
by Scott Muniz | Sep 1, 2020 | Azure, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Hi, all! Rod Trent here. I am a Cybersecurity CE/Consultant at Microsoft and working with Azure Sentinel. I also blog for our Secure Infrastructure Blog and have quite a few Azure Sentinel articles posted there already.
As a general best practice, you want to configure access to Azure Sentinel resources through the Resource Group and you want to ensure you are providing only the access required i.e., using a least permissive model. Azure Sentinel resource access is applied using the following assignment roles…
 Azure Sentinel roles and allowed actions
Azure Sentinel roles and allowed actions
I talk about these roles, access, and best practices for access based on analyst levels quite often with our customers. Building security team members’ responsibilities is important and a critical part of the SOC workflow. However, one of the first things customers ask during this discussion is about Playbook usage. As you can see from the table above, to actually run Playbooks (apply automation), an analyst is required to have both Azure Sentinel contributor and Logic App contributor roles. Hmmm…so what if you want the Responder or Reader roles to perform automation?
Keep in mind that Playbooks are powerful. In the wrong hands, dangerous things can happen. Who really wants to accidentally lock the CEO out their login account because the password was forgotten, was typed in wrong 10 times in the last hour, and the HelpDesk was never called due to ego? But if it’s going to happen – even on purpose – it’s probably best for a seasoned analyst to take the blame for it. It could be a career-ending move for a Tier 1 analyst.
Creating Playbooks should go through a methodical, logical process. Only create a Playbook out of need and also ensure that the proper teams are involved during the design. Don’t automate just to automate. For example, for those situations where a Playbook causes a user account to be locked or a port to be blocked at the firewall, its best for the Security team to work with the Operations team to make sure it’s done correctly and effectively and that it’s gone through the proper authorizations. Think about it. By applying automation through Playbooks you are effectively shortcutting the Change Management process. Without proper vetting from the proper teams, bad things could happen both technically and politically. Oh…and feelings could be hurt, too. And, what’s worse than that?
So, after all the vetting has taken place and the authorization checkboxes have been ticked, you may determine that certain Playbooks are safe and they might fit a requirement to be run by those who don’t have the overarching Logic App contributor role or god-like powers in either Azure or Azure Sentinel. You probably don’t want a Tier 1 analyst who is assigned the lowly Azure Sentinel Reader role to be able to lockout users, but it might be beneficial for them to do something more simple like ensuring each open Incident has the IP GEO location applied.
Fortunately, since Playbooks are built on Logic Apps and Logic Apps provides the ability to set specific access per resource, you can assign specific Playbook access using Access Control (IAM).
Here’s an example…
In my Azure tenant I have a user account, Jaime Sommers, who has been assigned the Azure Sentinel Reader role. With that role Jaime is limited to only being able to view data in the Azure Sentinel console.
But I want Jaime to be able to add the GEO location to Incidents using the Get-GeoFromIpandTagIncident Playbook – but only THAT Playbook – and none of the others. That’s going to save our team time as our Tier 2 analysts gear up each day to determine which new Incidents they need to start investigating.
Through the Playbooks blade in the Azure Sentinel console, I access the Access Control (IAM) blade and assign the Logic Apps Contributor role specifically to the user account Jaime Sommers.
 Adding the Logic App Contributor role to a specific Playbook for a specific analyst
Adding the Logic App Contributor role to a specific Playbook for a specific analyst
Adding the Log Analytics Contributor role to a specific Playbook for a specific analyst
After a brief sync (it can sometimes take a minute or longer), when Jaime refreshes her Playbooks blade, she can now see the specific Playbook and can then use it to apply GEO location to an Incident she is working on.
 Playbook access for Jaime
Playbook access for Jaime
As you can see in the image above, the bottom screenshot example is Jaime without the specific Logic App Contributor role assigned and the top screenshot example is after she has been granted access to it.
Summary
And, even though Jaime is severely limited in what she can do in the Azure Sentinel console due to her lowly Azure Sentinel Reader role assignment, she can now run the Playbook and GEO is assigned to the Incident.
 Huzzah!
Huzzah!
* Check out my other blog for more Azure Sentinel content: Rod Trent at the Secure Infrastructure Blog
* Follow me on Twitter: https://twitter.com/rodtrent

by Scott Muniz | Sep 1, 2020 | Azure, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Introduction
With an ever-expanding ocean of data, more and more organizations need to perform advanced and fast analytics over their business data, logs, and telemetry while seeking to reduce costs. Many of them are shifting towards Azure Data Explorer (ADX) and taking advantage of the significant benefits it offers to analyze billions of records quickly and cost-effectively.
