by Contributed | May 22, 2023 | Technology
This article is contributed. See the original author and article here.
First, big kudos to Martin for crafting this amazing playbook and co-authoring this blogpost.
Be sure to check out his SAP-focused blog for more In-Depth Insights!
The purpose of this blog post is to demonstrate how the SOAR capabilities of Sentinel can be utilized in conjunction with SAP by leveraging Microsoft Sentinel Playbooks/Azure Logic Apps to automate remedial actions in SAP systems or SAP Business Technology Platform (BTP).
Before we dive into the details of the SOAR capabilities in the Sentinel SAP Solution, let’s take a step back and take a very quick run through of the Sentinel SAP Solution.
The Microsoft Sentinel SAP solution empowers organizations to secure their SAP environments by providing threat monitoring capabilities. By seamlessly collecting and correlating both business and application logs from SAP systems, this solution enables proactive detection and response to potential threats. At its core, the solution features a specialized SAP data-connector that efficiently handles data ingestion, ensuring a smooth flow of information. In addition, an extensive selection of content, comprising analytic rules, watchlists, parsers, and workbooks, empowers security teams with the essential resources to assess and address potential risks.
In a nutshell: With the Microsoft Sentinel SAP solution, organizations can confidently fortify their SAP systems, proactively safeguarding critical assets and maintaining a vigilant security posture.
For a complete (and detailed) overview of what is included in the Sentinel SAP solution content, see Microsoft Docs for Microsoft Sentinel SAP solution
Now back to the SOAR capabilities! About a year ago, we published a blog post titled “How to use Microsoft Sentinel’s SOAR capabilities with SAP“, which discussed utilizing playbooks to react to threats in your SAP systems.
The breakthrough which the blogpost talked about was the use of Sentinel’s SOAR (Security Orchestration and Automated Response) capabilities on top of the Sentinel SAP Solution.
This means that we can not only monitor and analyze security events in real-time, we can also automate SAP incident response workflows to improve the efficiency and effectiveness of security operations.
In the previous blog post, we discussed blocking suspicious users using a gateway component, SAP RFC interface, and GitHub hosted sources.
In this post, we showcase the same end-to-end scenario using a playbook that is part of the OOB content of the SAP Sentinel Solution.
And rest assured, no development is needed – it’s all about configuration! This approach significantly reduces the integration effort, making it a smooth and efficient process!
Overview & Use case
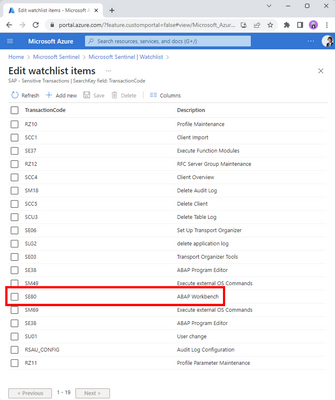
Let me set the scene: you’re the defender of your company’s precious SAP systems, tasked with keeping them safe. Suddenly Sentinel warns you that someone is behaving suspiciously on one of the SAP systems. A user is trying to execute a highly sensitive transaction in your system. Thanks to your customization of the OOB “Sensitive Transactions” watchlist and enablement of the OOB rule “SAP – Execution of a Sensitive Transaction Code”, you’re in the loop whenever the sensitive transaction SE80 is being executed. You get an instant warning, and now it’s time to investigate the suspicious behavior.
Sensitive Transactions watchlist with an entry for SE80
As part of the security signal triage process, it might be decided to take action against this problematic user and to (temporarily) kick-out them out from ERP, SAP Business Technology Platform or even Azure AD. To accomplish this, you can use the automatic remediation steps outlined in the OOB playbook “SAP Incident handler- Block User from Teams or Email”.
 Screenshot for the OOB SAP playbook
Screenshot for the OOB SAP playbook
By leveraging an automation rule and the out-of-the-box playbook, you can effectively respond to potential threats and ensure the safety and security of your systems. Specifically, in this blog post, we will use the playbook to promptly react to the execution of the sensitive transaction SE80, employing automation to mitigate any risks that may arise.
Now, it’s time to dive deeper into this OOB playbook! Let’s examine it closely to better understand how it works and how it can be used in your environment.
Deep dive into the playbook
To start off, we’ll break down the scenario into a step-by-step flow.
 Overview of the SAP user block scenario
Overview of the SAP user block scenario
The core of this playbook revolves around adaptive cards in Teams (see step 5 in the overview diagram), and relies on waiting for a response from engineers. As we covered earlier, Sentinel detects a suspicious transaction being executed (steps 1-4), and an automation rule is set up as a response to the “SAP – Execution of a Sensitive Transaction Code” analytic rule. This sets everything in motion, and the adaptive cards in Teams play a crucial role in facilitating communication between the system and the engineers.
