Coming Soon: Outlook for Android support for Android 10 device password complexity
This article is contributed. See the original author and article here.
At the end of August, Outlook for Android will roll out support for the new device password complexity functionality included within Android 10 and later.
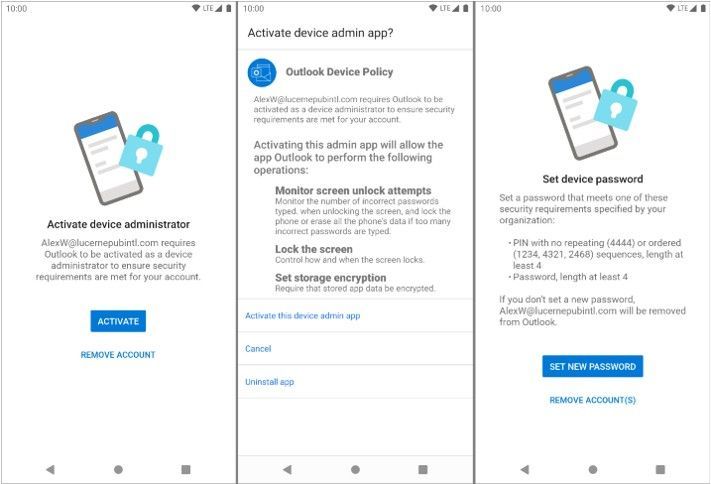
With each operating system version release, Google includes new APIs in which apps can target for supporting new functionality offered in the operating system release. Until apps target those APIs, they are not able to take advantage of that functionality. When Google announced Android 10 and its latest API (API 29), they also announced deprecation of Device Admin. Prior to targeting Android 10, Outlook for Android used Device Admin to manage device password settings defined in an Exchange mobile device mailbox policy; for more information see, Managing Outlook for iOS and Android in Exchange Online.
With Outlook for Android targeting Android 10, when a user launches Outlook on Android 10 and later devices, Outlook queries the device’s (or the work profile’s) screen lock complexity. Android 10’s password complexity levels are defined as:
|
Password complexity level |
Password requirements |
|
None |
No password requirements are configured |
|
Low |
Password can be a pattern or a PIN with either repeating (4444) or ordered (1234, 4321, 2468) sequences |
|
Medium |
Passwords that meet one of the following criteria: – PIN with no repeating (4444) or ordered (1234, 4321, 2468) sequences with a minimum length of 4 characters |
|
High |
Passwords that meet one of the following criteria: – PIN with no repeating (4444) or ordered (1234, 4321, 2468) sequences with a minimum length of 8 characters |
If Android determines that Outlook requires a stronger screen lock, then Outlook directs the user to the system screen lock settings, allowing the user to update the security settings to become compliant:

At no time is Outlook aware of the user’s password; the app is only aware of the password complexity level.
The specific password complexity criteria and conversion logic used for translating Exchange mobile mailbox device policy password settings to Android 10 password complexity levels is below, but is also documented in Mobile device mailbox policies in Exchange Online:
|
Mobile device mailbox policy setting |
Android password complexity level |
|
Password enabled = false |
None |
|
Allow simple password = true |
Low |
|
Allow simple password = true |
Medium |
|
Allow simple password = false |
Medium |
|
Allow simple password = true |
High |
|
Allow simple password = false |
High |
The change associated with Android 10 will go into effect immediately once the version of Outlook for Android that targets Android 10 is updated at the end of August. For devices that are not upgraded to Android 10 (Android 9 and below), Device Admin will continue to be in use for managing the device’s password and there are no changes to Outlook’s use of Device Admin from a user experience perspective.
What do I need to do to prepare for this change?
There is nothing you need to prepare for this change. This may be a good time to review your current password policies for mobile devices and mobile apps. Our recommendation is to consult with your Microsoft account team on the right security solution for your organization. Depending on whether your devices are company owned or BYOD, the recommendation will vary. Our recommendation is that administrators do not rely on Exchange mobile device mailbox policies, but instead use a mobile management solution such as Microsoft Intune to set access requirement conditions appropriate for your organization. To learn more visit https://aka.ms/startoutlookmobile.
We also recommend that your users upgrade to the latest version of Android that is supported on your users’ phones and tablets.
Additional resources
- Android device admin deprecation
- Android Enterprise fully managed devices
- Android Enterprise work profile devices
- App Protection Policy Data Protection Framework
- Identity and devices access configurations
- Securing Outlook for iOS and Android
















Recent Comments