But sometimes they are already using other tools. One common scenario is that organizations are already using Elasticsearch, Logstash, and Kibana (The ELK Stack). Migration between big data platforms sounds like a long and complicated process. But that’s not always true. Switching from ELK to Azure Data Explorer offers the opportunity to significantly boost performance, reduce costs and improve the quality of insights by offering advanced query capabilities; all this without entering a long and complex migration, thanks to the tools described below.
This blog post covers the following topics:
- Why organizations are moving to Azure Data Explorer
- How you can use Azure Data Explorer with Kibana
- What additional tools for data exploration, visualizations, and dashboards are available
- How you can send data to Azure Data Explorer through Logstash (or other tools)
- How to use Logstash to migrate historical data from Elasticsearch to Azure Data Explorer
- Appendix: Step by step example – using Logstash to migrate historical data from Elasticsearch to Azure Data Explorer
1. Why organizations are moving to Azure Data Explorer
Azure Data Explorer is a highly scalable and fully managed data analytics service on the Microsoft Azure Cloud. ADX enables real-time analysis of large volumes of heterogeneous data in and allows rapid iterations of data exploration to discover relevant insights. In short, the advantages of ADX can be summed up using the three Ps: Power, Performance, Price.
Power
 Azure Data Explorer has a unique column-store inverted-index design. With the intuitive Kusto Query Language (KQL) you can query an enormous amount of data and perform ad-hoc analytics in seconds.
Azure Data Explorer has a unique column-store inverted-index design. With the intuitive Kusto Query Language (KQL) you can query an enormous amount of data and perform ad-hoc analytics in seconds.
Users state that they find it easier to find value and new insights from their data, using KQL. They are more engaged and understand the data better, since they can efficiently explore the data and run ad-hoc text parsing, create run-time calculated columns, aggregations, use joins, and plenty of other capabilities.
These capabilities are natively supported without the need to modify the data. You don’t have to pre-organize the data, pre-define scripted fields, or de-normalize the data. There is no need to manage and take care of the hierarchy of Indices, Types, and IDs.
Azure Data Explorer’s machine–learning capabilities can identify patterns that are not obvious and detect differences in data sets. With capabilities like time series analysis, anomaly detection, and forecasting, you can uncover hidden insights and easily point out issues or unusual relationships you may not even be aware of. You can also run inline Python and R as part of the queries.
Also, Azure Data Explorer supports many communication APIs and client libraries, all of which make programmatic access easy.
Performance
 As a fully managed service, Azure Data Explorer gives you best–in-class performance. You can get results from one billion records in less than a second without modifying the data or metadata. ADX can accept hundreds of billions of records a day and store this data reliably for months. ADX is specifically built to handle complex analytics queries on the data and return answers in a matter of seconds, even when the data is a combination of structured, semi-structured (JSON-like nested types), and unstructured (free text).
As a fully managed service, Azure Data Explorer gives you best–in-class performance. You can get results from one billion records in less than a second without modifying the data or metadata. ADX can accept hundreds of billions of records a day and store this data reliably for months. ADX is specifically built to handle complex analytics queries on the data and return answers in a matter of seconds, even when the data is a combination of structured, semi-structured (JSON-like nested types), and unstructured (free text).
Price
 Azure Data Explorer is a managed Platform as a Service (PaaS), so you can reduce the management and operations overhead and save the cost of purchasing and maintaining hardware. Auto–scale capabilities are available for better cost control. Due to the efficient data ingestion process and querying engine, compute resources are consumed wisely and economically. The inverted-index columns-store design enables ADX to have a superb data compression ratio, which reduces the amount of required storage, compared to other services. You can run as many queries as you need, thanks to the optimized cost structure, without incurring additional costs. In addition, ADX provides a granular cache policy that customers can set to differentiate between hot data cache and cold data cache, and get even more control over the costs.
Azure Data Explorer is a managed Platform as a Service (PaaS), so you can reduce the management and operations overhead and save the cost of purchasing and maintaining hardware. Auto–scale capabilities are available for better cost control. Due to the efficient data ingestion process and querying engine, compute resources are consumed wisely and economically. The inverted-index columns-store design enables ADX to have a superb data compression ratio, which reduces the amount of required storage, compared to other services. You can run as many queries as you need, thanks to the optimized cost structure, without incurring additional costs. In addition, ADX provides a granular cache policy that customers can set to differentiate between hot data cache and cold data cache, and get even more control over the costs.