 Adaptive card for a SAP incident offering to block the suspicious user
Adaptive card for a SAP incident offering to block the suspicious user
As demonstrated in the figure above (which correspond to step 5 in the step-by-step flow), engineers are presented with the option to block the suspicious user (Nestor in this case!) on SAP ERP, SAP BTP or on Azure AD.
Let’s dive into this part of the playbook design to see how it works behind the scenes.:
 Screenshot for block user action in the playbook
Screenshot for block user action in the playbook
In the screenshot you’ll notice three distinct paths for the “block user” action, each influenced by the response received in Teams. Of particular interest in this blog is the scenario where blocking a user on SAP ERP is required. This task is achieved through SOAP, providing an efficient means to programmatically lock a backend user using RFC (specifically BAPI_USER_LOCK).
When it comes to sending SOAP requests to SAP, there are various options available. Martin’s blog post provides a comprehensive explanation of these options, offering detailed technical insights and considerations. To avoid duplicating information, I encourage you to head over there for valuable insights on sending the SOAP requests.
When reacting to the adaptive cards, we recommend providing a clear and meaningful comment when blocking a user. This comment will be shared back to Sentinel for auditing and helping security operations understand your decision. The same applies when flagging false positives, as it helps Sentinel learn and differentiate between real threats and harmless incidents in the future.
 Screenshot of updated close reason on Sentinel fed with comment from Teams
Screenshot of updated close reason on Sentinel fed with comment from Teams
And there you have it, a lightning-fast rundown of how (parts of) this amazing playbook works!
Final words
And that’s a wrap for this blog post!
But hold on, don’t leave just yet, we’ve got some important closing statements for you:
- Remember that you have the flexibility to customize this playbook to fit your specific needs. Feel free to delete, add, or modify steps as necessary. We encourage you to try it out on your own and see how it works in your environment!
- For those who want to dive even deeper into the technical details (especially regarding SAP), be sure to check out Martin’s blog post. As the expert who designed this playbook, he provides an in-depth explanation of how to configure SAP SOAP interfaces, the authorizations for the target Web Service and RFC and much more! Trust me, it’s a fascinating read and you’re sure to learn a lot!
- On a related note, Martin has also created another playbook that automatically re-enables the audit trail to prevent accidental turn-offs. This playbook is now accessible through the content hub as well.
- And finally, for those who made it all the way to the end, we hope you enjoyed reading this blog post as much as we enjoyed writing it. Now go forth and automate your security like a boss!
by Contributed | May 21, 2023 | Technology
This article is contributed. See the original author and article here.
How to force filtering on at least one criterion
Another case for using dynamic M parameters and functions
Scenario
Recently I encountered the following issue working with a customer:
- There are two main ways to slice the data before visualizing it in a PBI report.
- The user can filter by one column or two columns coming from two different dimension tables.
- If there is no selection on any of the two columns, the queries fail on lack of resources to perform all the joins and summaries.
- While moving from filtering on one column to filtering on the other column, it is very natural to move through a state in which both filters are open, and the queries are very expensive and eventually fail.
- The goal was to prevent these cases and not to attempt a query with no filtering.
We need to allow multiple selection and also allow for selecting all values in any of the slicers, but we can’t require selection in at least one of the two.
We could create a measure that will return blank if no selection is applied but this will not prevent the query from being executed to calculate the list of items on the visuals.
Solution
Using data in the help cluster, we’ll create a PBI report that will demonstrate a solution to our problem.
The data volume is not so big so the report will return values even if no selection is applied but we want to prevent this kind of query and force a selection on one filter at least.
The two columns used are cities and colors in the two dimension tables Customers and Products respectively.
We start by creating a function with two parameters, one with a list of cities and one with a list of colors.
The function returns all rows that fit the criteria.
A special value will be sent in the parameters if no selection was made, or all values are selected.
The function
.create-or-alter function FilterColorsCities(ColorsList:dynamic,CitiesList:dynamic) {
let Catchall=”__SelectAll__”;
SalesFact
| where not(Catchall in (ColorsList) and Catchall in(CitiesList))
| lookup kind=inner
(Customers | where CityName in(CitiesList) or Catchall in(CitiesList))
on CustomerKey
| lookup kind=inner
(Products | where ColorName in (ColorsList) or Catchall in(ColorsList))
on ProductKey
}
The function applies a filter on the main table that will return 0 rows if both lists include the special value “__SelectAll__”.
