by Contributed | Jun 13, 2022 | Technology
This article is contributed. See the original author and article here.
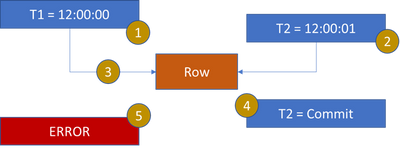
When 2 or more workers are modifying the same row, it is possible to encounter 13535. The time of the begin transaction and the modification are the defining properties. When the transaction begin time is before the latest row modification, error 13535 is encountered.
- T1 starts a transaction
T1 is context switched or client has not submitted the modification request
- T2 starts a transaction, just after T1
T2 updates the row in the table
- T1 attempts to update row and is blocked by T2 or T2 commits transaction before T1 issues the modification
- T2 commits the transaction
- T1 is assigned the lock
T1 detects the temporal update for the row was at 12:00:01 but T1 started its transaction before 12:00:01 and the error is raised.
For such an issue the application needs to determine the desired behavior. If T1 must complete before T2 then the application must sequence and complete the T1 query before the T2 query. If serialization is not required, the application can perform a retry.
DEMO
set nocount on
go
use master
go
drop database temporalTest
go
create database temporalTest
go
use temporalTest
go
create schema Test
go
CREATE TABLE [Temporal](
[TemporalId] [bigint] IDENTITY(1,1) NOT NULL,
[DateModified] [datetime2](7) NOT NULL,
[SysStartTime] [datetime2](7) GENERATED ALWAYS AS ROW START NOT NULL,
[SysEndTime] [datetime2](7) GENERATED ALWAYS AS ROW END NOT NULL,
CONSTRAINT [TemporalId] PRIMARY KEY CLUSTERED ([TemporalId] ASC)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON),
PERIOD FOR SYSTEM_TIME ([SysStartTime], [SysEndTime])
)WITH(
SYSTEM_VERSIONING = ON ( HISTORY_TABLE = [Test].[TemporalHistory] )
)
go
create PROCEDURE mysp
@ID bigint
AS
UPDATE
Temporal
SET
DateModified = GETUTCDATE()
WHERE
TemporalId = @Id
go
INSERT INTO Temporal
(DateModified) VALUES (GETUTCDATE())
go
select * from Temporal
go
select * from Test.TemporalHistory
go
— ostress -E -S.sql19 -Q”temporalTest..mysp 1″ -r999999999 -n4 -q

by Contributed | Jun 13, 2022 | Business, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Disruptive echo effects, poor room acoustics, and choppy videos are some common issues that can detract from the effectiveness of online calls and meetings. Through AI and machine learning, which have become fundamental to our strategy for continual improvement, we’ve delivered innovative enhancements in Microsoft Teams to address audio and video challenges in ways that are both user-friendly and scalable across environments. Today, we’re excited to cover some common meeting scenarios and the AI and machine learning audio and video improvements enabled in Teams.
The post How Microsoft Teams uses AI and machine learning to improve calls and meetings appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | Jun 12, 2022 | Technology
This article is contributed. See the original author and article here.
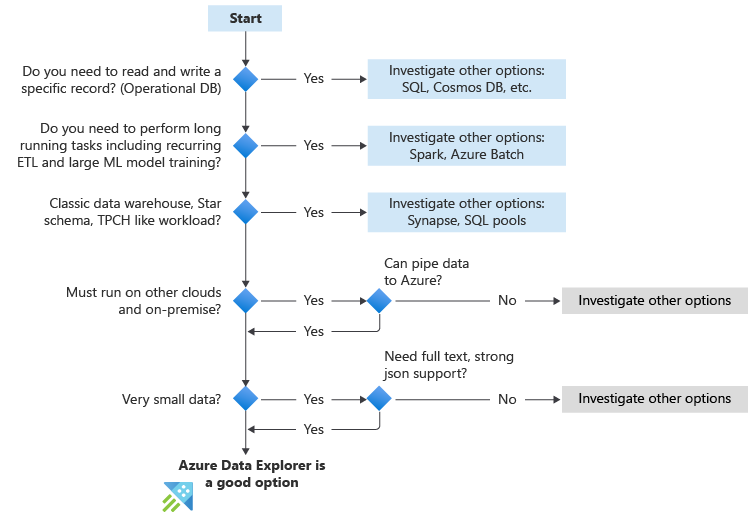
Azure Data Explorer is a big data interactive analytics platform that empowers people to make data driven decisions in a highly agile environment. The factors listed below can help assess if Azure Data Explorer is a good fit for the workload at hand. These are the key questions to ask yourself.