You can configure and estimate the costs with our cost estimator.
2. How you can use Azure Data Explorer with Kibana
As announced in a separate blog post, we developed the K2Bridge (Kibana-Kusto Bridge), an open-source project that enables you to connect your familiar Kibana’s Discover tab to Azure Data Explorer. Starting with Kibana 6.8, you can store your data in Azure Data Explorer on the back end and use K2Bridge to connect to Kibana. This way, your end-users can keep using Kibana’s Discover tab as their data exploration tool.  Connect Kibana to Azure Data Explorer with K2Bridge
Connect Kibana to Azure Data Explorer with K2Bridge
3. What additional tools for data exploration, visualizations, and dashboards are available
Azure Data Explorer offers various other exploration and visualization capabilities that take advantage of the rich and built-in analyses options of KQL, including:
- Azure Data Explorer Web UI/Desktop application – to run queries, analyze and explore the data using powerful KQL queries.
- The KQL render operator offers various out-of-the-box visualizations such as tables, pie charts, anomaly charts, and bar charts to depict query results. Query visualizations are helpful in anomaly detection, forecasting, machine–learning scenarios, and more.
As described in the first chapter, you can efficiently run ad-hoc text parsing, create calculated columns, use joins and plenty of other capabilities, without any modifications or pre-organizations of the data.
- Azure Data Explorer dashboards – a web UI that enables you to run queries, build dashboards, and share them across your organization.
- Integrations with other dashboard services like Power BI and Grafana.
4. How you can send data to Azure Data Explorer through Logstash (or other tools)
Are you already using Logstash as the data pipeline? If so, redirecting the data to ADX is easy! You can use the open-source Logstash Output Plugin for Azure Data Explorer (a detailed example is described in the next chapter), and keep using the Logstash input plugin according to your specific source of the ongoing event stream, as you use it today. 
There are many other ways to ingest data into Azure Data Explorer, including:
- Ingestion using managed pipelines – using Azure Event Grid, Azure Data Factory (ADF), IoT Hub and Event Hub (Event Hub can receive data from several publishers, including Logstash and Filebeat, through Kafka).
- Ingestion using connectors and plugins – Logstash plugin, Kafka connector, Power Automate (Flow), Apache Spark connector
- Programmatic ingestion using SDKs
- Tools – LightIngest or One–click ingestion (a detailed example is described in the next chapter)
- KQL ingest control commands
For more information, please refer to the data ingestion overview.
5. How to use Logstash to migrate historical data from Elasticsearch to Azure Data Explorer
Choose the data you care about
When you decide to migrate historical data, it is a great opportunity to validate your data and needs. There is a good chance you can remove old, irrelevant, or unwanted data, and only move the data you care about. By migrating your freshest and latest data only, you can reduce costs and improve querying performance.
Usually, when organizations migrate from Elasticsearch to Azure Data Explorer, they do not migrate historical data at all. The approach is a “side-by-side” migration: they “fork” their current data pipeline and ingest the ongoing live data to Azure Data Explorer (by using Logstash/Kafka/Event Hub connectors, for example). Anyway, we show how you can migrate your historical data using Logstash. For efficiency, the Logstash output plugin section in the next examples contains a ‘query’ section in which you specify the data you care about and would like to export from Elasticsearch.
Data migration from Elasticsearch to Azure Data Explorer
Here we describe two methods to migrate historical data from Elasticsearch using Logstash. See the appendix for a step-by-step tutorial.
Method 1: Logstash and One-click Ingestion/LightIngest

Use Logstash to export the data from Elasticsearch into CSV or JSON file(s), and then use Azure Data Explorer’s One-Click Ingestion feature to ingest the data.
- This is an easy way to quickly ramp-up and migrate data because One-Click Ingestion automatically generates the destination table and the ingestion mapping based on the structure of the data source (of course, you can edit the table schema if you want to).
- One-Click Ingestion supports ingesting up to 1 GB at a time. To ingest a more massive amount of data, you can:
- Slice your data into multiple files and ingest them separately.
- Use LightIngest – a command-line utility for ad-hoc data ingestion. The utility can pull source data from a local folder (or from an Azure blob storage container).
- Use the second method described below.
