
Azure Data Explorer – Reimagine Telemetry Analytics
This article is contributed. See the original author and article here.

Two years have passed since we launched the Azure Data Explorer public preview at Ignite 2018. We offered the internal service called Kusto, that Microsoft has been using since 2015 and offered it as a PaaS service. We believed that the broad adoption of the Kusto service within Microsoft, would be repeated had we shared this service and best practices with Microsoft’s best partners and customers.
Guess what? It turns out that we were right. Azure Data Explorer is versatile and it has been used in a variety of scenarios. However, the two most common scenarios we identified were 1. Forming an interactive telemetry data lake or “log lake” and 2. Building analytical solutions as a service with Azure Data Explorer as a back-end data platform. In both, external adoption resembled the internal adoption pattern that we have seen in the last 6 years.
The Azure Data Explorer Online event that we are hosting today is a great opportunity to see these realized customer stories and announce incredible innovation in analytical power and performance. If you missed today’s event, you can find recordings of the sessions on the Azure Data Explorer video channel.
Unified Telemetry Repositories
The essence of the digital transformation is to sense everything that happens around a system or a company that can impact its effectiveness and efficiency. These rich telemetry signals continue growing in volume. The ability to keep up with the inflating scale, provide knowledge workers effective means to reach insights and make decisions while keeping costs at bay, is an ever-increasing challenge.

Today we watched Lutz Beck, CIO at Daimler Trucks North America explain that Azure Data Explorer is the right tool to build an intelligent and data driven company. Using Azure Data Explorer, they bring data together from connected trucks, truck configuration, connected factory, quality and repair information to build an end-to-end timeline of the life of their products. Doug Murphy, Manager Data Intelligence Hub and Sammi Li, Expert Data Analyst shared how it enabled Daimler to evolve truck maintenance from reactive to proactive for their customers.
Dealing with a different type of traffic, Ariel Pisetzky, VP Information Technology and Cyber at Taboola, described how Taboola mines billions of CDN access log records to ensure quality of service for its users across the world (architecture).
Activity and operations wear many different forms. A recently published example is how AGL manages a massive solar energy sharing marketplace to make Australia green and efficient (architecture). AGL captures IoT telemetry from a vast amount of batteries and conducts advanced time series analytics to ensure a smooth transition to clean, renewable energy in Australia.
Just like at Microsoft, these companies leverage Azure Data Explorer’s capabilities to unlock big data analytical scenarios that weren’t previously feasible. The intuitive query language and tools and the scalable fully managed deployment empower people to transform data to insight to action. The great price and performance makes all that possible, in spite of the massive amounts of data that constantly keep growing.
Analytical Solutions as a Service
As the Azure Data Explorer service became more and more prevalent, Microsoft has built multitenant analytical solutions based on Azure Data Explorer: Azure Monitor and Microsoft Intune for data centers, services, applications and device management, Azure Advanced Threat Protection, Azure Sentinel and others in the security space, Azure Time Series Insights, Azure IoT Central, the connected vehicles platform in the IoT space, PlayFab for gaming analytics, Dynamics 365 Product Insights in commerce, Office 365 Education Class Insights and so on.
Today, Itay Greenberg, VP product at Check Point software, shared how Check Point is adopting Azure Data Explorer to provide powerful analytics as part of its security products. More and more telemetry analytics based solutions are getting built on Azure Data Explorer in IoT (Bühler), retail and advertising (Episerver, ZOOMD), financial services (Financial Fabric, Milliman), gaming and more domains.
Massive Scale
Azure Data Explorer is running on over one million CPU cores on Azure today, making 2EB (Exabyte) of data available (Was 1EB in January) for fast interactive queries and analytics and new data ingestion in rates higher than 35PB per day. Especially during COVID19, as digital activity is on the rise and cost efficiency for every company is of the outmost importance, providing Azure Data Explorer users with the powerful, fast, human friendly affordable analytics is the top priority.
Start Fast and Accelerate!
Today we are announcing the public preview of the new version of the Kusto analytical engine – Kusto EngineV3. The new version of the engine is the fruition of a massive investment in core data platform technology and can perform complex queries up to 100 times faster than the current (very fast) version of the Kusto engine. Moreover, the CPU consumption for running queries can be up to 30 times lower, a drop which has huge direct implications on service usage TCO.
This dramatic performance and cost improvements are achieved via redesign of the data storage format, native code generation for portions of the query plan, and automatic selection of strategies based on data shard statistics. The Azure Data Explorer product team and a growing circle of customers are running the EngineV3 preview in production. The public preview is available on the Azure Portal and clusters in public preview will only accrue infrastructure cost until general availability targeted to Feb 1st, 2021. Once the preview ends, all new clusters will be created with the new version of the engine and existing clusters will be migrated over time so user driven data migration is not required.
Harnessing the hardware innovation from AMD

