoint, and then work with a database, CosmosDB.
Why CosmosDB? Well I thought it might be timely given they have just launched a consumption plan which works nicely with the idea of a serverless GraphQL host in Azure Functions.
While we have looked at using .NET for GraphQL previously in the series, for this post we’re going to use a different GraphQL .NET framework, Hot Chocolate, so there’s going to be some slightly different types to our previous demo, but it’s all in the name of exploring different options.
Getting Started
At the time of writing, Hot Chocolate doesn’t officially support Azure Functions as the host, but there is a proof of concept from a contributor that we’ll use as our starting point, so start by creating a new Functions project:
func init dotnet-graphql-cosmosdb --dotnet
Next, we’ll add the NuGet packages that we’re going to require for the project:
<PackageReference Include="Microsoft.Azure.Functions.Extensions" Version="1.0.0" />
<PackageReference Include="Microsoft.NET.Sdk.Functions" Version="3.0.3" />
<PackageReference Include="HotChocolate" Version="10.5.2" />
<PackageReference Include="HotChocolate.AspNetCore" Version="10.5.2" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.CosmosDB" Version="3.0.7" />
These versions are all the latest at the time of writing, but you may want to check out new versions of the packages if they are available.
And the last bit of getting started work is to bring in the proof of concept, so grab all the files from the GitHub repo and put them into a new folder under your project called FunctionsMiddleware.
Making a GraphQL Function
With the skeleton ready, it’s time to make a GraphQL endpoint in our Functions project, and to do that we’ll scaffold up a HTTP Trigger function:
func new --name GraphQL --template "HTTP trigger"
This will create a generic function for us and we’ll configure it to use the GraphQL endpoint, again we’ll use a snippet from the proof of concept:
using System.Threading;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.Http;
using Microsoft.AspNetCore.Http;
using Microsoft.Extensions.Logging;
using HotChocolate.AspNetCore;
namespace DotNet.GraphQL.CosmosDB
{
public class GraphQL
{
private readonly IGraphQLFunctions _graphQLFunctions;
public GraphQL(IGraphQLFunctions graphQLFunctions)
{
_graphQLFunctions = graphQLFunctions;
}
[FunctionName("graphql")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger log,
CancellationToken cancellationToken)
{
return await _graphQLFunctions.ExecuteFunctionsQueryAsync(
req.HttpContext,
cancellationToken);
}
}
}
Something you might notice about this function is that it’s no longer a static, it has a constructor, and that constructor has an argument. To make this work we’re going to need to configure dependency injection for Functions.
Adding Dependency Injection
Let’s start by creating a new class to our project called Startup:
using Microsoft.Azure.Functions.Extensions.DependencyInjection;
using Microsoft.Extensions.DependencyInjection;
[assembly: FunctionsStartup(typeof(DotNet.GraphQL.CosmosDB.Startup))]
namespace DotNet.GraphQL.CosmosDB
{
public class Startup : FunctionsStartup
{
public override void Configure(IFunctionsHostBuilder builder)
{
}
}
}
There’s two things that are important to note about this code, first is that we have the [assembly: FunctionsStartup(... assembly level attribute which points to the Startup class. This tells the Function runtime that we have a class which will do some stuff when the application starts. Then we have the Startup class which inherits from FunctionsStartup. This base class comes from the Microsoft.Azure.Functions.Extensions NuGet package and works similar to the startup class in an ASP.NET Core application by giving us a method which we can work with the startup pipeline and add items to the dependency injection framework.
We’ll come back to this though, as we need to create our GraphQL schema first.
Creating the GraphQL Schema
Like our previous demos, we’ll use the trivia app.