Method 2: Using Logstash only (with the output plugin for Azure Data Explorer)

Use Logstash as a pipeline for both exporting data from Elasticsearch and ingesting it into Azure Data Explorer. When you use this method, you should manually create the Azure Data Explorer destination table and define the ingestion mapping. (You can automatically generate the destination table and the table mapping by using One-Click Ingestion with sample data, as described in method 1 first, and then use method 2 for the rest of the data)
In this blog post, we talked about the advantages of Azure Data Explorer, went over several visualizations options, including the open-source Kibana-Azure Data Explorer connector, and introduced a variety of ways you can ingest your ongoing data into Azure Data Explorer. Then, we presented two ways to migrate historical data from Elasticsearch to Azure Data Explorer.
In the appendix, you can find two step-by-step sample scenarios for historical data migration.
Please do not hesitate to contact our team or leave a comment if you have any questions or concerns.
Appendix: Step-by-step example of historical data migration
Method 1: Logstash and One–Click Ingestion
- Use Logstash to export the relevant data to migrate from Elasticsearch into a CSV or a JSON file. Define a Logstash configuration file that uses the Elasticsearch input plugin to receive events from Elasticsearch. The output will be a CSV or a JSON file.
- To export your data to a CSV file: use the CSV output plugin. For this example, the config file should look like this:
# Sample Logstash configuration: Elasticsearch -> CSV file
input {
# Read documents from Elasticsearch matching the given query
elasticsearch {
hosts => ["http://localhost:9200"]
index => "storm_events"
query => '{ "query": { "range" : { "StartTime" : { "gte": "2000-08-01 01:00:00.0000000", "lte": "now" }}}}'
}
}
filter {
ruby {
init => "
begin
@@csv_file = 'data-csv-export.csv'
@@csv_headers = ['StartTime','EndTime','EpisodeId','EventId','State','EventType']
if File.zero?(@@csv_file) || !File.exist?(@@csv_file)
CSV.open(@@csv_file, 'w') do |csv|
csv << @@csv_headers
end
end
end
"
code => "
begin
event.get('@metadata')['csv_file'] = @@csv_file
event.get('@metadata')['csv_headers'] = @@csv_headers
end
"
}
}
output {
csv {
# elastic field name
fields => ["StartTime","EndTime","EpisodeId","EventId","State","EventType"]
# This is path where we store output.
path => "./data-csv-export.csv"
}
}
This config file specifies that the ‘input’ for this process is the Elasticsearch cluster, and the ‘output’ is the CSV file.
- Implementation note:The filter plugin adds a header with the field names to the CSV file’s first line. This way, the destination table will be auto built with these column names. The plugin uses the ‘init’ option of the Ruby plugin to add the header at Logstash startup-time.
- Alternatively, you can export your data to a JSON file, using the file output format.
This is what our Logstash config file looks like:
# Sample Logstash configuration: Elasticsearch -> JSON file
input {
# Read documents from Elasticsearch matching the given query
elasticsearch {
hosts => ["http://localhost:9200"]
index => "storm_events"
query => '{ "query": { "range" : { "StartTime" : { "gte": "2000-08-01 01:00:00.0000000", "lte": "now" }}}}'
}
}
output {
file {
path => "./output_file.json"
codec => json_lines
}
}
- The advantage of using JSON over CSV is that later, with One–Click Ingestion, the Azure Data Explorer ‘create table’ and ‘create json mapping’ commands will be auto-generated for you. It will save you the need to manually create the JSON table mapping again (in case you want to ingest your ongoing data with Logstash later on. The Logstash output plugin uses json mapping).
- Start Logstash with the following command, from Logstash’s bin folder:
logstash -f pipeline.conf
- If your pipeline is working correctly, you should see a series of events like the following written to the console:

- The CSV/JSON file should be created at the destination you specified in the config file.
- Ingest your data into Azure Data Explorer with One–Click Ingestion:
- Open the Azure Data Explorer web UI. If this is the first time you are creating an Azure Data Explorer cluster and database, see this doc.
- Right–click the database name and select Ingest new Data.
- In the Ingest new data page, use the Create new option to set the table name.
- Select Ingestion type from a file and browse your CSV/JSON file.
- Select Edit schema. You will be redirected to the schema of the table that will be created.
- Optionally, on the schema page, click the column headers to change the data type or rename a column. You can also double-click the new column name to edit it.
For more information about this page, see the doc.
- Select Start Ingestion to ingest the data into Azure Data Explorer.
- After a few minutes, depending on the size of the data set, your data will be stored in Azure Data Explorer and ready for querying.
Method 2: Using Logstash only
- Create an Azure Data Explorer cluster and database.
Note: If you have already created your Azure Data Explorer cluster and database, you can skip this step.