At this point, the query will apply the lookups but will terminate immediately and will not use any resources.
Each one of the joined table is filtered by the list of values and the special value returns all values.
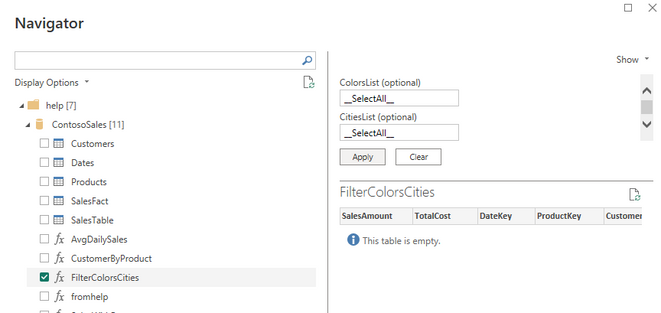
You can see the function in the help cluster.
In Power BI
We will navigate to the function and provide the special value “__SelectAll__” as default values for both parameters:
We create two parameters two replace the default values in the step that invokes the function


We use the Customers table and the Products table to create lists of cities and of colors by removing all other columns and removing duplicate rows.
It is recommended to use these tables in Dual mode.
Each column in these two tables is bound of one of the two parameters.

We need to allow multiple selection and allow selecting all values.
The default special value representing all values is the same as the default value if no selection is done.
Final report
Any kind of visuals can use the data returned by the function.
A measure is created to notify the user that a selection is needed.
Empty = if(countrows(FilterColorsCities)=0,”No selection, please select either cities or colors”,””)
A button is added to the page that will apply all filters after a selection.

Summary
Using KQL functions in conjunction with M dynamic parameters allow more control on the order of operations in the query and in some cases can block runaway queries that can drain resources and affect other users.
by Contributed | May 19, 2023 | Technology
This article is contributed. See the original author and article here.
Introduction
AKS or Azure Kubernetes Service is a fully managed Kubernetes container orchestration service that enables you to deploy, scale, and manage containerized applications easily. However, even with the most robust systems issues can arise that require troubleshooting.
This blog post marks the beginning of a three-part series, that originated from an intensive one-day bootcamp focused on advanced AKS networking triage and troubleshooting scenarios. It offers a practical approach to diagnosing and resolving common AKS networking issues, aiming to equip readers with quick troubleshooting skills for their AKS environment.
Each post walks through a set of scenarios that simulate typical issues. Detailed setup instructions will be provided to build a functional environment. Faults will then be introduced that causes the setup to malfunction. Hints will be provided on how to triage and troubleshoot these issues using common tools such as kubectl, nslookup, and tcpdump. Each scenario concludes with fixes for the issues faced and explanation of the steps taken to resolve the problem.
Prerequisites
Before setting up AKS, ensure that you have an Azure account and subscription, with permissions that allows you to create resource groups and deploy AKS clusters. PowerShell needs to be available as PS scripts will be used. Follow instructions provided in this Github link to set up AKS and run scenarios. It is also recommended that you read up on troubleshooting inbound and outbound networking scenarios that may arise in your AKS environment.
For inbound scenarios, troubleshooting connectivity issues pertains to applications hosted on the AKS cluster. Link describes issues related to firewall rules, network security groups, or load balancers, and provides guidance on verifying network connectivity, checking application logs, and examining network traffic to identify potential bottlenecks.
For outbound access, troubleshooting scenarios are related to traffic leaving the AKS cluster, such as connectivity issues to external resources like databases, APIs, or other services hosted outside of the AKS cluster.
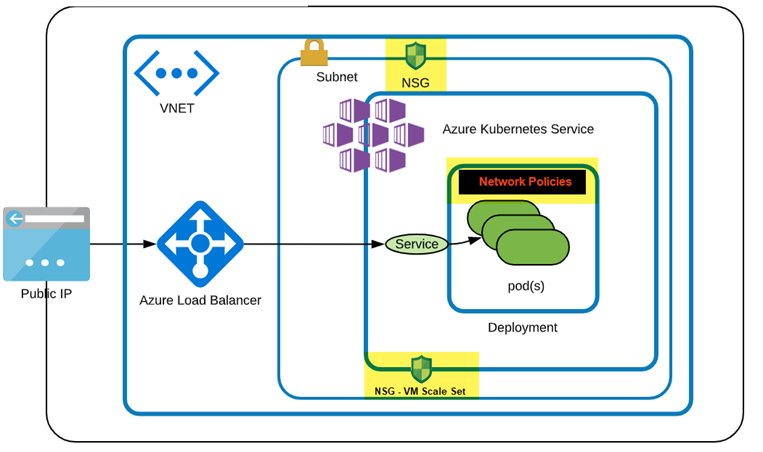
Figure below shows the AKS environment, which uses a custom VNet with its own NSG attached to the custom subnet. The AKS setup uses the custom subnet and will have its own NSG created and attached to the Network Interface of the Nodepool. Any changes to the AKS networking are automatically added to its NSG. However, to apply AKS NSG changes to the custom Subnet NSG, they must be explicitly added.