We’ll start with the model which exists in our CosmosDB store (I’ve populated a CosmosDB instance with a dump from OpenTriviaDB, you’ll find the JSON dump here). Create a new folder called Models and then a file called QuestionModel.cs:
using System.Collections.Generic;
using Newtonsoft.Json;
namespace DotNet.GraphQL.CosmosDB.Models
{
public class QuestionModel
{
public string Id { get; set; }
public string Question { get; set; }
[JsonProperty("correct_answer")]
public string CorrectAnswer { get; set; }
[JsonProperty("incorrect_answers")]
public List<string> IncorrectAnswers { get; set; }
public string Type { get; set; }
public string Difficulty { get; set; }
public string Category { get; set; }
}
}
As far as our application is aware, this is a generic data class with no GraphQL or Cosmos specific things in it (it has some attributes for helping with serialization/deserialization), now we need to create our GraphQL schema to expose it. We’ll make a new folder called Types and a file called Query.cs:
using DotNet.GraphQL.CosmosDB.Models;
using HotChocolate.Resolvers;
using Microsoft.Azure.Documents.Client;
using Microsoft.Azure.Documents.Linq;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
namespace DotNet.GraphQL.CosmosDB.Types
{
public class Query
{
public async Task<IEnumerable<QuestionModel>> GetQuestions(IResolverContext context)
{
// TODO
}
public async Task<QuestionModel> GetQuestion(IResolverContext context, string id)
{
// TODO
}
}
}
This class is again a plain C# class and Hot Chocolate will use it to get the types exposed in our query schema. We’ve created two methods on the class, one to get all questions and one to get a specific question, and it would be the equivalent GraphQL schema of:
type QuestionModel {
id: String
question: String
correctAnswer: String
incorrectAnswers: [String]
type: String
difficulty: String
category: String
}
schema {
query: {
questions: [QuestionModel]
question(id: String): QuestionModel
}
}
You’ll also notice that each method takes an IResolverContext, but that’s not appearing in the schema, well that’s because it’s a special Hot Chocolate type that will give us access to the GraphQL context within the resolver function.
But, the schema has a lot of nullable properties in it and we don’t want that, so to tackle this we’ll create an ObjectType for the models we’re mapping. Create a class called QueryType:
using HotChocolate.Types;
namespace DotNet.GraphQL.CosmosDB.Types
{
public class QueryType : ObjectType<Query>
{
protected override void Configure(IObjectTypeDescriptor<Query> descriptor)
{
descriptor.Field(q => q.GetQuestions(default!))
.Description("Get all questions in the system")
.Type<NonNullType<ListType<NonNullType<QuestionType>>>>();
descriptor.Field(q => q.GetQuestion(default!, default!))
.Description("Get a question")
.Argument("id", d => d.Type<IdType>())
.Type<NonNullType<QuestionType>>();
}
}
}
Here we’re using an IObjectTypeDescription to define some information around the fields on the Query, and the way we want the types exposed in the GraphQL schema, using the built in GraphQL type system. We’ll also do one for the QuestionModel in QuestionType:
using DotNet.GraphQL.CosmosDB.Models;
using HotChocolate.Types;
namespace DotNet.GraphQL.CosmosDB.Types
{
public class QuestionType : ObjectType<QuestionModel>
{
protected override void Configure(IObjectTypeDescriptor<QuestionModel> descriptor)
{
descriptor.Field(q => q.Id)
.Type<IdType>();
}
}
}
Consuming the GraphQL Schema
Before we implement our resolvers, let’s wire up the schema into our application, and to do that we’ll head back to Startup.cs, and register the query, along with Hot Chocolate:
public override void Configure(IFunctionsHostBuilder builder)
{
builder.Services.AddSingleton<Query>();
builder.Services.AddGraphQL(sp =>
SchemaBuilder.New()
.AddServices(sp)
.AddQueryType<QueryType>()
.Create()
);
builder.Services.AddAzureFunctionsGraphQL();
}
First off we’re registering the Query as a singleton so it can be resolved, and then we’re adding GraphQL from Hot Chocolate. With the schema registration, we’re using a callback that will actually create the schema using SchemaBuilder, registering the available services from the dependency injection container and finally adding our QueryType, so GraphQL understands the nuanced type system.
Lastly, we call an extension method provided by the proof of concept code we included early to register GraphQL support for Functions.
Implementing Resolvers
For the resolvers in the Query class, we’re going to need access to CosmosDB so that we can pull the data from there. We could go and create a CosmosDB connection and then register it in our dependency injection framework, but this won’t take advantage of the input bindings in Functions.
With Azure Functions we can setup an input binding to CosmosDB, specifically we can get a DocumentClient provided to us, which FUnctions will take care of connection client reuse and other performance concerns that we might get when we’re working in a serverless environment. And this is where the resolver context, provided by IResolverContext will come in handy, but first we’re going to modify the proof of concept a little, so we can add to the context.
