by Contributed | May 6, 2023 | Technology
This article is contributed. See the original author and article here.
We are pleased to announce the security review for Microsoft Edge, version 113!
We have reviewed the new settings in Microsoft Edge version 113 and determined that there are no additional security settings that require enforcement. The Microsoft Edge version 112 security baseline continues to be our recommended configuration which can be downloaded from the Microsoft Security Compliance Toolkit.
Microsoft Edge version 113 introduced 3 new computer settings and 3 new user settings. We have included a spreadsheet listing the new settings in the release to make it easier for you to find them.
As a friendly reminder, all available settings for Microsoft Edge are documented here, and all available settings for Microsoft Edge Update are documented here.
Please continue to give us feedback through the Security Baselines Discussion site or this post.

by Contributed | May 6, 2023 | Technology
This article is contributed. See the original author and article here.
DAX is now your Friend

Learning and understanding DAX in Power BI can come with some challenges especially for Beginners. What if you can write DAX with just natural language, Isn’t that awesome?
Yes, DAX is now your friend.
Let’s analyze the magic happening in the image below.
1. Write what you want to achieve in natural language and the AI automatically generate the DAX function to achieve it
2. If you notice, I intentionally misspelt “Total” by writing “Toal” yet, it understood what I am trying to do.
Now imagine what you will learn going through this live session with us.

This session focuses on helping you to improve your DAX knowledge and skill.
We will do this by working on a full Power BI Report project and use the new AI capabilities in DAX to get this done.
About the Session
Are you ready to witness the latest and greatest capabilities of Power BI’s DAX language, now infused with Artificial Intelligence? In this session, we will take you through an exhilarating journey of building a complete Power BI report project, utilizing the powerful DAX language and its new AI capabilities.
Our expert presenters will showcase how to leverage the DAX suggestions feature to optimize your data model and make your report building process faster and more efficient. You will learn how to use DAX to create custom calculations and measure your data, while also harnessing the power of AI to enhance the accuracy and intelligence of your reports.
Throughout the session, you will get an inside look at how DAX suggestions can simplify and streamline your data analysis process, allowing you to focus on creating valuable insights and visualizations for your audience.
Whether you are a seasoned Power BI user or just starting out, this live session will provide you with valuable insights and practical tips to help you master the art of building end-to-end Power BI projects with DAX suggestions.
Join us for an exciting and informative Power BI live session that is sure to leave you inspired and equipped with the latest tools and techniques to take your data analysis and reporting to the next level.
Register
Event Date: May 18th, 2023
Time: 2PM (GMT+1)
To register, kindly click on the link here https://aka.ms/PowerBIDAXSuggestion
Additional Resources
Start Learning About DAX Suggestion Here
by Contributed | May 5, 2023 | Technology
This article is contributed. See the original author and article here.
Azure Logic Apps recently announced the public preview release of the new Data Mapper extension. If you haven’t had a chance to learn about this exciting new tool, check out our announcement. Already had the opportunity to test out Data Mapper? Consider meeting with the team as we are looking for feedback on this new extension.
Call for Feedback
We want to hear from you about your experiences thus far with the new Data Mapper extension. Your time and thoughts are appreciated and important to us in ensuring the best future for our product. We’re focused on hearing from developers and including your thoughts in our next upcoming release.
If you are interested in providing your insight to our team, please fill out this form so we can schedule a time to meet with you.
by Contributed | May 4, 2023 | Technology
This article is contributed. See the original author and article here.
Today Data Exposed went live at 9AM PT for a special Ask Me Anything and news update. If you missed the episode, you can find them all at https://aka.ms/AzureSQLYT. This month we’ll recap all the updates in April. This was a special May the Fourth [be with you] episode, and we had great guests (and fun) with the product group and our MVP community.
By the way, if you want to see a summary of all the updates in 2022, check out the blog https://aka.ms/NewsUpdate2022. If you want a summary of all the updates in 2023’s first quarter, check out the blog https://aka.ms/newsupdate2023q1.
