
by Contributed | Mar 11, 2023 | Technology
This article is contributed. See the original author and article here.
How to Participate:
Step 1: Don’t miss this amazing opportunity, register for the Student Summit here
Step 2: Complete this Cloud Skill challenge here https://aka.ms/StudentSummitSouthAfrica
Step 3: Fill the Official Rul Form https://aka.ms/SSNGWPRules.
Microsoft Student Summit Watch Party South Africa
When: Wednesday, March 22, 2023, 9:30 AM – 2:00 PM (GMT+02:00)
Where: Johannesburg, Gauteng, South Africa
Microsoft Student Summit is an event designed for students and rising developers who are passionate about technology and eager to learn new skills and meet like-minded individuals. Attending the Microsoft Student Summit can provide students with a number of benefits, including:
Exposure to the Latest Technologies: The Microsoft Student Summit provides students with an opportunity to learn about and experience the latest Microsoft technologies, such as cloud computing and artificial intelligence.
Microsoft Learn: Microsoft Student Summit Cloud Skills Challenge are hands-on, allowing students to apply their knowledge and skills to real-world learning and challenges. This can be a valuable experience for students and rising developers who are looking to build their portfolios and demonstrate their abilities to future employers.
Career development: The Microsoft Student Summit can be a valuable resource for students who are interested in pursuing careers in technology. By attending the event, students can gain insights into the latest trends and innovations in the industry and connect with potential employers and recruiters.
Overall, the Microsoft Student Summit provides students and rising developers with a unique opportunity to learn and grow as individuals and technology professionals. Whether you are a beginner or an experienced technologist, the Microsoft Student Summit is a valuable investment in your future.
What is Student Summit?
Are you exploring a career in technology? Or looking to accelerate your technical career? Want to know what a “day in the life of” is really like before you dive in? Or get a jumpstart understanding the skills needed for success? Whether you are just starting your undergraduate degree or a seasoned professional curious about the tactical steps needed to accelerate your career, Microsoft Student Summit will help you discover how to gain expertise in today’s cutting-edge technology needed for your career.
What Will I Learn?
Tech
Discover the cutting edge of Application Development and Developer Tools, Low Code/ No-Code / Fusion Development, and AI, Data and Machine Learning and how to build your expertise start your learning journey with our Student Summit Cloud Skills Challenge.
Community
Tailored learning paths, upcoming networking events in your region, and invitations to join technical communities to help you deepen your technical expertise learn more at Microsoft Learn Student Hub.
Career
Career advice about how to start and accelerate your technical career from industry experts.
Additional Resources
Visit Microsoft Student Hub here: https://aka.ms/learnstudent

by Contributed | Mar 10, 2023 | Technology
This article is contributed. See the original author and article here.
Hello hello, everyone! Happy Friday!
Here’s a recap of what’s been going on in the MTC this week.
MTC Moments of the Week
To start things off, we want to first give a huge shoutout to this week’s MTC Member of the Week – @Kidd_Ip! Kidd is a MCT (Microsoft Certified Trainer) and full time IT pro who has made great contributions to a variety of Tech Community forums across Azure and M365. Way to go, Kidd!
Moving to events, on Wednesday, we had our first of two AMA’s. Azure Communication Services and Microsoft Teams joined forces for this event to talk about the possibilities of connecting Teams with the communication capabilities in Azure and the cool stuff we can build with it. A big thank you to our speakers @MilanKaur, @tchladek, and @dayshacarter for sharing your expertise!
Then on Thursday, we had our second AMA all about Windows Server – from upgrading older versions and the importance of regular updates, to the security features in the latest versions of Windows Server (2022). We received a lot of questions, which were answered by our panel of speakers from the Windows Servicing and Delivery team as well as Windows Server engineers and security product managers. Shout out to @Artem Pronichkin , @Rick Claus, @Scottmca, @Ned Pyle, @Rob Hindman, and the rest team for a great session!
And over on the Blogs, in honor of Women’s History Month, the Marketplace Community kicked off a series of interviews with women leaders in the ISV community. The first edition of this series features an interview between @justinroyal and Harmke Alkemade, AI Cloud Solution Architect at Microsoft and Co-Founder at Friendly Flows. We love to see it!