We’ll start by modifying the IGraphQLFunctions interface and adding a new argument to ExecuteFunctionsQueryAsync:
Task<IActionResult> ExecuteFunctionsQueryAsync(
HttpContext httpContext,
IDictionary<string, object> context,
CancellationToken cancellationToken);
This IDictionary<string, object> will allow us to provide any arbitrary additional context information to the resolvers. Now we need to update the implementation in GraphQLFunctions.cs:
public async Task<IActionResult> ExecuteFunctionsQueryAsync(
HttpContext httpContext,
IDictionary<string, object> context,
CancellationToken cancellationToken)
{
using var stream = httpContext.Request.Body;
var requestQuery = await _requestParser
.ReadJsonRequestAsync(stream, cancellationToken)
.ConfigureAwait(false);
var builder = QueryRequestBuilder.New();
if (requestQuery.Count > 0)
{
var firstQuery = requestQuery[0];
builder
.SetQuery(firstQuery.Query)
.SetOperation(firstQuery.OperationName)
.SetQueryName(firstQuery.QueryName);
foreach (var item in context)
{
builder.AddProperty(item.Key, item.Value);
}
if (firstQuery.Variables != null
&& firstQuery.Variables.Count > 0)
{
builder.SetVariableValues(firstQuery.Variables);
}
}
var result = await Executor.ExecuteAsync(builder.Create());
await _jsonQueryResultSerializer.SerializeAsync((IReadOnlyQueryResult)result, httpContext.Response.Body);
return new EmptyResult();
}
There’s two things we’ve done here, first is adding that new argument so we match the signature of the interface, secondly is when the QueryRequestBuilder is being setup we’ll loop over the context dictionary and add each item as a property of the resolver context.
And lastly, we need to update the Function itself to have an input binding to CosmosDB, and then provide that to the resolvers:
[FunctionName("graphql")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger log,
[CosmosDB(
databaseName: "trivia",
collectionName: "questions",
ConnectionStringSetting = "CosmosDBConnection")] DocumentClient client,
CancellationToken cancellationToken)
{
return await _graphQLFunctions.ExecuteFunctionsQueryAsync(
req.HttpContext,
new Dictionary<string, object> {
{ "client", client },
{ "log", log }
},
cancellationToken);
}
With that sorted we can implement our resolvers. Let’s start with the GetQuestions one to grab all of the questions from CosmosDB:
public async Task<IEnumerable<QuestionModel>> GetQuestions(IResolverContext context)
{
var client = (DocumentClient)context.ContextData["client"];
var collectionUri = UriFactory.CreateDocumentCollectionUri("trivia", "questions");
var query = client.CreateDocumentQuery<QuestionModel>(collectionUri)
.AsDocumentQuery();
var quizzes = new List<QuestionModel>();
while (query.HasMoreResults)
{
foreach (var result in await query.ExecuteNextAsync<QuestionModel>())
{
quizzes.Add(result);
}
}
return quizzes;
}
Using the IResolverContext we can access the ContextData which is a dictionary containing the properties that we’ve injected, one being the DocumentClient. From here we create a query against CosmosDB using CreateDocumentQuery and then iterate over the result set, pushing it into a collection that is returned.
To get a single question we can implement the GetQuestion resolver:
public async Task<QuestionModel> GetQuestion(IResolverContext context, string id)
{
var client = (DocumentClient)context.ContextData["client"];
var collectionUri = UriFactory.CreateDocumentCollectionUri("trivia", "questions");
var sql = new SqlQuerySpec("SELECT * FROM c WHERE c.id = @id");
sql.Parameters.Add(new SqlParameter("@id", id));
var query = client.CreateDocumentQuery<QuestionModel>(collectionUri, sql, new FeedOptions { EnableCrossPartitionQuery = true })
.AsDocumentQuery();
while (query.HasMoreResults)
{
foreach (var result in await query.ExecuteNextAsync<QuestionModel>())
{
return result;
}
}
throw new ArgumentException("ID does not match a question in the database");
}
This time we are creating a SqlQuerySpec to do a parameterised query for the item that matches with the provided ID. One other difference is that I needed to enable CrossPartitionQueries in the FeedOptions, because the id field is not the partitionKey, so you may not need that, depending on your CosmosDB schema design. And eventually, once the query completes we look for the first item, and if none exists raise an exception that’ll bubble out as an error from GraphQL.
Conclusion
With all this done, we now have a our GraphQL server running in Azure Functions and connected up to a CosmosDB backend, in which we have no need to do any connection management ourselves, that’s taken care of by the input binding.
You’ll find the full code of my sample on GitHub.
While this has been a read-only example, you could expand this out to support GraphQL mutations and write data to CosmosDB with a few more resolvers.
Something else that would be worth for you to explore is how you can look at the fields being selected in the query, and only retrieve that data from CosmosDB, because here we’re pulling all fields, but if you create a query like:
{
questions {
id
question
correctAnswer
incorrectAnswers
}
}
It might be optimal to not return fields like type or category from CosmosDB.
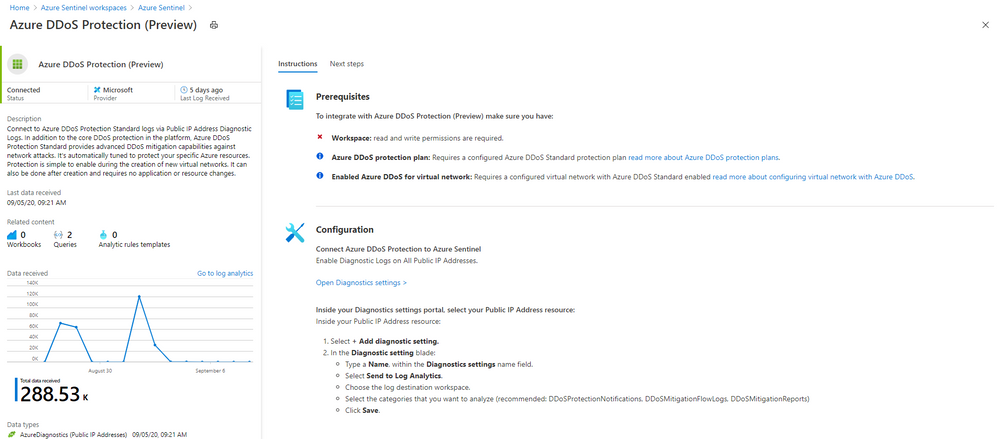
by Scott Muniz | Sep 8, 2020 | Azure, Technology, Uncategorized
This article is contributed. See the original author and article here.
This installment is part of a broader series to keep you up to date with the latest features in Azure Sentinel. The installments will be bite-sized to enable you to easily digest the new content.
Even more Azure Sentinel connector news for you! If you are using Azure DDoS Standard Protection, you can now ingest this via our connector into your Azure Sentinel workspace.
In addition to the core DDoS protection in the Azure platform, Azure DDoS Protection Standard provides advanced DDoS mitigation capabilities against network attacks. It’s automatically tuned to protect your specific Azure resources. Protection is simple to enable during the creation of new virtual networks. It can also be done after creation and requires no application or resource changes.
Connecting Azure DDoS Protection Standard logs to Azure Sentinel enables you to view and analyze this data in your workbooks, query it to create custom alerts, and incorporate it to improve your investigation process, giving you more insight into your platform security.

How to enable Azure DDoS Protection log ingestion in Azure Sentinel
Prerequisite – You must have a configured Azure DDoS Standard protection plan.
1. From the Azure Sentinel navigation menu, select Data connectors.

2. Select Azure DDoS Protection from the data connectors gallery, and then select Open Connector Page on the preview pane.
3. Enable Diagnostic logs on all the firewalls whose logs you wish to connect:
a. Select the Open Diagnostics settings > link and choose a Public IP Address resource from the list.


b. Select + Add diagnostic setting.

c. In the Diagnostics settings screen
- Enter a name in the Diagnostic setting name field.
- Mark the Send to Log Analytics check box. Two new fields will be displayed below it. Choose the relevant Subscription and Log Analytics Workspace (where Azure Sentinel resides).
- Mark the check boxes of the rule types whose logs you want to ingest. We recommend DDoSProtectionNotifications, DDoSMitigationFlowLogs, and DDoSMitigationReports.

d. Click Save at the top of the screen. Repeat this process for any additional firewalls (public IP addresses) for which you have enabled DDoS protection.
4. To use the relevant schema in Log Analytics for Azure DDoS Protection alerts, search for AzureDiagnostics. Here’s an example query below:
AzureDiagnostics
| where ResourceType == "PUBLICIPADDRESSES"
| sort by TimeGenerated
And that’s it! You will now have Azure DDoS Standard logs connected to your Sentinel workspace.
Get Started Today!
Try out the new connector and let us know your feedback using any of the channels listed in the Resources.
You can also contribute new connectors, workbooks, analytics and more in Azure Sentinel. Get started now by joining the Azure Sentinel Threat Hunters GitHub community and follow the guidance.


Recent Comments