More information on creating an Azure Data Explorer cluster and database can be found here.
-
Create the destination table.
Note: If you have already created your table with One-Click Ingestion, or in other ways, skip this step.
Tip: The One-Click Ingestion tool auto-generates the table creation and the table mapping commands, based on the structure of sample JSON data you provide. If you use One-Click Ingestion with a JSON file, as described above, you can use the auto-generated commands, from the Editor section.
 Auto-generate the table and its mapping using One-Click IngestionIn the Azure portal, under your cluster page, on the left menu, select Query (or use Azure Data Explorer Web UI/Desktop application) and run the following command. This command creates a table with the name ‘MyStormEvents’, with columns according to the schema of the data.
Auto-generate the table and its mapping using One-Click IngestionIn the Azure portal, under your cluster page, on the left menu, select Query (or use Azure Data Explorer Web UI/Desktop application) and run the following command. This command creates a table with the name ‘MyStormEvents’, with columns according to the schema of the data.
.create tables MyStormEvents(StartTime:datetime,EndTime:datetime,EpisodeId:int,EventId:int,State:string,EventType:string)
- Create ingestion mapping.
Note: If you used One-Click Ingestion with a JSON file, you can skip this step. This mapping is used at ingestion time to map incoming data to columns inside the ADX target table.
The following command creates a new mapping, named ‘mymapping’, according to the data’s schema. It extracts properties from the incoming temporary JSON on files, that will be automatically generated later, as noted by the path, and outputs them to the relevant column.
.create table MyStormEvents ingestion json mapping 'mymapping' '[{"column":"StartTime","path":"$.StartTime"},{"column":"EndTime","path":"$.EndTime"} ,{"column":"EpisodeId","path":"$.EpisodeId"}, {"column":"EventId","path":"$.EventId"}, {"column":"State","path":"$.State"},{"column":"EventType","path":"$.EventType "}]'
- Your table is ready to be ingested with data from your existing Elasticsearch index. To ingest the historical data from Elasticsearch, you can use the Elasticsearch input plugin to receive data from Elasticsearch, and the Azure Data Explorer (Kusto) output plugin to ingest the data to ADX.
- If you have not used Logstash, you should first install it
- Install the Logstash output plugin for Azure Data Explorer, which sends the data to Azure Data Explorer, by running:
bin/logstash-plugin install logstash-output-kusto
- Define a Logstash configuration pipeline file in your home Logstash directory.
In the input plugin, you can specify a query to filter your data according to a specific time range or any other search criteria. This way, you can migrate only the data you care about.
In this example, the config file looks as follows:
input {
# Read all documents from your Elasticsearch, from index “your_index_name”
elasticsearch {
hosts => ["http://localhost:9200"]
index => " your_index_name "
query => '{ "query": { "range" : { "StartTime" : {"gte": "2020-01-01 01:00:00.0000000", "lte": "now"}} } }'
}
}
output {
kusto {
path => "/tmp/kusto/%{+YYYY-MM-dd-HH-mm }.txt"
ingest_url => "https://<your cluster name>.<your cluster region>.kusto.windows.net”
app_id => "<Your app id>"
app_key => "<Your app key>"
app_tenant => "<Your app tenant>"
database => "<Your Azure Data Explorer DB name>"
table => "<Your table name>"
mapping => "<Yor mapping name>"
}
}
- Edit your configuration pipeline file according to your Azure Data Explorer cluster details and start Logstash with the following command, from Logstash’s bin folder:
logstash -f pipeline.conf
- If your pipeline is working correctly, you should see a series of events like the following written to the console:
- After a few minutes, run the following Azure Data Explorer query to see the records in the table you defined:
MyStormEvents | count
The result is the number of records that were ingested into the table. It might take several minutes to ingest the entire dataset, depending on the size of the data set. The result of this query reflects the quantity of ingested records. Your data is now stored in Azure Data Explorer and is ready for querying!

by Scott Muniz | Sep 1, 2020 | Azure, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
With this article, which is part of our recent Azure Security Center (ASC): Secure Score Blog Post Series, we are diving into the Enable Endpoint Protection security control. This security control contains up to 11 recommendations, depending on the resources you have deployed within your environment, and it is worth a maximum of 2 points that count towards your Secure Score. More information about Secure Score can be found here.
Why enabling endpoint protection?