Scenario 1: Connectivity resolution between pods or services in same cluster
Objective: The goal of this exercise is to troubleshoot and resolve connectivity between pods and services within the same Kubernetes cluster.
Layout: AKS cluster layout with 2 Pods created by their respective deployments and exposed using Cluster IP Service.

Step 1: Set up the environment
- Setup up AKS as outlined in this script.
- Create namespace student and set context to this namespace
kubectl create ns student
kubectl config set-context –current –namespace=student
# Verify current namespace
kubectl config view –minify –output ‘jsonpath={..namespace}’
- Clone solutions Github link and change directory to Lab1 i.e., cd Lab1.
Step 2: Create two deployments and respective services
- Create a deployment nginx-1 with a simple nginx image:
kubectl create deployment nginx-1 –image=nginx
- Expose the deployment as a ClusterIP service:
kubectl expose deployment nginx-1 –name nginx-1-svc –port=80 –target-port=80 –type=ClusterIP
- Repeat the above steps to create nginx-2 deployment and a service:
kubectl create deployment nginx-2 –image=nginx
kubectl expose deployment nginx-2 –name nginx-2-svc –port=80 –target-port=80 –type=ClusterIP
Confirm deployment and service functional. Pods should be running and services listening on Port 80.
kubectl get all
Step 3: Verify that you can access both services from within the cluster by using Cluster IP addresses
# Services returned: nginx-1-svc for pod/nginx-1, nginx-2-svc for pod/nginx-2
kubectl get svc
# Get the values of and
kubectl get pods
# below should present HTML page from nginx-2
kubectl exec -it — curl nginx-2-svc:80
# below should present HTML page from nginx-1
kubectl exec -it — curl nginx-1-svc:80
# check endpoints for the services
kubectl get ep
Step 4: Backup existing deployments
- Backup the deployment associated with nginx-2 deployment:
kubectl get deployment.apps/nginx-2 -o yaml > nginx-2-dep.yaml
- Backup the service associated with nginx-2 service:
kubectl get service/nginx-2-svc -o yaml > nginx-2-svc.yaml
Step 5: Simulate service down
- Delete nginx-2 deployment
kubectl delete -f nginx-2-dep.yaml
- Apply the broken.yaml deployment file found in Lab1 folder
kubectl apply -f broken.yaml
- Confirm all pods are running
kubectl get all
Step 6: Troubleshoot the issue
Below is the inbound flow. Confirm every step from top down.

- Check the health of the nodes in the cluster to see if there is a node issue
kubectl get nodes
- Verify that you can no longer access nginx-2-svc from within the cluster
kubectl exec -it — curl nginx-2-svc:80
# msg Failed to connect to nginx-2-svc port 80: Connection refused
- Verify that you can access nginx-1-svc from within the cluster
kubectl exec -it — curl nginx-1-svc:80
# displays HTML page
- Verify that you can access nginx-2 locally. This confirms no issue with the nginx-2 application.
kubectl exec -it — curl localhost:80
# displays HTML page
- Check the Endpoints using below command and verify that the right Endpoints line up with their Services. There should be at least 1 Pod associated with a service, but none seem to exist for nginx-2 service but nginx-2 service/pod association is fine.
kubectl get ep

- Check label selector used by the Service experiencing issue, using below command:
kubectl describe service
Ensure that it matches the label selector used by its corresponding Deployment using describe command:
kubectl describe deployment
Use ‘k get svc’ and ‘k get deployment’ to get service and deployment names.
Do you notice any discrepancies?
- Using the Service label selector from #3, check that the Pods selected by the Service match the Pods created by the Deployment using the following command
kubectl get pods –selector=
If no results are returned then there must be a label selector mismatch.
From below figure, selector used by deployment returns pods but not the selector used by corresponding service.

- Check service and pod logs and ensure HTTP traffic is seen. Compare nginx-1 pod and service logs with nginx-2. Latter does not show GET requests, suggesting no incoming traffic.
k logs pod/ # no incoming traffic
k logs pod/ # HTTP traffic as seen below
k logs svc/
k logs svc/

Step 7: Restore connectivity
- Check the label selector the Service is associated with and get associated pods:
# Get label
kubectl describe service nginx-2-svc
# When attempting to obtain pods using the service label, results in “no resources found” or “no pods available”.
kubectl describe pods -l app=nginx-2
- Update deployment and apply changes.
kubectl delete -f nginx-2-dep.yaml
In broken.yaml, update labels ‘app: nginx-02’, to ‘app: nginx-2’, as shown below

kubectl apply -f broken.yaml # or apply dep-nginx-2.yaml
k describe pod
k get ep # nginx-2 svc should have pods unlike before
- Verify that you can now access the newly created service from within the cluster:
# Should return HTML page from nginx-2-svc
kubectl exec -it — curl nginx-2-svc:80
# Confirm above from logs
k logs pod/
Step 8: Using Custom Domain Names
Currently Services in your namespace ‘student’ will resolve using ..svc.cluster.local.
Below command should return web page.
k exec -it — curl nginx-2-svc.student.svc.cluster.local
- Apply broken2.yaml in Lab1 folder and restart CoreDNS
kubectl apply -f broken2.yaml
kubectl delete pods -l=k8s-app=kube-dns -n kube-system
# Monitor to ensure pods are running
kubectl get pods -l=k8s-app=kube-dns -n kube-system
- Validate if DNS resolution works and it should fail wit ‘curl: (6) Could not resolve host:’
k exec -it — curl nginx-2-svc.student.svc.cluster.local
k exec -it — curl nginx-2-svc
- Check the DNS configuration files in kube-system which shows the configmap’s, as below.
k get cm -A -n kube-system | grep dns
- Describe each of the ones found above and look for inconsistencies
k describe cm coredns -n kube-system
k describe cm coredns-autoscaler -n kube-system
k describe cm coredns-custom -n kube-system
- Since the custom DNS file holds the breaking changes, either edit coredns-custom and remove data section OR delete the ConfigMap ‘coredns-custom’. Deleting kube-dns pods should re-create deleted ConfigMap ‘coredns-custom’.
kubectl delete cm coredns-custom -n kube-system
kubectl delete pods -l=k8s-app=kube-dns -n kube-system
# Monitor to ensure pods are running
kubectl get pods -l=k8s-app=kube-dns -n kube-system
- Confirm DNS resolution now works as before.
kubectl exec -it — curl nginx-2-svc.student.svc.cluster.local
# Challenge lab: Resolve using FQDN aks.com #
# Run below command to get successful DNS resolution
k exec -it — curl nginx-2-svc.aks.com
# Solution #
k apply -f working2.yaml
kubectl delete pods -l=k8s-app=kube-dns -n kube-system
# Monitor to ensure pods are running
kubectl get pods -l=k8s-app=kube-dns -n kube-system
# Confirm working using below cmd
k exec -it — curl nginx-2-svc.aks.com
# Bring back to default
k delete cm coredns-custom -n kube-system
kubectl delete pods -l=k8s-app=kube-dns -n kube-system
# Monitor to ensure pods are running
kubectl get pods -l=k8s-app=kube-dns -n kube-system
Step 9: What was in the broken files
In broken.yaml deployment labels didn’t match up with the service i.e., it should have been nginx-2

In broken2.yaml breaking changes were made that resolved ‘student.svc.cluster.local’ to ‘bad.cluster.local’, which broke DNS resolution.
$kubectl_apply=@”
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns-custom
namespace: kube-system
data:
internal-custom.override: | # any name with .server extension
rewrite stop {
name regex (.*).svc.cluster.local {1}.bad.cluster.local.
answer name (.*).bad.cluster.local {1}.svc.cluster.local.
}
“@
$kubectl_apply | kubectl apply -f –
Step 10: Cleanup
k delete deployment/nginx-1 deployment/nginx-2 service/nginx-1-svc service/nginx-2-svc
or just delete namespace > k delete ns student
Scenario 2: DNS and External access failure resolution
Objective: The goal of this exercise is to troubleshoot and resolve Pod DNS lookups and DNS resolution failures.
Layout: Cluster layout as shown below has NSG applied to AKS subnet, with Network Policies in effect.

Step 1: Set up the environment
- Setup up AKS as outlined in this script.
- Create and switch to the newly created namespace
kubectl create ns student
kubectl config set-context –current –namespace=student
# Verify current namespace
kubectl config view –minify –output ‘jsonpath={..namespace}’
- Clone solutions Github link and change directory to Lab2 i.e., cd Lab2.