Upcoming Events – Mark Your Calendars!
———-
For this week’s fun fact…
Did you know that the concept of what we know today as “Spring Break” (in the US, at least) began in 1938, when a college swimming coach, Sam Ingram, brought his team down from New York to Fort Lauderdale, Florida in 1936 to train? When the word got around to other swim coaches, they followed suit, and it began an annual pilgrimage for swimmers from across the US to enjoy the sun – and have some fun. The more you know!
Have a great weekend, everyone, and don’t forget to spring forward on Sunday!

by Contributed | Mar 10, 2023 | Technology
This article is contributed. See the original author and article here.
Welcome to the conclusion of our series on OpenAI and Microsoft Sentinel! Back in Part 1, we introduced the Azure Logic Apps connector for OpenAI and explored the parameters that influence text completion from the GPT3 family of OpenAI Large Language Models (LLMs) with a simple use case: describing the MITRE ATT&CK tactics associated with a Microsoft Sentinel incident. Part 2 covered another useful scenario, summarizing a KQL analytics rule extracted from Sentinel using its REST API. In Part 3, we revisited the first use case and compared the Text Completion (DaVinci) and Chat Completion (Turbo) models. What’s left to cover? Well, quite a lot – let’s get started!
There is some incredible work happening every day by Microsoft employees, MVPs, partners, and independent researchers to harness the power of generative AI everywhere. Within the security field, though, one of the most important topics for AI researchers is data privacy. We could easily extract all entities from a Microsoft Sentinel incident and send them through OpenAI’s API for ChatGPT to summarize and draw conclusions – in fact, I’ve seen half a dozen new projects on GitHub just this week doing exactly that. It’s certainly a fun project for development and testing, but no enterprise SOC wants to export potentially sensitive file hashes, IP addresses, domains, workstation hostnames, and security principals to a third party without strictly defined data sharing agreements (or at all, if they can help it). How can we keep sensitive information private to the organization while still getting benefit from innovative AI solutions such as ChatGPT?
Enter Azure OpenAI Service!
Azure OpenAI Service provides REST API access to the same GPT-3.5, Codex, DALL-E 2, and other LLMs that we worked with earlier in this series, but with the security and enterprise benefits of Microsoft Azure. This service is deployed within your Azure subscription with encryption of data at rest and data privacy governed by Microsoft’s Responsible AI principles. Text completion models including DaVinci have been generally available on Azure OpenAI Service since December 14, 2022. While this article was being written, ChatGPT powered by the gpt-3.5-turbo model was just added to Preview. Access is limited right now, so be sure to apply for access to Azure OpenAI!
ChatGPT on Azure solves a major challenge in operationalizing generative AI LLMs for use in an enterprise SOC. We’ve already seen automation for summarizing incident details, related entities, and analytic rules – and if you’ve followed this series, we’ve actually built several examples! What’s next? I’ve compiled a few examples that I think highlight where AI will bring the most value to a security team in the coming weeks and months.
- As an AI copilot for SOC analysts and incident responders, ChatGPT could power a natural language assistant interfacing with security operators through Microsoft Teams to provide a common operating picture of an incident in progress. Check out Chris Stelzer’s innovative work with #SOCGPT for an example of this capability.
- ChatGPT could give analysts a head start on hunting for advanced threats in Microsoft 365 Defender Advanced Hunting by transforming Sentinel analytic rules into product-specific hunting queries. A Microsoft colleague has done some pioneering work with ChatGPT for purple-teaming scenarios, both generating and detecting exploit code – the possibilities here are endless.
- ChatGPT’s ability to summarize large amounts of information could make it invaluable for incident documentation. Imagine an internal SharePoint with summaries on every closed incident from the past two years!
There are still a few areas where ChatGPT, as innovative as it is, won’t replace human expertise and purpose-built systems. Entity research is one such example; it’s absolutely crucial to have fully defined, normalized telemetry for security analytics and entity mapping. ChatGPT’s models are trained on a very large but still finite set of data and cannot be relied on for real-time threat intelligence. Similarly, ChatGPT’s generated code must always be reviewed before being implemented in production.