Beyond the dramatic advancement in the service core software, Azure Data Explorer was designed to take advantage of the newest hardware innovation. Service design and pricing enable customers to leverage new hardware, without the need to buy or manage servers, harnessing Moore’s law to their advantage.
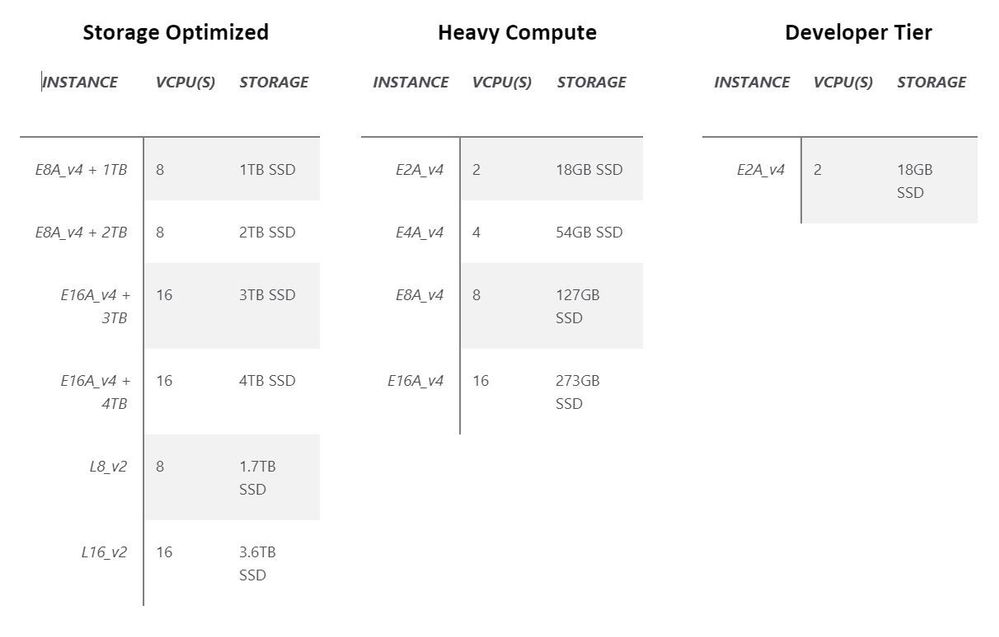
This year Azure Compute and AMD joined forces to deliver incredible innovation in virtual machines based on the AMD EPYC™ CPUs. These VM families represent unprecedented improvements in return on investment in cost and performance. Check out the new supported virtual machine SKUs for Azure Data Explorer powered by AMD EPYC™ CPUs and how they enable 30%-50% more processing power for the same cost. The Eav4 family provides very high CPU to SSD ratio that is delivering excellent performance in heavy compute demanding workloads, like high concurrency and complex queries. Similarly, the E2av4 is powering the new recommended dev/test SKU. The Easv4 family becomes the recommended SKU for Azure Data Explorer clusters that leverage premium storage SSD for the hot data cache. The Dav4 virtual machines family is becoming the default VM for the data management role in Azure Data Explorer cluster.
For storage heavy workloads, the Lsv2 virtual machine family introduces superfast, large NVMe SSD drives that allow storing and scanning vast amounts of data. Combined with the dramatically increased CPU efficiency of EngineV3, this configuration provides extreme power over very large amounts of data at an affordable cost.
What’s New?
If by now you are interested in trying it out, here is a set of completely exciting new capabilities that we are adding across the board!
Getting Data In!
Data is the first required element for every analysis and making it friction free to ingest data, reducing the ingestion latency, and optimizing costs are all very important.
Today we are announcing the general availability of the streaming ingestion functionality that allows ingesting data into Azure Data Explorer with only a few seconds of latency. Streaming ingestion allows enjoying both worlds: Columnar storage for high performance queries and low latency for single record addition. This capability is extremely valuable in workloads with many different event streams, each with low frequency of events going to separate tables and databases. For example, Azure Monitor moved to use streaming ingestion while ingesting data from smaller workspaces and was able to drive-down both latency and its storage related costs by 17%.
The 1-click ingestion experiences are now generally available. They streamline the creation of tables, data mappings based on sample data, ingests and automates notification based ingestion from the data lake.
We have made a major investment in proofing and certifying (Verified Gold) the Azure Data Explorer Kafka connector so that it can be used reliably in massive workloads, while maintaining at least once delivery guarantees as close as possible to exactly once.
In collaboration with Azure Storage, FluentBit, the native code, efficient open source telemetry collection agent, delivered a high-performance output that can be used to reliably write massive amounts of telemetry to Azure Storage. Together with Azure Data Explorer’s ability to automatically ingest data that lands in Azure Storage containers, this is one of the most efficient pipelines for collecting and storing telemetry as scale.
Analyzing Data in New Ways!
