
by Contributed | Jan 25, 2023 | Business, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Today, we’re announcing the general availability of Office 365 Government Secret cloud, which includes our first release of Office 365 Government capabilities including Exchange, Outlook, and Microsoft 365 Apps.
The post Office 365 Secret cloud now available for US national security missions appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.
by Contributed | Jan 24, 2023 | Technology
This article is contributed. See the original author and article here.
We have heard feedback that with so many commands it can be challenging to remember the exact syntax or learn new cmdlets, so we are enabling a solution to make the experience easier.
We are excited to announce that we have enabled Predictive IntelliSense in PSReadLine and the predications from Azure PowerShell Az.Tools.Predictor module.
Beginning February 2023 Azure Cloud Shell uses the version of PSReadLine that has Predictive IntelliSense enabled by default. We’ve also installed and enabled the Azure PowerShell predictor Az.Tools.Predictor module. Together, these changes enhance the command-line experience by providing suggestions that help new and experienced users of Azure discover, edit, and execute complete PowerShell commands.
What is Predictive IntelliSense?
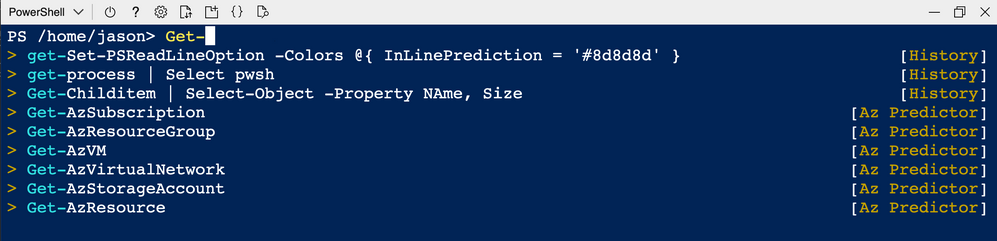
Predictive IntelliSense is a feature of the PSReadLine module. It provides suggestions for complete commands based on items from your history and from predictor modules, like Az.Tools.Predictor.
Prediction suggestions appear as colored text following the user’s cursor. The image below shows the default InlineView of the suggestion. Pressing RightArrow key accepts an inline suggestion. After accepting the suggestion, you can edit the command line before hitting Enter to run the command.

PSReadLine also offers a ListView presentation of the suggestions.
In ListView mode, use the arrow keys to scroll through the available suggestions. List view also shows the source of the prediction.
You can switch between InlineView and ListView by pressing the F2 key.
Where can I learn more?
For more information about how to customize predictions for Cloud Shell, see Cloud Shell Predictive IntelliSense.
Learn more about how Az.Tools.Predictor uses intelligent context-aware command completion to help you navigate cmdlets and parameters for the Az PowerShell module.
To learn more about PSReadLine and managing Predictive Intellisense, see Using predictors in PSReadLine.
Where can I make suggestions?
We welcome suggestions and feedback to your experience working with Azure Cloud Shell. Please help us learn your feedback by posting issues and suggestions to our Azure Cloud Shell GitHub.
by Contributed | Jan 23, 2023 | Technology
This article is contributed. See the original author and article here.
The idea on this blog post came from an issue opened by an user on the Windows Containers GitHub Repo. I thought the problem faced by the user should be common enough that others might be interested in a solution.
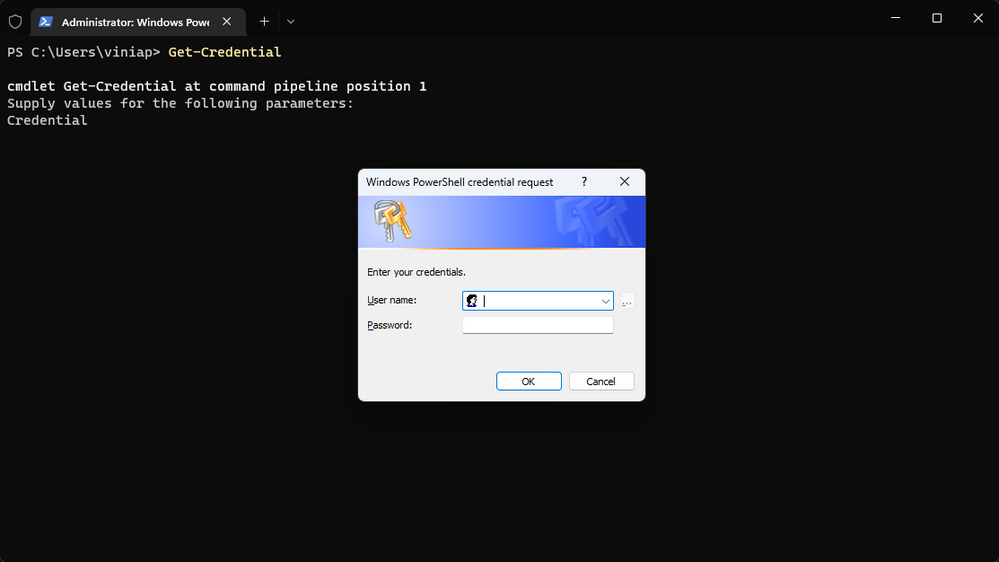
Get-Credential cmdlet pop-up
If you use PowerShell, you most likely came across the Get-Credential cmdlet at some point. It’s extremely useful for situations on which you want to set a username and password to be used in a script, variable, etc.. However, the way Get-Credential works is by providing a pop-up window for you to enter the credentials:
On a traditional Windows environment, this is totally fine as the pop-up window shows up, you enter the username and password, and save the information. However, on a Windows container there’s no place to display the pop-up window:

As you can see on the image above, the command hangs waiting for the confirmation, but nothing happens as the pop-up is not being displayed. Even typing CRTL+C doesn’t work. In my case, I had to close the PowerShell window, which left the container in an exited state.
Changing the Get-Credential behavior
To work around this issue, you can change the PowerShell policy to accept credential input from the console session. Here’s the script for that workaround:
$key = "HKLM:SOFTWAREMicrosoftPowerShell1ShellIds"
Set-ItemProperty -Path $key -Name ConsolePrompting -Value $true
The next time you use the Get-Credential cmdlet, it will ask for the username and password on the console session:

On the example above, I simply entered the username and password for the Get-Credential cmdlet. You could, obviously, save that on a variable for later use.
While this workaround solves the problem of not being able to use the Get-Credential cmdlet on Windows containers, it’s obviously not ideal. The information from the product team is that they are looking into making this the default option for Windows containers in the future – although, no timelines are available at this moment.
I hope this is useful to you! Let us know in the comments!
by Contributed | Jan 22, 2023 | Technology
This article is contributed. See the original author and article here.
In some situations, we saw that our customers are trying to export their database to a blob storage that is behind a firewall, currently this operation is not supported Export a database to a BACPAC file – Azure SQL Database & Azure SQL Managed Instance | Microsoft Learn
Exporting a database we need to review some considerations in terms of storage:
- If you are exporting to blob storage, the maximum size of a BACPAC file is 200 GB. To archive a larger BACPAC file, export to local storage with SqlPackage.
Exporting a BACPAC file to Azure premium storage using the methods discussed in this article is not supported.
Storage behind a firewall is currently not supported.
Immutable storage is currently not supported.
Storage file name or the input value for StorageURI should be fewer than 128 characters long and cannot end with ‘.’ and cannot contain special characters like a space character or ‘,*,%,&,:,,/,?’.
Trying to perform this operation you may received an error message: Database export error Failed to export the database: . ErrorCode: undefined ErrorMessage: undefined-
by Contributed | Jan 21, 2023 | Technology
This article is contributed. See the original author and article here.
We used to have situations where our customer needs to export 2 TB of data using SQLPackage in Azure SQL Database. Exporting this amount of data might take time and following we would like to share with you some best practices for this specific scenario.
- If you’re exporting from General Purpose Managed Instance (remote storage), you can increase remote storage database files to improve IO performance and speed up the export.
- Temporarily increase your compute size.
- Limit usage of database during export (like in Transactional consistency scenario consider using dedicated copy of the database to perform the export operation)
- Use a Virtual Machine in Azure with Accelerated Networking in Azure and in the same region of the database.
- Use as a folder destination and temporal file with a enough capacity and SSD to improve the exported file performance and multiple temporary files created.
- Consider using a clustered index with non-null values on all large tables. With clustered index, export can be parallelized, hence much more efficient. Without clustered indexes, export service needs to perform table scan on entire tables in order to export them, and this can lead to time-outs after 6-12 hours for very large tables.
- Review the following articles:
- Besides the diagnostic parameter in SQLPackage , you could see how are the queries is running enabling SQL Auditing in this database or using SQL Server Profiler extension in Azure Data Studio.
Enjoy!

Recent Comments