I can’t wait to see what happens with OpenAI and security research this year! What security use cases have you found for generative AI? Leave a comment below!
by Contributed | Mar 9, 2023 | Technology
This article is contributed. See the original author and article here.
Processing health insurance claims can be quite complex. This complexity is driven by a few factors, such as the messaging standards, the exchange protocol, workflow orchestration, all the way to the ingestion of the claim information in a standardize and scalable data stores. To enable operational, financial, and patient-centric data analytics, the claims data stores are often mapped to patient health records at the cohort, organization, or even population level.
What is X12 EDI?
Electronic Data Interchange (EDI) defines a messaging mechanism for unified communication across different organizations. X12 claims based processing refers to a set of standards for electronic data interchange (EDI) used in the healthcare industry to exchange information related to health claims. The X12 standard defines a specific format for electronic transactions that allows healthcare providers, insurers (payers), and other stakeholders to exchange data in a consistent and efficient manner. This cross-industry standard is accredited by the American National Standards Institution (ANSI). For simplicity, we will refer to ‘X12 EDI’ as ‘X12’ throughout this article.
What is FHIR?
FHIR® (Fast Healthcare Interoperability Resources) is a standard for exchanging information in the healthcare industry through web-based APIs with a broad range of resources to accommodate various healthcare use cases. These resources include patient demographics, clinical observations, medications, claims and procedures to name a few. It aims to improve the quality and efficiency of healthcare by promoting interoperability between different systems.
Azure Health Data Services is a suite of purpose-built technologies for protected health information (PHI) in the cloud. The FHIR service in Azure Health Data Services enables rapid exchange of health data using the Fast Healthcare Interoperability Resources (FHIR®) data standard. As part of a managed Platform-as-a-Service (PaaS), the FHIR service makes it easy for anyone working with health data to securely store and exchange Protected Health Information (PHI) in the cloud.
Why Convert X12 to FHIR?
FHIR is a modern, developer-friendly, born-in-the-cloud data standard compared to the aging X12. Converting from X12 to FHIR has many merits; (1) take advantage of FHIR interoperability and adoption to exchange claim information across various systems using modern and secure protocols, (2) unification of patient health and claim dataset into a single FHIR service in the cloud (3) enjoy a larger community of developers and evolving ecosystem at the global healthcare stage.
The Azure Solution
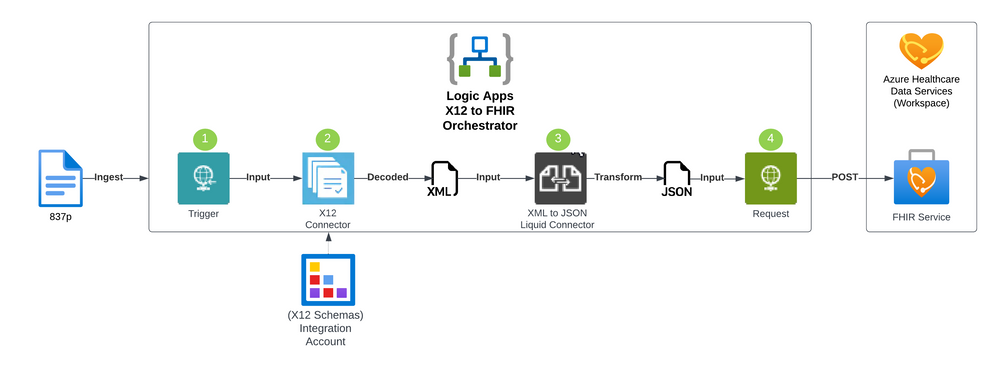
In essence, this article describes how to orchestrate the conversion of X12 claims to FHIR messages using Azure FHIR Service (with Azure Health Data Services), Azure Integration Account and Azure Logic Apps. Azure Logic Apps is a service within the Azure platform that enables developers to create workflows and automate business processes through the use of low-code/no-code visual and integration-based connectors. The service allows you to create, schedule, and manage workflows, that can be triggered by various events, such as receiving an HTTPS request or the arrival of a new file in an SFTP service. The Azure Integration Account is part of the Logic Apps Enterprise Integration Pack (EIP) and is a secure, manageable and scalable container for the integration artifacts that you create. The X12 XML Schema will be provided through the Azure Integration Account. The complete implementation of the X12 to FHIR conversion in Azure is available on GitHub.