Classic data warehousing projects start by defining curated data models with clear and well documented objects and attributes. Later, ETL processes run periodically to update these objects and attributes. In real time analytics with Azure Data Explorer, the approach is different: You ingest the data almost as is and apply schema during query time(schema on read). This approach provides a lot of flexibility to ask every question you need answered. However, as some query patterns become common or frequent, it makes sense to precompute the results or intermediary results to reduce the re-computation load. This precomputation isn’t trivial to implement, especially if you want it to always be up to date and still be efficient. The newly introduced Materialized Views (preview) makes it super easy to transform a Schema-On-Read query into a materialized table that is transparently kept updated by Azure Data Explorer. That means that you can postpone optimizing and materializing a query until it’s necessary, and then it’s super simple to do!
Partitioning policies, that impact how data shards are partitioned, is reaching general availability. It is an extra lever to further improve performance of queries that are known to filter on the partitioned columns, or aggregate/join on a high cardinality string column.
When multiple clients are running the same queries and concurrency are high such in a heavily used dashboard scenario, Query Result Set Caching provides service side out of the box advanced caching functionality that improves both user experience and resource consumption.
But beyond speed and efficiency, which I believe I already proved we care about deeply, there are new interesting capabilities that are being released: Geo spatial joins enables solutions like geospatial risk analysis and agriculture optimization using weather data by correlating polygons and locations from two or more tables. Added support for near real time scoring of AML and ONNX models, that allow you to enrich, classify, and detect issues in data as it gets streamed in near real time. Scoring data upstream allows all data consumers, dashboards, investigations, data lake exports, among others, to enjoy and leverage the AI advantage. Fast Fourier Transform allow switching time series from the spatial domain to the frequency domain and back which is very useful in signal processing and analysis. High order Polynomial regression is yet another useful capability for forecasting and anomaly detection of complex metrics.
The above are great examples for common big data analytics use cases these days. However, there are many more analytics scenarios, with diverse levels of popularity. We have created the analytics function library for people to contribute to the documented, discoverable set of capabilities Azure Data Explorer offers. For example, the ONNX predict function was added as part of the function library. The function library is completely open for contribution along with the rest of the Azure Data Explorer documentation based on the Microsoft Docs platform. Now everyone can use the power of KQL, python and R to implement a reusable version of the special analytics they need!
Safe, Secure and Enterprise Ready
Azure Data Explorer is heavily used by Microsoft and its users in highly regulated and secure workloads. The service constantly evolves to address more and more enterprise readiness capabilities. Controlling who has access to each data element is a very common need. The Row Level Security policies allow a high granularity of control over what data each user sees . You can mask, replace values, and map as needed based on the Azure Active Directory user principal or other policies.
For the highest standard in workload separation, Azure Data Explorer now supports running isolated compute nodes that guarantee that the servers that power one’s cluster don’t run VMs from a different tenant.