After making sure that your VMs’ management ports are protected, as Kerinne explained in her article, you have already made a huge step towards securing your infrastructure from unauthorized access. However, malware cannot only be downloaded or installed by unauthorized actors, but also inadvertently by legitimate users who are supposed to access your machines. Once a machine is compromised, it could start downloading malware, sending SPAM, execute crypto mining activities, and so on. So, protecting network endpoints is an important step towards enhancing your security posture, but it is not the only security feature that needs to be implemented. With an Endpoint Protection solution, you make sure that if malicious code is found, you have a higher likelihood that it will be detected.
You can find more details about supported endpoint protection solutions here.
Recommendations within the Enable Endpoint Protection security control
The Enable Endpoint Protection security control contains the following 11 recommendations, depending on your environment and agent status:
- Install endpoint protection solution on virtual machines
- Install endpoint protection solution on your machines
- Endpoint protection solution should be installed on virtual machine scale sets
- Endpoint protection health failures should be remediated on virtual machine scale sets
- Endpoint protection health issues should be resolved on your machines
- Monitoring agent should be installed on virtual machine scale sets
- Monitoring agent should be installed on your machines
- Monitoring agent should be installed on your virtual machines
- Log Analytics agent should be installed on your Windows-based Azure Arc machines (Preview)
- Log Analytics agent should be installed on your Linux-based Azure Arc machines (Preview)
- Monitoring agent health issues should be resolved on your machines
The screenshot below shows an environment in which only 7 of those 11 recommendations are within the scope of the Enable endpoint protection security control.
 Figure 1 – Recommendations within the Enable Endpoint Protection security control
Figure 1 – Recommendations within the Enable Endpoint Protection security control
This is because recommendations which do not apply to any resource within your environment do not appear. Basically, the recommendations that can be part of the control can be reduced to four main categories:
Category #1: Install the Log Analytics agent
Azure Security Center relies on the Log Analytics agent to gain information about a server’s current operating system status, events, logfiles, but it is also used to check if a supported endpoint protection solution has been installed on a machine. So, having the monitoring agent installed is mandatory for making sure that your machines are fully monitored and taking advantages of the Azure Security Center Threat Protection for VMs. For the installation, you can use different approaches, depending on what best fits your needs.
The following recommendations belong to this category:
- Monitoring agent should be installed on your virtual machines. This recommendation applies to VMs running in Azure.
- Monitoring agent should be installed on your machines applies to servers which are not running in Azure.
- Monitoring agent should be installed on virtual machine scale sets applies to VM scale sets in Azure
- Log Analytics agent should be installed on your Windows-based Azure Arc machines (Preview) applies to Windows-based Azure Arc machines
- Log Analytics agent should be installed on your Linux-based Azure Arc machines (Preview) applies to Linux-based Azure Arc machines
Category #2: Install one of the support endpoint protection solutions
Besides having the Log Analytics agent installed, of course you want to make sure to have one of the supported endpoint protection solutions installed on your machines. Once you have installed the solution, the particular recommendation that applies to your machine will no longer appear. Only the Microsoft Azure Antimalware solution can be installed directly from the ASC portal. The others need to be installed manually, but then are discovered by Azure Security Center. The following recommendations are part of this category:
- Install endpoint protection solution on virtual machines applies to VMs running in Azure.
- Install endpoint protection solution on your machines applies to machines outside of Azure
- Endpoint protection solution should be installed on virtual machine scale sets applies to VM Scale Sets in Azure.
Category #3: Make sure to resolve Log Analytics Agent health issues
This basically is a single recommendation that is aimed to showing you that one of your machines’ Log Analytics agent is no longer sending data to Azure. This could be an issue with the agent, like the process is no longer running and/or cannot be (re)started, or the machine itself might no longer be working as expected or is switched off. This category is made up of only one recommendation:
- Monitoring agent health issues should be resolved on your machines
We have published more information on possible Log Analytics agent health issues and how to troubleshoot them in the Azure Security Center Troubleshooting Guide.
Category #4: Make sure to resolve health issues with the endpoint protection solution
Besides health issues with the Log Analytics agent, Azure Security Center will also report health issues with the endpoint protection solution itself. Health issues include (but are not limited to) out of date signatures and misconfigured real-time protection, as shown in the following screenshot:
 Figure 2 – Remediate endpoint protection health issues
Figure 2 – Remediate endpoint protection health issues
The following recommendations belong to this final category:
- Endpoint protection health failures should be remediated on virtual machine scale sets
- Endpoint protection health issues should be resolved on your machines
Next steps
As with all security controls, you need to make sure to remediate all recommendations within the control that apply to a particular resource in order to gain credit towards your secure score. That means, that both, the Log Analytics agent, and the respective endpoint protection solution you want to use are installed, running, and securely configured. Now, go ahead and remediate the Enable endpoint protection security control in your environment!
Reviewer
Thank you to @Yuri Diogenes, Principal Program Manager in the CxE ASC Team for reviewing this article.
by Scott Muniz | Sep 1, 2020 | Azure, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
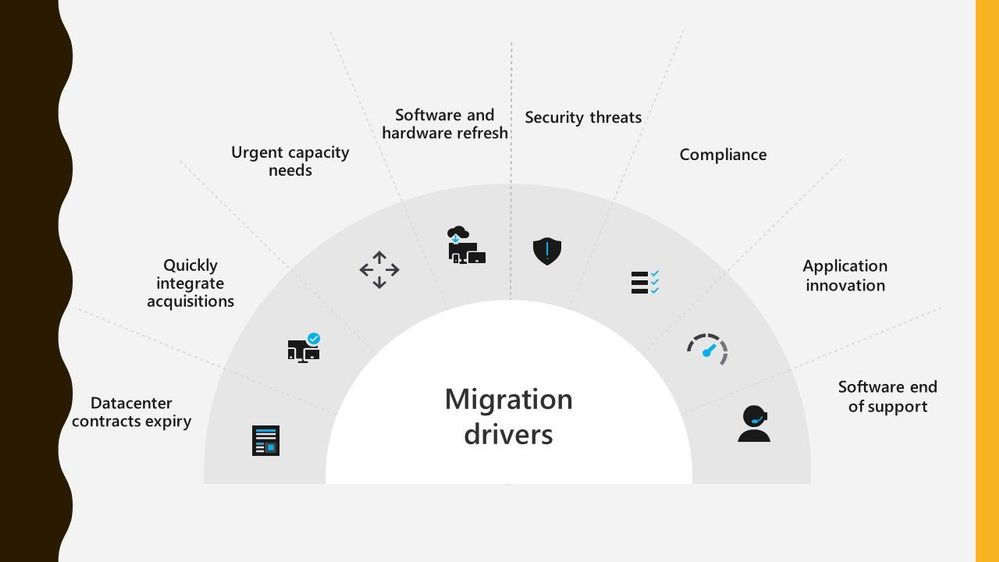
Migrating workloads from on prem datacentres to Azure is something a lot of organisations are thinking about. There are lots of drivers making customers think about this, whether it be physical capacity issues or software refresh timelines.
 Migration Drivers
Migration Drivers
Migrating workloads is a big project and any tooling or guidance that can help make that project easier is often welcomed. And this is where Azure Migrate can assist. Azure Migrate is billed as the hub for datacentre migrations, able to assist with discovery, assessment, and migration of many key migration scenarios such as servers, databases, virtual desktops and data.
Azure Migrate is a free service, and often a question people ask how true that is so let’s tackle that subject.
Discovery and Assessment Costs
I’m a big advocate of organisations carrying out a full discovery and assessment of their environment as the first stage during their migration project, and I talk more about it in my blog post looking at the information you should be looking to discover during that discovery. Azure Migrate is a great tool for doing that initial discovery of your environment, it can collect basic information like server name, operating system version and resource configuration.
The other discovery piece of Azure Migrate: Server Assessment is being able to map how your servers all interconnect. Showing you the ports and services that connect, because let’s face it your servers don’t work independently from each other they are all part of a larger puzzle.
For this dependency visualization Azure Migrate: Server Assessment leverages the power and technology from Log Analytics. The dependency visualization is free for the first 180 days from the day of associating a Log Analytics workspace with the Server Assessment tool. After 180 days, standard Log Analytics charges will apply. And if you use any other solution within that Log Analytics workspace it is not free, and you’ll incur standard Log Analytics charges.
My recommendation is to leave the tool gathering the dependency visualization data for at least 30 days as that should capture a good picture of what happens within your environment and show any specific workload spikes.
Migration Costs
When you come to migrating your servers into Azure as Infrastructure as a Service (IaaS) virtual machines, the Azure Migrate: Server Migration tool can help you with that.
When you start to replicate machines from your own environment up in to Azure you will start to incur charges for Azure Storage, storage transactions and data transfer during replication. However, the license charges for Server Migration are waived for the first 180 days.
So the Azure Migrate: Server Assessment part is free for the first 180 days and I’d like to think that most companies are looking to complete the cutover and run their workload live in Azure well within that 180 day period.
Conclusion
So, I think it is fair to say that you can utilise Azure Migrate for your migration for free. Albeit some surrounding services may cost you but there are mechanisms in place that can avoid you incurring to many charges. I’d love to hear if you’ve used Azure Migrate during your migration project and how it helped keep your migration costs down. :grinning_face:
by Scott Muniz | Aug 31, 2020 | Azure, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
Hi, all! Rod Trent here. I am a Cybersecurity CE/Consultant at Microsoft and working with Azure Sentinel. I also blog for our Secure Infrastructure Blog and have quite a few Azure Sentinel articles posted there already.
Customers ask quite often how they can share their Workbooks with others outside of Azure Sentinel, i.e., give access to the valuable visualizations/reports to those that don’t need full Azure Sentinel access.
The solution is actually much easier than it might seem and involves a very simple method of using the pinning features of Workbooks and setting appropriate RBAC rights.
The most important piece is ensuring that the proper, least privilege rights are in place to enable viewing of the Workbook data on the Azure Dashboard. But, before digging into that, read my recent walkthrough for properly Pinning Entire Azure Sentinel Workbooks to Azure Dashboards.
After understanding how best to promote the Workbook data to an Azure Dashboard, now you just need to set the proper access rights.
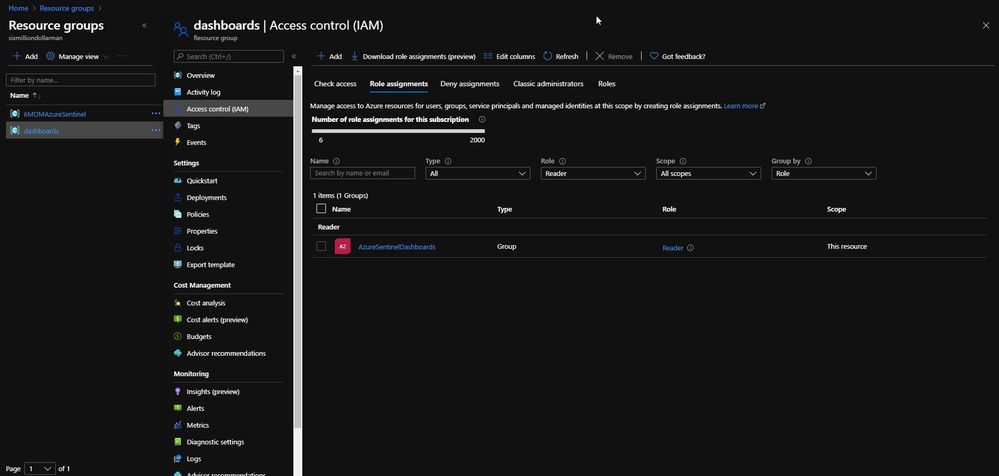
When you follow the instructions listed above, part of the pinning process is saving the dashboard to a resource group. By default, the resource group is dashboards, as shown in the next image.
The dashboards resource group (or whatever you rename it to) needs to have Reader role assignment in place for the individual or individuals that need access to the specific Dashboard. As shown below, I have an Azure Active Directory group called AzureSentinelDashboards with the Reader role on the dashboards resource group. As a best practice, you should always assign groups versus individual role assignments. The user I want to give Dashboard access to, Andre Rene Roussimoff, is a member of the AzureSentinelDashboards group. This gives Andre proper access to the dashboard but doesn’t yet give him access to the Azure Sentinel data. To do that, I have to also assign proper Log Analytics workspace access.

After the dashboards role has been assigned, I now need to assign access to the Log Analytics workspace for Azure Sentinel. This ensures that the user or users can view the data in addition to having access to the Azure Sentinel Workbook that has been pinned as a shared Azure Dashboard.
In the Access control for the Azure Sentinel Log Analytics workspace, I assign the AzureSentinelDashboards group as a Reader of the resource.

As shown in the next image, Andre now has access to the dashboard and also the Azure Sentinel Workbook data.

Summary
Keep in mind, though — this is simply Reader access. If Andre tries to click on any of the Workbook’s dynamic components, he’ll get an error message. But, still…this gives Azure Sentinel analysts a quick and easy way to make Workbooks and reporting data available to those that shouldn’t have full access to the Azure Sentinel console.
P.S. If you’ve been following along, I hope you’ve picked up that there’s a TV theme to my personal Azure Sentinel demo site. Any guess how Andre Rene Roussimoff plays into that TV theme?

Recent Comments