Orchestration of X12 to FHIR Conversion
Azure Logic Apps orchestrates the conversion process from X12 to FHIR resources, allows for additional data quality checks, and then ingests the FHIR resources in the Azure FHIR Service as depicted in the following 4 steps:
X12 to FHIR
- First, we ingest the X12 file content into the Azure Logic Apps workflow. In this sample, we submit the X12 file content in the body of an HTTPS Post request to the HTTPS endpoint exposed by Azure Logic Apps.
- Initial data quality check and decoding is done using the Azure Logic Apps X12 connector leveraging the X12 XML schemas associated with the transaction sets. This step will verify that the sender is configured and enabled in the system and pick the correct agreement that is configured with the X12 schema. This schema is used to convert the X12 data to XML.
- Once the X12 file is validated and decoded into the XML format, the XML content can then be converted to FHIR using the Azure Logic Apps XML to JSON Liquid connector. This uses DotLiquid templates to map the XML content to the corresponding FHIR resources.
- The output of the workflow is to store the data in Azure FHIR Service (with Azure Health Data Services) to support a unified view of the patient’s record. The FHIR service supports an HTTP REST endpoint where individual resources can be managed or sent as an atomic transaction using a FHIR bundle.
FHIR Resources
Various FHIR resources can be generated from an X12 transaction set. Depending on business requirements and entities participating in the integration, these resources will vary.
Entity |
Resource |
Description |
Patient |
Patient |
The person who the claim is for. |
Sender |
Organization or Practitioner |
The organization or provider submitting the claim. |
Recipient |
Organization or Practitioner |
The organization or provider receiving the claim for processing. |
Claim |
Claim |
The details about the services, amounts, and codes associated with the claim. |
Transaction Set / Message |
Communication |
Metadata bout the X12 message including the raw message. |
Liquid Template Sample
A sample liquid template is provided showing how to extract data from the decoded X12 file. In the following snippet, the elements under ‘content’ correspond to XML elements in the decoded X12 file. The XML elements are being mapped to the ‘total’ attribute of the ‘Claim’ FHIR resource.
{
"resourceType": "Claim",
"status": "active",
"use": "claim",
"total": "{{content.FunctionalGroup.TransactionSet.X12_00501_835.TS835_2000_Loop.TS835_2100_Loop.CLP_ClaimPaymentInformation.CLP03_TotalClaimChargeAmount}}"
}
Considerations
- Patient and provider identifiers in the transaction set may not correspond directly to the FHIR identifiers for those matching resources. A lookup approach may be needed to map the data such as an EMPI (enterprise master patient index) and Provider Registry. These mappings can exist in a separate data store or using the FHIR Identifier data type for the corresponding FHIR resource.
- Various X12 EDI schemas may need to be managed across your provider base. Each version of the transaction set will have a corresponding Liquid template which will also need to be versioned to convert the correct XML to FHIR. An approach around modularizing templates will be crucial to find the right balance for reusability.
- Depending on the scale of the provider base and security requirements the architecture can be revised accordingly:
- One instance of Azure Logic Apps can be created per provider providing full compute isolation.
- Azure Logic Apps also support parallelization allowing for a batch of X12 files to be submitted and then processed in parallel.
- One instance of Azure Logic Apps and Azure FHIR Service can be associated with a certain geographic region which may be needed if data sovereignty is required.
- Depending on business scenario, the ingestion process can be trigger from an SFTP event. Health organizations and providers can be associated with an Azure Storage Account enabled with SFTP where they can securely connect and manage their X12 artifacts.
References

by Contributed | Mar 8, 2023 | Business, Microsoft 365, Technology
This article is contributed. See the original author and article here.
Inaccessible content is everywhere in the digital world. Today, we’re introducing Accessibility Assistant in Microsoft 365 to help creators produce more accessible content with less effort, all in the flow of work.
The post Create inclusive content with the new Accessibility Assistant in Microsoft 365 appeared first on Microsoft 365 Blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments