by Contributed | Dec 16, 2020 | Azure, Microsoft, Technology
This article is contributed. See the original author and article here.
Overview
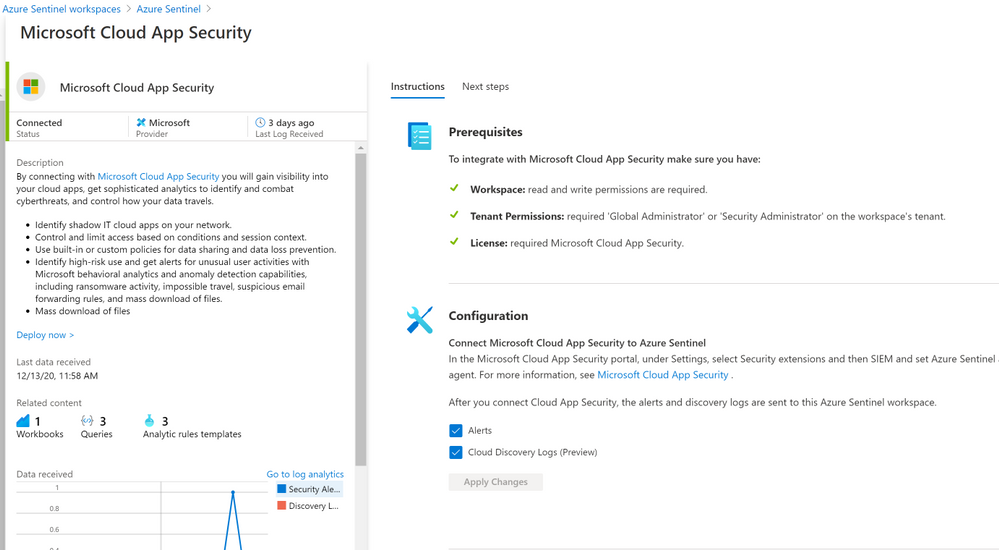
The Microsoft Cloud App Security (MCAS) connector lets you stream alerts and Cloud Discovery logs from MCAS into Azure Sentinel. This will enable you to gain visibility into your cloud apps, get sophisticated analytics to identify and combat cyberthreats, and control how your data travels, more details on enabling and configuring the out of the box MCAS connector (Connect data from Microsoft Cloud App Security)
Cloud App Security REST API (URL Structure , Token & Supported Actions)
The Microsoft Cloud App Security API provides programmatic access to Cloud App Security through REST API endpoints. Applications can use the API to perform read and update operations on Cloud App Security data and objects.
To use the Cloud App Security API, you must first obtain the API URL from your tenant. The API URL uses the following format:
https://<portal_url>/api/<endpoint>
To obtain the Cloud App Security portal URL for your tenant, do the following steps:
– In the Cloud App Security portal, click the question mark icon in the menu bar. Then, select About.
 – In the Cloud App Security about screen, you can see the portal url.
– In the Cloud App Security about screen, you can see the portal url.

Once you have the portal url, add the /api suffix to it to obtain your API URL. For example, if your portal’s URL is https://m365x933168.eu2.portal.cloudappsecurity.com, then your API URL is https://m365x933168.eu2.portal.cloudappsecurity.com/api.
Cloud App Security requires an API token in the header of all API requests to the server, such as the following:
Authorization: Token <your_token_key>
Where <your_token_key> is your personal API token. For more information about API tokens, see Managing API tokens., here’s an example of CURLing MCAS Activity log:

The following table describes the actions supported:

Where Resource represents a group of related entities, fore more details please visit MCAS Activities API
Implementation (MCAS Activity Connector)
- Log in to the Azure tenant, http://portal.azure.com
- Go to Azure Sentinel > Playbooks
- Create a new Playbook and follow the below gif / step-by-step guide, the code being uploaded to github repo as well:
- Add a “Recurrence” step and set the following field, below is an example to trigger the Playbook once a daily basis:
- Interval: 1
- Frequency: Day
- Initialize a variable for the MCAS API Token value, make sure to generate MCAS API Token following this guide
- Name: MCAS_API_Token
- Type: String
- Value: Token QhXXXXBSlodAV9AXXXXXXQlMcFhweXXXXXRXXh1OGkXXkXXkeX
- Set an HTTP endpoints to Get MCAS Activity data:
- HTTP – MCAS Activities API:
- Parse MCAS Activities data via Json:
- Parse JSON – MCAS Activities:
- Content: @{body(‘HTTP_-_MCAS_Activities_API’)}
- Schema: uploaded to github
- Initialize an Array Variable:
- Name: TempArrayVar
- Type: Array
- Append to array variable:
- Name: TempArrayVar
- Value: @{body(‘Parse_JSON_-_MCAS_Activities’)}
- Add For each control to iterate MCAS Activities parsed items:
- Select an output from previous steps: @variables(‘TempArrayVar’)
- Send the data (MCAS Activity Log) to Azure Sentinel Log analytics workspace via a custom log tables:
- JSON Request body: @{items(‘For_each’)}
- Custom Log Name: MCAS_Activity_Log