Visualizing Data

We joined forces with the PowerBI team to make solutions based on PowerBI and Azure Data Explorer better by being more performant and broadly applicable. For that purpose, we have developed, jointly with the PowerBI team, the ability to pass dynamic parameters from slicers and filters into Azure Data Explorer through the DAX engine in DirectQuery mode. In addition, PowerBI is adding support for network isolation scenarios like the ability to support AAD identity in the PowerBI Gateway and true VNet support.
We are also working closely with Grafana and recently enhanced the Grafana Azure Data Explorer plugin by adding a new graphical query builder, to help less technical Grafana users author and publish Grafana dashboards, using simple drop-down controls and auto population logic based on real live data.
Tightly Integrated Azure Data Services
Azure Data Explorer is being deeply integrated with the Azure data services to provide a seamless, consistent experience that leverages the best technologies for a workload.
Azure Data Share in-place Sharing for Azure Data Explorer, just made generally available, enables you to share big data easily and securely between internal departments and with external partners, vendors, or customers for near real-time collaboration. It leverages Azure Data Explorer to spin off compute separately from the persistent storage, with different caching policies to allow workload separation. With this technology generally available companies can generate revenue from data assets that they have without becoming an operator for data distribution APIs.
Azure Data Studio just announced support for Azure Data Explorer and KQL. The Kusto (KQL) extension in Azure Data Studio is now available in preview. This native KQL support brings another modern data experience to Azure Data Studio, a cross-platform client – for Windows, macOS, and Linux. Users can now connect and browse their Azure Data Explorer clusters and databases, write and run KQL, as well as author notebooks with Kusto kernel, all equipped with IntelliSense and ability to integrate with the CI/CD pipelines in GitHub or Azure DevOps.

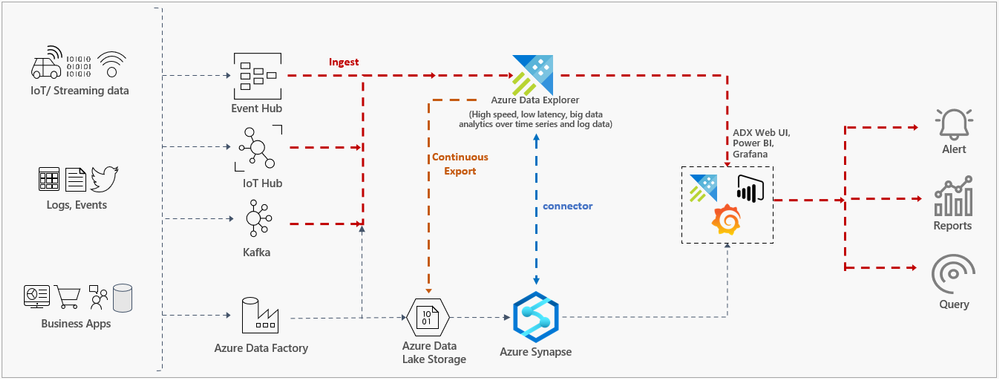
And finally, today we launch the first phase of the Azure Data Explorer integration into Azure Synapse Analytics. The Azure Data Explorer data connector for Azure Synapse allows leveraging the Synapse Spark pool and other Synapse capabilities from your workspace and query the telemetry data streaming into Azure Data Explorer or write your processed data or machine learning models into Azure Data Explorer for further analysis. This connector simplifies the architecture for building hot/warm/cold path for your Big Data solutions using Azure Synapse Analytics and Azure Data Explorer. This is only the beginning of this journey; Azure Data Explorer will be deeply integrated into Azure Synapse Analytics as a native offering.
What’s Next?
If you made it this far, you already know that the Azure Data Explorer service in progressing very quickly, optimizing, investing in compliance, user experience, adoption acceleration and beautiful visualization options. You can stay up to date with new features as the come out by following @AzDataExplorer on twitter and via Azure Update.
I hope you found the event interesting and useful. You are welcome to continue and engage with us on Tech Community, Uservoice, the ADX blog and @AzDataExplorer on twitter.





 .
.
Recent Comments