Step 2: Verify DNS Resolution works within cluster
- Create pod for DNS validation within Pod
kubectl run dns-pod –image=nginx –port=80 –restart=Never
kubectl exec -it dns-pod — bash
# Run these commands at the bash prompt
apt-get update -y
apt-get install dnsutils -y
exit
- Test and confirm DNS resolution resolves to the correct IP address.
kubectl exec -it dns-pod — nslookup kubernetes.default.svc.cluster.local
Step 3: Break DNS resolution
- From Lab2 folder apply broken1.yaml
kubectl apply -f broken1.yaml
- Confirm running below command results in ‘connection timed out; no servers could be reached’
kubectl exec -it dns-pod — nslookup kubernetes.default.svc.cluster.local
Step 4: Troubleshoot DNS Resolution Failures
- Verify DNS resolution works within the AKS cluster
kubectl exec -it dns-pod — nslookup kubernetes.default.svc.cluster.local
# If response ‘connection timed out; no servers could be reached’ then proceed below with troubleshooting
- Validate DNS service which should show port 53 in use
kubectl get svc kube-dns -n kube-system
- Check logs for pods associated with kube-dns
$coredns_pod=$(kubectl get pods -n kube-system -l k8s-app=kube-dns -o=jsonpath='{.items[0].metadata.name}’)
kubectl logs -n kube-system $coredns_pod
- If a custom ConfigMap is present, verify that the configuration is correct.
kubectl describe cm coredns-custom -n kube-system
- Check for networkpolicies currently in effect. If DNS related then describe and confirm no blockers. If network policy is a blocker then have that removed.
kubectl get networkpolicy -A
NAMESPACE NAME POD-SELECTOR
kube-system block-dns-ingress k8s-app=kube-dns
kubectl describe networkpolicy block-dns-ingress -n kube-system
# should show on Ingress path not allowing DNS traffic to UDP 53
- Remove the offending policy
kubectl delete networkpolicy block-dns-ingress -n kube-system
- Verify DNS resolution works within the AKS cluster. Below is another way to create a Pod to execute task as nslookup and delete on completion
kubectl run -it –rm –restart=Never test-dns –image=busybox –command — nslookup kubernetes.default.svc.cluster.local
# If the DNS resolution is working correctly, you should see the correct IP address associated with the domain name
- Check NSG has any DENY rules that might block port 80. If exists, then have that removed
# Below CLI steps can also be performed as a lookup on Azure portal under NSG
Step 5: Create external access via Loadbalancer
- Expose dns-pod with service type Load Balancer.
kubectl expose pod dns-pod –name=dns-svc –port=80 –target-port=80 –type LoadBalancer
- Confirm allocation of External-IP.
kubectl get svc
- Confirm External-IP access works within cluster.
kubectl exec -it dns-pod — curl
- Confirm from browser that External-IP access fails from internet to cluster.
curl
Step 6: Troubleshoot broken external access via Loadbalancer
- Check if AKS NSG applied on the VM Scale Set has an Inbound HTTP Allow rule.
- Check if AKS Custom NSG applied on the Subnet has an ALLOW rule and if none then apply as below.
$custom_aks_nsg = “custom_aks_nsg” # <- verify
$nsg_list=az network nsg list –query “[?contains(name,’$custom_aks_nsg’)].{Name:name, ResourceGroup:resourceGroup}” –output json
# Extract Custom AKS Subnet NSG name, NSG Resource Group
$nsg_name=$(echo $nsg_list | jq -r ‘.[].Name’)
$resource_group=$(echo $nsg_list | jq -r ‘.[].ResourceGroup’)
echo $nsg_list, $nsg_name, $resource_group
$EXTERNAL_IP=””
az network nsg rule create –name AllowHTTPInbound `
–resource-group $resource_group –nsg-name $nsg_name `
–destination-port-range 80 –destination-address-prefix $EXTERNAL_IP `
–source-address-prefixes Internet –protocol tcp `
–priority 100 –access allow
- After ~60s, confirm from browser that External-IP access succeeds from internet to cluster.
curl
Step 7: What was in the broken files
Broken1.yaml is a Network Policy that blocks UDP ingress requests on port 53 to all Pods

Step 8: Cleanup
k delete pod/dns-pod
or
k delete ns student
az network nsg rule delete –name AllowHTTPInbound `
–resource-group $resource_group –nsg-name $nsg_name
Conclusion
This post demonstrates common connectivity and DNS issues that can arise when working with AKS. The first scenario focuses on resolving connectivity problems between pods and services within the Kubernetes cluster. We encountered issues where the assigned labels of a deployment did not match the corresponding pod labels, resulting in non-functional endpoints. Additionally, we identified and rectified issues with CoreDNS configuration and custom domain names. The second scenario addresses troubleshooting DNS and external access failures. We explored how improperly configured network policies can negatively impact DNS traffic flow. In the next article, second of the three-part series, we will delve into troubleshooting scenarios related to endpoint connectivity across virtual networks and tackle port configuration issues involving services and their corresponding pods.
Disclaimer
The sample scripts are not supported by any Microsoft standard support program or service. The sample scripts are provided AS IS without a warranty of any kind. Microsoft further disclaims all implied warranties including, without limitation, any implied warranties of merchantability or of fitness for a particular purpose. The entire risk arising out of the use or performance of the sample scripts and documentation remains with you. In no event shall Microsoft, its authors, or anyone else involved in the creation, production, or delivery of the scripts be liable for any damages whatsoever (including, without limitation, damages for loss of business profits, business interruption, loss of business information, or other pecuniary loss) arising out of the use of or inability to use the sample scripts or documentation, even if Microsoft has been advised of the possibility of such damages.
by Contributed | May 18, 2023 | Technology
This article is contributed. See the original author and article here.
Code Optimizations: A New AI-Based Service for .NET Performance Optimization
We are thrilled to announce that Code Optimizations (previously known as Optimization Insights) is now available in public preview! This new AI-based service can identify performance issues and offer recommendations specifically tailored for .NET applications and cloud services.
What is Code Optimizations?
Code Optimizations is a service within Application Insights that continuously analyzes profiler traces from your application or cloud service and provides insights and recommendations on how to improve its performance.
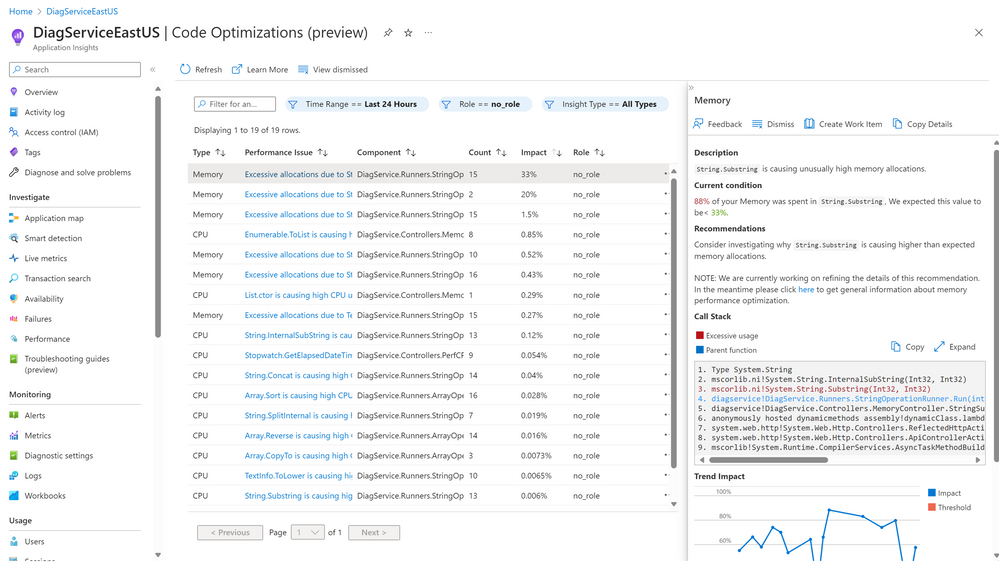
Code Optimizations can help you identify and solve a wide range of performance issues, ranging from incorrect API usages and unnecessary allocations all the way to issues relating to exceptions and concurrency. It can also detect anomalies whenever your application or cloud service exhibits abnormal CPU or Memory behavior.
Code Optimizations Page
Why should I use Code Optimizations?
Code Optimizations can help you optimize the performance of your .NET applications and cloud services by:
- Saving you time and effort: Instead of manually sifting through gigabytes of profiler data or relying on trial-and-error methods, you can use Code Optimizations to automatically uncover complex performance bugs and get guidance on how to solve them.
- Improving your user experience: By improving the speed and reliability of your application or cloud service, you can enhance your user satisfaction and retention rates. This can also help you gain a competitive edge over other apps or services in your market.
- Saving you money: By fixing performance issues early and efficiently, you can reduce the need for scaling out cloud resources or paying for unnecessary compute power. This can help you avoid problems such as cloud sprawling or overspending on your Azure bill.
How does Code Optimizations work?
Code Optimizations relies on an AI model trained on thousands of traces collected from Microsoft-owned services around the globe. By learning from these traces, the model can glean patterns corresponding to various performance issues seen in .NET applications and learn from the expertise of performance engineers at Microsoft. This enables our AI model to pinpoint with accuracy a wide range of performance issues in your app and provide you with actionable recommendations on how to fix them.
Code Optimizations runs at no additional cost to you and is completely offline to the app. It has no impact on your app’s performance.
How can I use Code Optimizations?
If you are interested in trying out this new service for free during its public preview period, you can access it using the following steps:
- Sign up for Application Insights if you haven’t already. Application Insights is a powerful application performance monitoring (APM) tool that helps you monitor, diagnose, and troubleshoot your apps.
- Enable profiling for your .NET app or cloud service. Profiling collects detailed information about how your app executes at runtime.
- Navigate to the Application Insights Performance blade from the left navigation pane under Investigate and select Code Optimizations from the top menu.
 Link to Code Optimizations from Application Insights: Performance
Link to Code Optimizations from Application Insights: Performance
Click here for the documentation.
Click here for information on troubleshooting.
Fill out this quick survey if you have any additional issues or questions.
by Contributed | May 17, 2023 | Technology
This article is contributed. See the original author and article here.
Microsoft has been on a journey to harness the power of artificial intelligence to help security teams scale more effectively. Microsoft 365 Defender correlates millions of signals across endpoints, identities, emails, collaboration tools, and SaaS apps to identify active attacks and compromised assets in an organization’s environment. Last year, we introduced automatic attack disruption, which uses these correlated insights and powerful AI models to stop some of the most sophisticated attack techniques while in progress to limit lateral movement and damage.
Today, we are excited to announce the expansion of automatic attack disruption to include adversary-in-the-middle attacks (AiTM) attacks, in an addition to the previously announced public preview for business email compromise (BEC) and human-operated ransomware attacks.
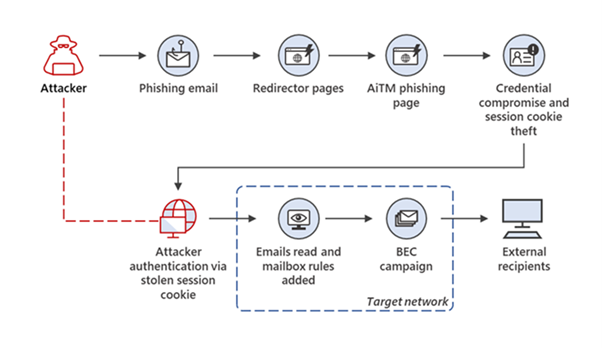
AiTM attacks are a widespread and can pose a major risk to organizations. We are observing a rising trend in the availability of adversary-in-the-middle (AiTM) phishing kits for purchase or rent, with our data showing that over organizations have already been attacked in 2023.
During AiTM attacks (Figure 1), a phished user interacts with an impersonated site created by the attacker. This allows the attacker to intercept credentials and session cookies and bypass multifactor authentication (MFA), which can then be used to initiate other attacks such as BEC and credential harvesting.
Automatic attack disruption does not require any pre-configuration by the SOC team. Instead, it’s built in as a capability in Microsoft’s XDR.
Figure 1. Example of an AiTM phishing campaign that led to a BEC attack
How Microsoft’s XDR automatically contains AiTM attacks
Similarly to attack disruption of BEC and human-operated ransomware attacks, the goal is to contain the attack as early as possible while it is active in an organization’s environment and reduce its potential damage to the organization. AiTM attack disruption works as follows:
- High-confidence identification of an AiTM attack based on multiple, correlated Microsoft 365 Defender signals.
- Automatic response is triggered that disables the compromised user account in Active Directory and Azure Active Directory.
- The stolen session cookie will be automatically revoked, preventing the attacker from using it for additional malicious activity.
 Figure 2. An example of a contained AiTM incident, with attack disruption tag
Figure 2. An example of a contained AiTM incident, with attack disruption tag
To ensure SOC teams have full control, they can configure automatic attack disruption and easily revert any action from the Microsoft 365 Defender portal. See our documentation for more details.
Get started
- Make sure your organization fulfills the Microsoft 365 Defender pre-requisites
- Connect Microsoft Defender for Cloud Apps to Microsoft 365.
- Deploy Defender for Endpoint. A free trial is available here.
- Deploy Microsoft Defender for Identity. You can start a free trial here.
Learn more

Recent Comments