The following flowchart table summarize the key questions to ask when you’re considering using Azure Data Explorer.
Guidance summary
The following table shows how to evaluate new use cases. While this doesn’t cover all use cases, we think it can help you make a decision if Azure Data Explorer is the right solution for you.
Use case |
Interactive Analytics |
Big data (Variety, Velocity, Volume) |
Data organization |
Concurrency |
Build vs Buy |
Should I use Azure Data Explorer? |
|---|
Implementing a Security Analytics SaaS |
Heavy use of interactive, near real-time analytics |
Security data is diverse, high volume and high velocity. |
Varies |
Often multiple analysts from multiple tenants will use the system |
Implementing a SaaS offering is a Build scenario |
Yes |
CDN log analytics |
Interactive for troubleshooting, QoS monitoring. |
CDN logs are diverse, high volume and high velocity. |
Separate log records. |
May be used by a small group of data scientists but may also power many dashboards |
The value extracted from CDN analytics is scenario-specific and requires custom analytics |
Yes |
Time series database for IoT Telemetry |
Interactive for troubleshooting, analyzing trends, usage, detecting anomalies |
IoT telemetry are high velocity but may be structured only or medium in size |
Related sets of records. |
May be used by a small group of data scientists but may also power many dashboards |
When searching for a database, context is typically “build” |
Yes |
Read more on When to use Azure Data Explorer (Kusto)
by Contributed | Jun 10, 2022 | Technology
This article is contributed. See the original author and article here.
At Supercomputing 2019, we announced HBv2 virtual machines (VMs) for HPC with AMD EPYC™ ‘Rome’ CPUs and the cloud’s first use of HDR 200 Gbps InfiniBand networking from NVIDIA Networking (formerly Mellanox). HBv2 VMs have proven very popular with HPC customers on a wide variety of workloads, and have powered some of the most advanced at-scale computational science ever on the public cloud.
Today, we’re excited to share that we’re making HBv2 VMs even better. By taking learnings from our efforts to optimize HBv3 virtual machines, we will soon be enhancing the HBv2-series in the following ways:
- simpler NUMA topology for application compatibility
- better HPC application performance
- new constrained core VM sizes to better fit application core-count or licensing requirements
- Fixing a known issue that prevented offering HBv2 VMs with 456 GB of RAM
This article details the changes we will soon make to the global HBv2 fleet, what the implications are for HPC applications, and what actions we advise so that customers can smoothly navigate this transition and get the most out of the upgrade.
Overview of Upgrades to HBv2
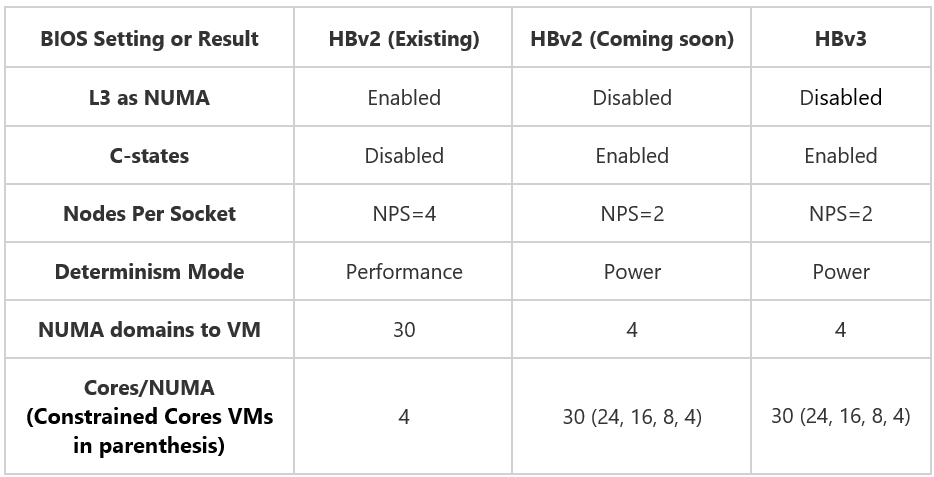
The BIOS of all HBv2 servers will be upgraded with the platform changes tabulated below. These upgrades bring the BIOS configurations of HBv3 (already documented in HBv3 VM Topology) and HBv2 in alignment with one another, and in doing synchronize so how the hardware topology appears and operates within the VM.
Simpler NUMA topology for HPC Applications
A notable improvement will be a significant reduction in NUMA complexity presented into customer VMs. To date, HBv2 VMs have featured 30 NUMA domains (4-cores per NUMA). After the upgrade, every HBv2 VM will feature a much simpler 4 NUMA configuration. This will help assist customer applications that do not function correctly nor optimally with a many-NUMA hardware topology.
In addition, while there will be no hard requirement to use HBv2 VMs any differently than before, the best practice for pinning processes to optimize performance and performance consistency will change. From an application runtime perspective, the existing HBv2 process pinning guidance will no longer apply. Instead, optimal process pinning for HBv2 VMs will be identical to what we already advise for HBv3 VMs. By adopting this guidance, users will gain the following benefits:
- Best performance
- Best performance consistency
- Single configuration approach across both HBv3 and HBv2 VMs (for customers that want to use HBv2 and HBv3 VMs as a fungible pool of compute)
Better HPC workload performance
These changes will also result in higher performance across a diverse set of HPC workloads due to enhancements to peak single-core boost clock frequencies, and better memory interleaving. In our testing, the upgrade to HBv2 VMs improve representative memory bandwidth-bound and compute-bound HPC workloads by as much as 8-15%:

Constrained Core VM sizes
Finally, soon after the BIOS changes are made to HBv2 servers we will introduce four new constrained core VM sizes. See below for details:

*Due to the architecture of Zen2-based CPUs like EPYC 2nd Generation, the 16-core HBv2 VM size only exposes 256 MB out of a possible 512 MB of L3 cache within the server
As with HBv3 VMs, constrained cores VM sizes for the HBv2-series will enable customers to right-size the core count of their VMs on the spectrum of maximum performance per core (16-core VM size) to maximum performance per VM (120 core VM size). Across all VM sizes, global shared assets like memory bandwidth, memory capacity, L3 cache, InfiniBand, local SSD, etc. remain constant. Doing so increases how those assets are allocated on a per-core basis. In HPC, common scenarios for which this is useful include:
- Providing more memory bandwidth per CPU core for CFD workloads.
- Allocating more L3 cache per core for RTL simulation workloads.
- Driving higher CPU frequencies to fewer cores in license-bound scenarios.
- Giving more memory or local SSD to each core.
Fixing Known Issue with Memory Capacity in HBv2 VMs
The upgrade will also address a known issue from late 2021 that required a reduction from the previously offered 456 GB of RAM per HBv2 VM to only 432 GB. After the upgrade is complete, all HBv2 VMs will once again feature 456 GB of RAM.
Navigating the Transition
Customers will be notified via the Azure Portal shortly before the upgrade process begins across the global HBv2 fleet. From that point forward any new HBv2 VM deployments will land on servers featuring the new configuration.
Because many scalable HPC workloads, especially tightly coupled workloads, expect a homogenous configuration across compute nodes, we *strongly advise* against mixing HBv2 configurations for a single job. As such, we recommend that once the upgrade has rolled out across the fleet that customers with VM deployments from before the upgrade began (and thus still utilizing servers with the prior BIOS configuration) de-allocate and re-allocate their VMs so that the have a homogenous pool of HBv2 compute resources.
As part of notifications sent via the Azure portal, we will also advise customers visit the Azure Documentation site for the HBv2-series virtual machines where all changes will be provided in greater detail.
We are excited to bring these enhancements to HBv2 virtual machines to our customers across the world. We’re also happy to take customer questions and feedback by contacting us at Azure HPC Feedback.
by Contributed | Jun 10, 2022 | Technology
This article is contributed. See the original author and article here.
Establishing trust around the integrity of data stored in database systems has been a longstanding problem for all organizations that manage financial, medical, or other sensitive data. Ledger is a new feature in Azure SQL and SQL Server that incorporates blockchain crypto technologies into the RDBMS to ensure the data stored in a database is tamper evident. In this session of Data Exposed with Anna Hoffman and Pieter Vanhove, we will cover the basic concepts of Ledger and how it works, Ledger tables, and digest management, and database verification.
Resources:
Ledger Whitepaper

Recent Comments