Notes & Consideration
- You can customize the parser at the connector’s flow with the required and needed attributed / fields based on your schema / payload before the ingestion process, also you can create custom Azure Functions once the data being ingested to Azure Sentinel
- You can customize the for-each step to iterate MCAS Activity log and send them to the Log Analytics workspace so eventually each activity log will be logged in a separate table’s record / row
- You can build your own detection and analytics rules / use cases, a couple of MCAS Activities analytics rules will be ready to use at github, stay tuned
- Couple of points to be considered while using Logic Apps:
Get started today!
We encourage you to try it now!
You can also contribute new connectors, workbooks, analytics and more in Azure Sentinel. Get started now by joining the Azure Sentinel Threat Hunters GitHub community.
by Contributed | Dec 8, 2020 | Azure, Microsoft, Technology
This article is contributed. See the original author and article here.
We are really excited to introduce the preview of new machine learning experiences in Azure Synapse Analytics, to make it easier for data professionals to enrich data and build predictive analytics solutions.
AI and machine learning is an important aspect of any analytics solution. By integrating Azure Synapse Analytics with Azure Machine Learning and Azure Cognitive Services, we are bringing together the best of two worlds, to empower data professionals with the power of predictive analytics and AI. Data engineers working in Azure Synapse can access models in Azure Machine Learning’s central model registry, created by data scientists. Data engineers can also build models with ease in Azure Synapse, using the code-free automated ML powered by Azure Machine Learning and use these models to enrich data.
Linking workspaces to enable collaboration between Data professionals and ML professionals
Linked services can be created to enable seamless collaboration across an Azure Synapse and an Azure Machine Learning workspace. Linked workspaces allow data professionals in Synapse to leverage new machine learning experiences aiming to make it easier to collaborate across Synapse and Azure ML.
Create the Azure Machine Linked service in your Synapse workspace
Seamlessly access Azure Machine Learning models from Synapse
Data professionals working in Azure Synapse can collaborate seamlessly with ML professionals who create models in Azure Machine Learning. These models can be shared and deployed directly in Azure Synapse for enrichment of data.

In the model scoring wizard, enrich with an existing model
By supporting the portable ONNX model format, users can bring a variety of models to Synapse for performant batch scoring, right where the data lives. This removes the need for data movement and ensures that the data remains within the security boundaries defined by Azure Synapse. Columns containing predicted values can easily be appended to the original views and tables that are used to populate your Power BI reports.
Enrich data with Azure Cognitive Services pre-trained models
Fully integrated data enrichment capabilities powered by Azure Cognitive Services allow Synapse users to enrich data and gain insights by leveraging state of the art pre-trained AI models. The first two models available through the Synapse workspace are Text Analytics (Sentiment Analysis) and Anomaly detector. In the future you’ll see more pre-trained models available for use.

Leverage Azure Cognitive Services in Azure Synapse for sentiment analysis

Leverage Azure Cognitive Services in Azure Synapse for Anomaly detection
Train models in Synapse using Automated ML powered by Azure Machine Learning
Data professionals can also build models with ease in Azure Synapse, using code-free automated ML powered by Azure Machine Learning. These Automated ML runs will be executed on Synapse serverless Apache Spark pools and tracked in the Azure Machine Learning service.

Select the task type for your Automated ML run in Azure Synapse
All the machine learning experiences in Azure Synapse produce code artifacts such as PySpark Notebooks or SQL scripts, that allow users of all skill levels to easily operationalize their work in data integration pipelines, to support end-to-end analytics flows from a single unified Synapse experience.
Get started today
We are expanding Azure Synapse to bring together the best in big data analytics and machine learning so you can leverage the full power of Azure. These new experiences in Synapse Studio will streamline the way data teams collaborate and build predictive analytics solutions. A large number of our customers are already taking advantage of predictive analytics solutions. Learn more about how you can get started on your journey with ML experiences in Azure Synapse by using the links provided below.
Resources:
AzureSynapse ML Docs overview: https://aka.ms/synapseMLDocs
Azure Synapse Automated ML tutorial: https://aka.ms/SynapseMLDocs_AutoML_tutorial
Azure Synapse model scoring tutorial: https://aka.ms/SynapseMLDocs_Scoring_Tutorial
Azure Synapse Cognitive Services tutorial: https://aka.ms/SynapseML_Docs_Cognitive_Services
Link Azure Synapse workspace to Azure ML workspace:https://aka.ms/SynapseMLDocs_link_AML
Azure Synapse TechCommunity: Check this blog daily to see a roundup of all the new tutorial blogs that will be posted for the next two weeks.

by Contributed | Dec 8, 2020 | Azure, Microsoft, Technology
This article is contributed. See the original author and article here.
With Azure Sentinel you can receive all sorts of security telemetry, events, alerts, and incidents from many different and unique sources. Those sources can be firewall logs, security events, audit logs from identity and cloud platforms. In addition, you can create digital trip wires and send that data to Azure Sentinel. Ross Bevington first explained this concept for Azure Sentinel in “Creating digital tripwires with custom threat intelligence feeds for Azure Sentinel”. Today you can walkthrough and expand your threat detection capabilities in Azure Sentinel using Honey Tokens or in this case Canarytokens.
What is a Honey Token? A honey token is a digital artifact like a Word Document, Windows Folder, or JavaScript file that when opened or accessed will act as a digital trip wire and alert you to being used. When used the honey token might make a GET HTTP call to a public facing URL or IP. The so that an attacker would want to investigate and exfiltrate the artifact but also ensuring you reduce false positives from normal users. One way to do this is creating a separate folder from the normal directory structure. This could take the form of naming a Word document High Potential Accounts.docx. And then placing it in a Sales share but inside two more nested directories.
The other key is to make the digital artifact searchable or easily found, you want the attacker to see the token and access it. You can also sprinkle these honey tokens through out the network and in different use cases beyond. The key here is ensuring that the honey token is in a visible location and can directory searched upon by normal user credentials.
As with most things a balanced approach should be taken with honey token names and placement. Think through where in the cyber kill chain you want the digital trip wire, and ways to make the token enticing to an attacker but will also reduce false positives from normal employees and routines.
Honey Tokens are not a new concept but the following approach described to use a service called Canarytokens is a bit newer. Canarytokens is a free service provided by Thinkist that generates different types of tokens and provides the back end trip wire logging and recording. The service allows you to focus on the naming and placement specific to your industry and buisness rather then building a Public facing URL that logs and collects the tokens being tripped. Thinkist also has a paid service as well that includes many useful features.
In the below example you will walk through creating a free Canarytoken (honey token as described) but through a Canary service and use it to update Azure Sentinel when it is triggered.
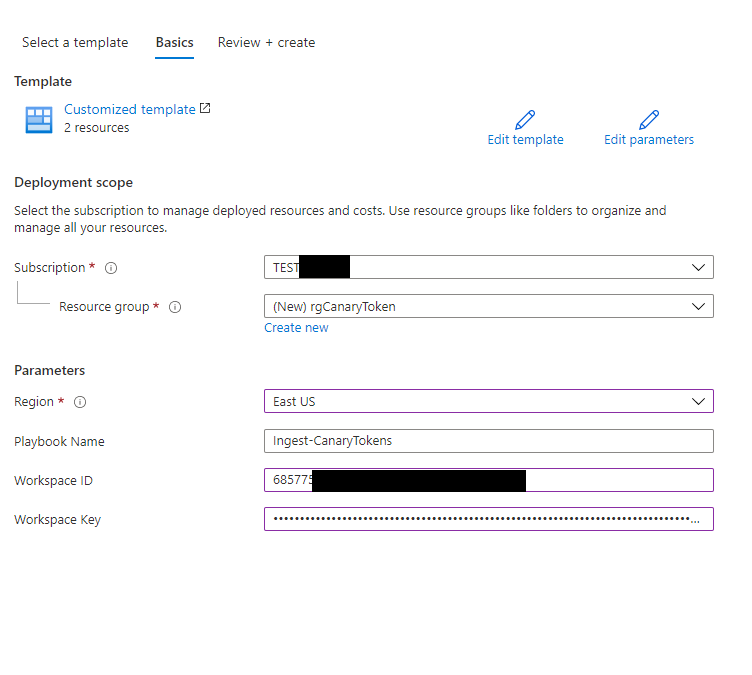
To begin with you can deploy a Logic App Ingest-CanaryTokens here. The Logic App will act a listener and will provide a URL you can use in the Canarytoken generation.
To Deploy the Logic App fill in your Azure Sentinel Workspace ID and Key.