You can read this blog to get all the updates and references mentioned in the show. Here’s the May 2023 update:
Let’s start with Azure SQL Managed Instance, which had several general availability (GA) announcements in April. First, the GA of Link feature for Azure SQL Managed Instance for SQL Server 2016 and 2019 happened. This capability allows you to set up near real-time replication between a SQL Server and SQL MI. You can use this link for scale, migration, read-only workloads, etc. To learn more, review the announcement blog. The team also announced the GA of CETAS. This stands for Create External Table As Select, which essentially means you can create an external table while in parallel exporting the results of a SELECT statement. This has been a customer ask and you can learn how to take advantage of it here.
For Azure SQL Database, a couple things landed in the security space related to auditing and TDE. Auditing can be connected to a storage account using an access key, but now you can also use a managed identity! For more information, refer to the announcement blog. For transparent data encryption (TDE), using customer-managed keys (CMK) is something we’ve been working on. In public preview, we announced support for database-level as well as cross-tenant TDE with CMK for Azure SQL Database. Prior to this, TDE with CMK was always set at the server level, and is inherited by all encrypted databases associated with that server. The database-level feature allows setting the TDE protector as a customer-managed key individually for each database within the server. The cross-tenant feature allows you to use TDE with CMK without the need to have the Azure SQL logical server be in the same Azure Active Directory (Azure AD) tenant as the Azure Key Vault that stores the customer-managed key used to protect the server. In a limited preview, we recently announced DOP Feedback for Azure SQL Database, learn more about the preview here.
SQL Server on Azure Virtual Machines is powered by the SQL IaaS Agent extension, which enables you to get a lot of benefits for managing your SQL Server Azure VMs with ease. There are a couple of announcements in this space, including that we are retiring modes (no more selecting Lightweight or Full, you just pick to enable the features or not!). We also announced the GA of AAD authentication for SQL Server on Azure VMs. This is available starting with SQL Server 2022, and we have made it easy for you to enable and configure in Azure. Finally, we are always updating and enhancing the SQL IaaS extension, and now we have an auto-upgrade setting! This is on by default for new instances, but you can also opt-in. More information.
For Hybrid, we announced the new centrally managed Azure Hybrid Benefit for SQL Server. This is a new Azure portal feature that helps you improve SQL Server license management at multiple levels, including at account and subscription levels. More information.
On the tooling and developer front, Azure Data Studio 1.43 went GA, including SQL Database Projects extension GA, Connectivity improvements, and other ‘odds and ends’ as Erin Stellato says. Get the details in the release blog. I also want to highlight her awesome (and viral) blog called “April Tools Day” (released on April 1), where she debunks some myths about Azure Data Studio, SSMS, Drivers, and more. I don’t want to summarize it further, because you really should just go read it. We also open-sourced ScriptDOM, which is a powerful .NET library for code parsing, generating an abstract syntax tree (AST) that can be leveraged to apply code formatting, detect antipatterns, and more.
Videos
We continued to release new and exciting episodes this month. Here is the list, or you can just see the playlist we created with all the episodes!
- Use Microsoft Purview DevOps policies to control access and limit insider threats
- [MVP Edition] Bring your SQL expertise to the Data Lake with Serverless SQL Pools
- Don’t let change pass you by! Get started with Change Tracking in your SQL Database
- SQL Insider Series: Get Started with Azure Cognitive Search for Azure SQL
- Registering SQL Server on Azure Virtual Machines with New IaaS Agent Extension Benefits (Ep. 12)
- SQL Server 2022: T-SQL Enhancements [Ep. 6]
- [MVP Edition] Capturing Query Metrics in Azure SQL Database
We’ve also had some great Data Exposed Live sessions this year. Subscribe to our YouTube channel to see them all and get notified when we stream.
Events
If you are looking to attend some in-person and virtual events this month, the Azure Data team has you covered. We’ll be at the following events and are looking forward to seeing you there!
May 6: SQLSaturday Jacksonville
– May 5: The SQL Server 2022 Workshop, Bob Ward
– May 6: SQL Server 2022 and the Wheel of Power, Bob Ward
May 12: New Stars of Data, Virtual
– From your Couch to the Cloud: When and Why to use the Azure Portal, Makena Barickman
May 15-17: Techorama, Belgium
– Confidential computing with Always Encrypted using enclaves, Pieter Vanhove
May 22-25: Dell Technologies World, Las Vegas
– Microsoft & Dell: Evolve your data strategy with SQL Server and Azure Arc, Bob Ward
– Take control of your data using Microsoft Azure Hybrid, Bob Ward
May 23: Red Hat Summit, Boston
– Enterprise data management foundations: The benefit of Red Hat platforms for enterprise workloads, Bob Ward
May 23-25: Microsoft Build, Seattle & Online
– Increase developer velocity with Azure SQL Database, from data to API
– Modernize your applications on Azure SQL Managed Instance Q&A
– Do more on Azure SQL Database Hyperscale Q&A
– Protect your data from tampering with ledger in Azure Managed Instance
– Further, Faster, with Azure Functions and Azure SQL Integration
Blogs to follow
There are a lot of blogs that I follow to stay up to date. If you want more details than I give here, I recommend checking out:
Anna’s Pick of the Month
You’ve been hearing a lot about OpenAI and ChatGPT. My pick of the month comes from Valentina Alto, who wrote a super fascinating blog which details how you can use Azure OpenAI and Azure SQL Database to query your SQL tables. You don’t want to miss it!
Until next time…
That’s it for now! Be sure to check back next month for the latest updates. We also release new episodes of Data Exposed on Thursdays at 9AM PT and new #MVPTuesday episodes on the last Tuesday of every month at 9AM PT at aka.ms/DataExposedyt.
Having trouble keeping up? Be sure to follow us on twitter to get the latest updates on everything, @AzureSQL.
We hope to see you next time, on Data Exposed :)
–Anna and Marisa
by Contributed | May 3, 2023 | Technology
This article is contributed. See the original author and article here.
Today, we’re announcing the availability of a much-requested feature for IT administrators planning and deploying Windows feature and quality updates—email alerts! Starting today, you can get notified about Windows known issues documented in the Windows release health section of the Microsoft 365 admin center. This enables you to easily and quickly learn about issues related to Windows updates and make informed decisions about rolling out an update across your environment.
When you sign up, you’ll receive emails about new issues for the versions of the Windows operating system you support, as well as updates to known issues such as:
- Changes in issue status
- New workarounds
- Issue resolution
This new feature is available to IT admins with a Windows or Microsoft 365 tenant, a subscription that provides access to Windows release health in the Microsoft 365 admin center[1], and an eligible admin role.
Watch this short video for a quick step-by-step on how to set up email notifications for Windows known issues.
Let’s get started!
Check your prerequisites
First, log in to the Microsoft 365 admin center and locate Windows release health under the Health menu. If you don’t see this option or don’t have access to the admin center, contact your organization’s global admin and request access and an admin role in the tenant.
Windows release health in the Microsoft 365 admin center is available to those with an admin role for an organization/tenant with an eligible Windows or Microsoft 365 for Business subscription[1]. By default, the person who purchased your organization’s Microsoft business subscription is the global admin. For more information on admin roles, see Assign admin roles in the Microsoft 365 admin center.
How to subscribe
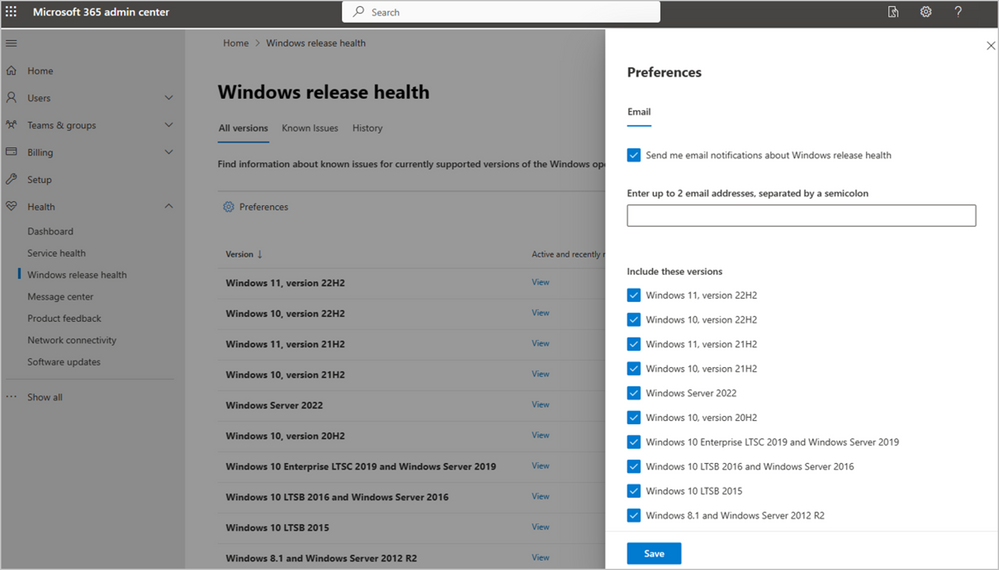
To sign up for email notifications about Windows known issues, visit Windows release health in the Microsoft 365 admin center. Once there, select Preferences > Email and select Send me email notifications about Windows release heath. From there, do the following:
- Enter up to two email addresses to receive the notifications. Each admin can set their own preferences. The limit of two email addresses is per admin account. Addresses can include distribution lists, so you can keep colleagues in your organization informed of issues even if they don’t have access to the admin center.
- Select which Windows versions you want to be notified about. If your organization supports multiple versions of Windows, we recommend selecting all that apply.
Lastly, don’t forget to select Save.
Screenshot showing the Windows release health page and preferences for email setup, including the list of supported Windows versions to check off.
Please note that if a single known issue affects more than one version of Windows, you’ll only receive one email. So, there’s no need to worry about duplicate emails, even if you sign up for multiple versions.
You can update your notification preferences anytime. Simply visit the same Windows release health page, select Preferences, and change the Windows versions, the email addresses subscribed, or choose to stop receiving these emails.
Windows release health emails: information and structure
The notification body will include the full content published about the issue in the Windows release health section of the Microsoft 365 admin center. With a quick glance, you’ll be informed of the status of the issue, as well as versions affected. You’ll find links to view the message in the admin center. When available, the text will include links to resources with additional information, along with associated KB articles that can address or resolve an issue.
Share your feedback
Have suggestions about how we can improve our communications about issues? We welcome your feedback. While looking at a known issue in the admin center, select Is this post helpful? and share your thoughts and suggestions. We appreciate your collaboration!
Join us for more demos and discussion
We are actively working on improvements to Windows release health on Microsoft Learn and the Microsoft 365 admin center—now we want to share what’s new in these experiences!
Register for our May 24th webinar to learn about the latest capabilities and when/where we share information about Windows known issues, safeguard holds, hardening changes, monthly updates, lifecycle updates, and new versions of Windows. Share your feedback. Bring your questions. Get informed and help us shape the future of these experiences!
Now it’s easier than ever to stay up to date on Windows known issues and make informed decisions about deploying updates in your organization. Visit admin.microsoft.com and sign in with your Microsoft 365 account to get started. Please let us know your opinion about this email feature in the comments below!
Continue the conversation. Find best practices. Bookmark the Windows Tech Community and follow us @MSWindowsITPro on Twitter. Looking for support? Visit Windows on Microsoft Q&A.
[1]Requires one of the following subscriptions: Microsoft 365 Enterprise E3/A3/F3, Microsoft 365 Enterprise E5/A5, Windows 10 Enterprise E3/A3, Windows 10 Enterprise E5/A5, Windows 11 Enterprise E3/A3, or Windows 11 Enterprise E5/A5.

Recent Comments