Once deployed go to the Logic App and in the Overview click on the blue link: See trigger history

Copy the URL from the following field: Callback url [POST]

With this LogicApp and a Callback listening URL you can now generate a Canarytoken.
To create the Canarytoken go to the following website: Canarytokens
- Choose Microsoft Word Document
- Fill out your email address and enter a <SPACE> and paste the Logic App Callback URL
- In the final field enter a description, – see below
You will use description to also host your Entities for Azure Sentinel. You can use a comma as a separator between the entity information you want to capture upon tripping the wire.
Be sure to be descriptive to what ServerShare or OneDrive the Canarytoken will be placed. Because you will generate several different tokens the descriptive notes will come in the alert that is triggered ensuring you will be able to dive further on that Server or Service to investigate further activity of the attacker.
In this example you could use:
Name |
Descriptor |
Azure Sentinel parsed column name |
|
Computername |
The Computername where Canarytoken is hosted |
CanaryHost |
|
Public IP |
the public ip of internet access where token is hosted. Can be used to correlate if token is launched within data center or known public ip of server
|
CanaryPublicIP
|
|
Private IP |
Private ip of computer where token is hosted could be used to correlate additional logs in Firewalls and other IP based logs
|
CanaryPrivateIP |
|
Share Path |
The share path this Canarytoken is hosted at, helps indicate where a scan or data was compromised at.
|
CanaryShare |
|
Description |
helps provide addition context for SOC Analyst about purpose of Canarytoken and it’s placement
|
CanaryDescription |
|
*EXAMPLE:
FS01,42.27.91.181,10.0.3.4,T:departmentssaleshipospecials,token placed on FS01 available to all corporate employees and vendors
4. Once Completed click Create my Canarytoken

Check out the further use cases for the Canarytokens to be placed. Go ahead and Download your MS Word file.

Notice the file name that downloads is the Canarytoken id itself. This word document name really is not that compelling for an attacker to discover, exfiltrate, and investigate. You should rename the file immediately to something more compelling.
You want to grab the attention of the attacker searching for valuable information. Remember the overall arching goal for most attackers is obtaining key corporate data. The Canarytoken is helping alert to the violation of confidentiality, integrity and availability of key corporate data. Names like Project Moonshot placed in NextGeneration folder could help entice. Document name like High Potential Account List in a Sales team folder may also do the trick. Be creative to your industry and business as to what data could be valuable.
In this example we used White Glove Customer Accounts.docx

To make the document seem more legitimate you can use a website Mockaroo – Random Data Generator and API Mocking Tool | JSON / CSV / SQL / Excel to generate random and fictious data easily. Here you can create what appears to be a customer account list with account numbers and email addresses.

Once you fill out the fields you want go ahead and download a CSV sample by clicking Download Data green button. Open with Excel and be sure to manipulate the Rows and Columns to make it nicely formatted. With the table looking presentable copy the content in Excel and Open the Word Document Canarytoken and paste the content in and save the document.

You now have a Canarytoken that looks authentic and hopefully will not arouse the suspicion of the attacker but will be visible and entice them greatly to exfiltrate and open it. Continue to examine Mockaroo and the data you can generate it is a very easy to use and helpful tool.
Now find a home for the word document in a File Share on a File Server, or as an email attachment in your executives mailbox – again think back to the description you gave it and follow that to where it is placed so in the worst case you are attacked this can tip you off to where on your network to focus your investigation further in Azure Sentinel’s logs and events you are collecting.
To test this open the Word Document on your computer or on another server or computer with word. When Microsoft Word opens a .1 by .1 header and footer image with a open URL will execute a GET HTTP call to the appropriate CanaryToken endpoint you created earlier. Once this occurs you will receive an email with details like below.

Be sure to also check out the More info on this token here link, which will provide more geo information on the public ip that opened the document and also if it came off a known Tor browser or not.

You can also download a JSON or CSV file of the detailed information found in the Incidents generated when the Canarytoken was opened.
In addition to the email the Logic App listener will be invoked which will take the Incident Data and enrich it a little further and send it to Azure Sentinel into a custom logs table named CanaryTokens_CL.

Some of those enriched fields include geo information on the public ip address that triggered the Canarytoken. There is also parsed information from the memo field to include specifics around the Canarytokens placement in your environment and objectives and some logic to tell you if the canary was triggered on host. Finally string fields for URLs have been populated for you to review the management and history of the Canarytoken if you need to pivot from Azure Sentinel to the Canarytoken specifically while investigating.
You can now use Azure Sentinel to raise a High Priority incident and work the incident with case management. You can also correlate logs and data with other Azure Sentinel data collected further helping you investigate the incident.
An example Scheduled query rule in Azure Sentinel you can use following along this walkthrough. Step by step instructions Here
id: 27dda424-1dbe-4236-9dd5-c484b23111a5
name: Canarytoken Triggered
description: |
'A Canarytoken has been triggered in your enviroment, this may be an early sign of attacker intent and activity,
please follow up with Azure Sentinel logs and incidents accordingly along with the Server this Canarytoken was hosted on.
Reference: https://blog.thinkst.com/p/canarytokensorg-quick-free-detection.html'
severity: High
requiredDataConnectors:
- connectorId: Custom
dataTypes:
- CanaryTokens_CL
queryFrequency: 15m
queryPeriod: 15m
triggerOperator: gt
triggerThreshold: 0
tactics:
- Discovery
- Collection
- Exfiltration
relevantTechniques:
query: |
CanaryTokens_CL
| extend Canarydata = parse_csv(memo_s)
| extend CanaryHost = tostring(Canarydata[0]), CanaryPublicIP = tostring(Canarydata[1]), CanaryPrivateIP = tostring(Canarydata[2]), CanaryShare = tostring(Canarydata[3]), CanaryDescription = tostring(Canarydata[4])
| extend CanaryExcutedonHost = iif(CanaryPublicIP == src_ip_s, true, false)
| extend timestamp = TimeGenerated, IPCustomEntity = src_ip_s //,AccountCustomEntity = user_s, HostCustomEntity = computer_s
entityMappings:
- entityType: IP
fieldMappings:
- identifier: Address
columnName: IPCustomEntity
Once you have created the rule, open the Canarytoken word document one more time to generate an alert.
Within 15 minutes or so a new Azure Sentinel Incident for the Canarytoken being trigged will appear, your SOC can now use the Logs fed into Azure Sentinel to correlate and investigate further.

In addition the Investigate Graph is also populated with the Public IP Address of where this was triggered.

Please tweak the Custom Entities to your liking. Another way is to point where the Canarytoken was placed to bolster the pivot of the Investigation graph. The above alert sample parses the memo field you added early with commas when generating the initial Canarytoken.

In this article you learned about honey tokens and a Canary service and how to use Canarytokens in your environment and integrate the enriched alerts into Azure Sentinel raising awareness of a potential attacker and data exfiltration that may have occurred.
You have just scratched the surface with the concept of honey tokens. If you are interested in learning more in depth I highly recommend Chris Sander’s book Intrusion Detection Honeypots which is a excellent resource.
Special thanks to:
@Ofer Shezaf for reviewing this post
@Chris Sanders for inspiration and information on the topic of Honey Tokens
by Contributed | Dec 8, 2020 | Azure, Microsoft, Technology
This article is contributed. See the original author and article here.
Initial Update: Tuesday, 08 December 2020 13:03 UTC
We are aware of issues within Log Analytics and are actively investigating. Some customers may experience data access issues in Australia South East region.
- Work Around: None
- Next Update: Before 12/08 17:30 UTC
We are working hard to resolve this issue and apologize for any inconvenience.
-Sandeep
by Contributed | Dec 7, 2020 | Azure, Microsoft, Technology
This article is contributed. See the original author and article here.
The SAP on Azure group is excited announce the preview for SAP on Azure Deployment Automation Framework. This introduces an extensible framework that will modularly address the complexities of running SAP on Azure.
Some of the largest enterprises in the world currently run their SAP solutions on Microsoft Azure. Since these SAP applications are mission critical, even a brief delay or disruption of service can have a significant business impact on an organization.
Today the journey to deploying an SAP system is a manual process. This can quickly become costly due to divergence in resources and configuration, or discrepancies introduced through human error. To reduce this impact, improve consistency, and reduce lead times, we are approaching the SAP deployment as an opportunity to define the SAP Infrastructure as Code (IaC) and capture the configuration activities as Configuration as Code (CaC).
To help our customers effectively deploy their infrastructure for SAP on Azure repeatably and consistently, we are providing the IaC (Infrastructure as Code) and CaC (Configuration as Code) code repository that will utilize the industry leading offerings such as, Terraform and Ansible respectively.
Key Capabilities of SAP on Azure Deployment Automation Framework
- Deploy multiple SAP SIDs consistently
- Securely managed keys with Key Vault
- Deploy and configure for High Availability (HA)
- IaaS – Infrastructure as Code (IaC)
- Logically partitionable by environment, region, and virtual network
- Availability Zone support where appropriate
- SAP HANA and AnyDB configuration support
- Distributed application tier deployment
- Configuration – Configuration as Code (CaC)
- SAP HANA database install
- Pacemaker configuration for SAP HANA with HSR
Benefits of SAP on Azure Deployment Automation Framework
Reviewable code: delivering the tools as IaC and CaC via open source, allows organizations and teams to preview the definition of what Azure resources will be created and how the VM OS will be configured. In the world of DevOps, this allows the code to be approved prior to execution.
Deployment Consistency: IaC and CaC allow, not only the IaaS to be deployed consistently and repeatably, but also define the post deployment system administration activities to follow a procedural set of steps that will be consistent and repeatable. Both tools function idempotently, which becomes part of drift detection and correction.
Configurable: The IaC and CaC modules provide standard functionality. However, the functionality can easily be configured through inputted parameters. Changes delivered over time will enhance and extend functionality. Some examples of supported configurations include: Number of application servers, high-availability in the database and/or application tier, enabling/disabling of either database or application tier, overriding default naming standard, and the ability to bring some of your own resources in certain instances.
Drift detection and correction; With tools that apply the IaC and CaC idempotently, we can detect when the deployed resources have drifted from their state as defined by the tools. When detected, a choice may be made to apply the desired state to resolve any drift.
Strategy
We have chosen to take an open source approach to establish a framework of Infrastructure as Code (IaC) and Configuration as Code (CaC). This framework provides the structure that allows an E2E workflow to be executed on by industry leading automation tools and is easily extendable.
- Terraform – is the swiss army knife of IaC tools. It is not only idempotent, Terraform is completely cloud-agnostic and helps you tackle large infrastructure for complex distributed applications. Terraform automation is orchestrated in varying degrees with the focus on the core plan/apply cycle.
- Ansible – Provides a “radically simple” IT automation engine. It is designed for multi-tier deployments and uses no agents. Ansible is a strong fit for configuration management, application deployment, and intra-service orchestration by describing how all the systems inter-relate. Ansible is one of the more flexible CaC tools on the market right now.
At this stage of the release, the IaC and CaC are offered as BYOO (Bring Your Own Orchestration). This means that you will provide the governance around the execution of the automation. We provide a framework workflow that can function out of the box, with a defined set of manual executions. It can also fit in to a more mature, customer provided, Orchestration environment.
Vision
The SAP on Azure Automation Framework over time will automate many more tasks than just deployment. We plan to continuously improve this framework to meet all your deployment automation needs and expand support for more infrastructure and post-deployment configurations. Stay tuned for updates.
Pricing and Availability
The tools being developed are meant to accelerate the customers adoption of Azure for SAP deployments. As such, these tools are offered free of charge.
Learn more
To learn more about the product, check out the GitHub repository and documentation in the preview branch at: https://github.com/Azure/sap-hana/tree/beta/v2.3
To get started, we have provided some bootstrapping instructions and a self-paced workshop to deploy the IaaS for a 1 or more SAP system deployments.
Feedback
We plan to continuously improve this framework to meet all your deployment automation needs. We welcome all feedback and can be reached at: sap-hana@microsoft.com

Recent Comments