This article is contributed. See the original author and article here.
One such error for Azure SQL Database users employing DataSync is: “Database provisioning failed with the exception ‘Column is of a type that is invalid for use as a key column in an index.” This article aims to dissect this error, providing insights and practical solutions for database administrators and developers.
Understanding the Error:
This error signifies a mismatch between the column data type used in an index and what is permissible within Azure SQL DataSync’s framework. Such mismatches can disrupt database provisioning, a critical step in synchronization processes.
Data Types and Index Restrictions in DataSync:
Azure SQL Data Sync imposes specific limitations on data types and index properties. Notably, it does not support indexes on columns with nvarchar(max)that our customer has. Additionally, primary keys cannot be of types like sql_variant, binary, varbinary, image, and xml. What is SQL Data Sync for Azure? – Azure SQL Database | Microsoft Learn
Practical Solutions:
Modify Data Types: If feasible, alter the data type from nvarchar(max) to a smaller variant .
Index Adjustments: Review your database schema and modify or remove indexes that include unsupported column types.
Exclude Problematic Columns: Consider omitting columns with unsupported data types from your DataSync synchronization groups.
If you are looking for a way to modernize your Windows applications, streamline your development process, and scale your business with Azure, you might be interested in learning how other customers have achieved these goals by using Windows Containers on Azure Kubernetes Service (AKS).
Windows Containers on AKS is a fully managed Kubernetes service that allows you to run your Windows applications alongside Linux applications in the same cluster, with seamless integration and minimal code modifications. Windows Containers on AKS offers a number of benefits, such as:
Reduced infrastructure and operational costs
Improved performance and reliability
Faster and more frequent deployments
Enhanced security and compliance
Simplified management and orchestration
Stay tuned for new stories that will be published soon, featuring customers from new industries and with new scenarios using Windows Containers.
In the meantime, we invite you to check out the Windows Container GitHub repository, where you can find useful resources, documentation, samples, and tools to help you get started. You can also share your feedback, questions, and suggestions with the Windows Container product team and the community of users and experts.
This article is contributed. See the original author and article here.
In the rapidly evolving AI landscape, Microsoft Dynamics 365 Business Central is taking the lead with innovations that have equipped more than 30,000 small and medium-sized businesses to achieve success. Powered by next-generation AI, Microsoft Copilot offers new ways to enhance workplace efficiency, automate mundane tasks, and unlock creativity. At a time when nearly two in three people say they struggle with having the time and energy to do their job, Copilot helps to free up capacity and enables employees to focus on their most meaningful work.1
Dynamics 365 Business Central brings the power of AI to small and medium-sized businesses to help companies work smarter, adapt faster, and perform better. AI in Dynamics 365 Business Central improves the way work gets done, enabling you to:
Get answers quickly and easily using natural language.
Save time by automating tedious, repetitive tasks.
Spark creativity with creative content ideas.
Anticipate and overcome business challenges.
Reclaim time for important work
In a small or medium-sized business, there is often a lot to do and not many people to help get it all done, so it’s important to make the most of your limited resources to accomplish your goals. Everyday activities like tracking down documents and bringing new employees up to speed can drain your valuable time. What if you had an AI-powered assistant ready to help you find exactly what you need without the hassle?
Available in early 2024, conversational chat using Copilot in Dynamics 365 Business Central helps you answer questions quickly and easily, locate records faster, and even learn new skills—all using natural language. Save time and effort by navigating to documents without having to use traditional menus, and rapidly onboard new users with answers to questions on how, when, or why to do things. Copilot is your everyday AI companion, helping you to speed through tasks, build momentum, and free time for your most impactful work.
Streamline month-end tasks with enhanced bank reconciliation
Reconciling bank statement transactions with your financial system has often been a tedious monthly chore. Meticulously matching every line item to new or existing accounting entries takes time (and isn’t the most exciting way to spend an afternoon.) In the past, Business Central helped by auto-matching many of the simple one-to-one transactions, but the logic wasn’t able to decipher more complex scenarios such as when multiple charges were paid in a single transaction.
Now, Copilot in Business Central makes bank reconciliation even easier by analyzing bank statements that you import into Business Central, matching more transactions, and proposing entries for transactions that weren’t auto-matched. By comparing and interpreting transaction descriptions, amounts, dates, and patterns across fields, Copilot can help you improve the accuracy of your bank reconciliation while reducing manual effort.
Unlock creativity with marketing text suggestions
Copilot in Business Central helps product managers save time and drive sales with compelling AI-generated marketing text suggestions. Using key attributes like color and material, Copilot can create product descriptions in seconds tailored to your preferred tone, format, and length. Once you’ve made any adjustments, you can easily publish to Shopify or other ecommerce platforms with just a few clicks. Discover how Copilot can help you banish writer’s block and launch new products with ease.
Boost customer service with inventory forecasting
Effective inventory management is crucial in a competitive business environment as it can significantly influence a company’s success and customer retention. This process involves balancing customer service with cost control. Maintaining low inventory reduces working capital, but risks missing sales due to stock shortages. Using AI, the Sales and Inventory Forecast extension uses past sales data to forecast future demand, helping to prevent stockouts. Once a shortfall is identified, Business Central streamlines the replenishment process by generating vendor requests, helping you keep your customers happy by fulfilling their orders on time, every time.
Reduce risk with late payment prediction
Managing receivables effectively is vital for a business’s financial wellbeing. With the Late Payment Prediction extension, you can reduce outstanding receivables and refine your collections approach by forecasting if outstanding sales invoices are likely to be paid on time. For instance, if a payment is anticipated to be delayed, you could modify the payment terms or method for that customer. By proactively addressing potential late payments and adapting accordingly, you can minimize overdue receivables, reduce risk of non-payment, and ultimately improve your financial performance.
Improve financial stability with Cash Flow Analysis
Powered by AI, Business Central can create a comprehensive Cash Flow Analysis to help you monitor your company’s cash position. Cash flow is a critical indicator of a company’s solvency, and cash flow analysis is an important future-focused planning tool that helps you maintain control over your financial health and make proactive adjustments to meet all your financial commitments. With insights from Business Central, you can pivot quickly to safeguard your company’s fiscal wellbeing, such as obtaining loans to cover cash shortfalls or cutting back on credit when you have surplus cash.
Work smarter with Copilot in Business Central
Copilot in Business Central gives your company an edge with AI-powered innovations that are a catalyst for unleashing human potential, fostering creativity, and driving efficiency in ways previously unimaginable. The integration of AI into everyday business processes is not just about staying ahead in a competitive market, it’s about redefining what’s possible in the workplace. With Business Central, your company is empowered to navigate today’s complex business environment with agility, precision, and a renewed focus on what truly matters.
Dynamics 365 Business Central
Work smarter, adapt faster, and perform better with Business Central.
This article is contributed. See the original author and article here.
Introduction
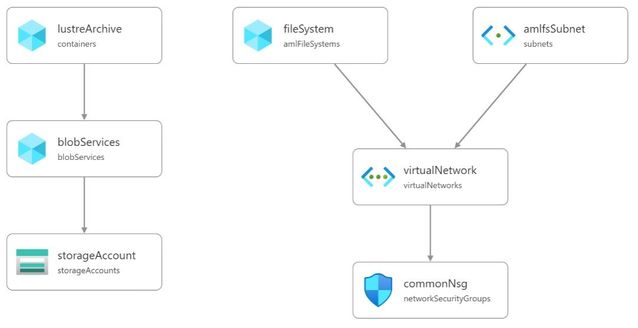
This blog post walks through how to setup anAzure Managed Lustre Filesystem (AMLFS)that will automatically synchronise to an Azure BLOB Storage container. The synchronisation is achieved using the Lustre HSM (Hierarchical Storage Management) interface combined with theRobinhood policy engineand atoolthat reads the Lustre changelog and synchronises metadata with the archived storage. Thelfsazsyncrepository on GitHub contains a Bicep template to deploy and setup a virtual machine for this purpose.
Disclaimer: Thelfsazsyncdeployment is not a supported Microsoft product you are responsible for the deployment and operation of the solution. There are updates that need applying to AMLFS that will require a Support Request to be raised through the Azure Portal. These updates could effect the stabaility of AMLFS and customer requiring the same level of SLA should speak to their Microsoft representative.
Initial Deployment
The following is required before running thelfsazsyncBicep template:
Virtual Network
Azure BLOB Storage Account and container (HNS is not supported)
AMLFS deployedwithout HSM enabled
Thelfsazsyncrepository contains atest/infra.bicepexample to create the required resources:
To deploy, first create a resource group, e.g.
TODO: set the variables below
resource_group=
location=
az group create –name $resource_group –location $location
Then deploy into this resource group:
az deployment group create –resource-group $resource_group –template-file test/infra.bicep
Note: The bicep file has parameters for names, ip ranges etc. that should be set if you do not want the default values.
Updating the AMLFS settings
Once deployment is complete, navigate to the Azure Portal, locate the AMLFS resource and click on “New Support Request”. The following shows the suggested request to get AMLFS updated:
Thelfsazsyncdeployment sets up a single virtual machine for all tasks. The HSM copytools could be run on multiple virtual machines to increase transfer peformance. The bandwidth for archiving and retrieval is constrained to approximately half the network bandwidth available to the virtual machine. It is important to note that the same network will be utilized for both accessing the Lustre filesystem and accessing Azure Storage. This should be considered when deciding the virtual machine size. The virtual machine sizes and expected network performance is availablehere.
The Bicep template has the following parameters:
Parameter
Description
subnet_id
The ID of the subnet to deploy the virtual machine to
vm_sku
The SKU of the virtual machine to deploy
admin_user
The username of the administrator account
ssh_key
The public key for the administrator account
lustre_mgs
The IP address/hostname of the Lustre MGS
storage_account_name
The name of the Azure storage account
storage_container_name
The container to use for synchonising the data
storage_account_key
A SAS key for the storage account
ssh_port
The port used by sshd on the virtual machine
github_release
Release tag where the robinhood and lemur will be downloaded from
os
The OS to use for the VM (options: ubuntu2004 or almalinux87)
The SAS key can be generated using the following Azure CLI command:
# TODO: set the account name and container name below
account_name=
container_name=
The following Azure CLI command can be used to get the subnet ID:
# TODO: set the variable below
resource_group=
vnet_name=
subnet_name=
az network vnet subnet show –resource-group $resource_group –vnet-name $vnet_name –name $subnet_name –query id –output tsv
The following Azure CLI command can be used to deploy the Bicep template (as an alterative to setting environment variables, the parameters could be set in aparameters.jsonfile):
# TODO: set the variables below
resource_group=
subnet_id=
vmsku=”Standard_D32ds_v4″
admin_user=
ssh_key=
lustre_mgs=
storage_account_name=
storage_container_name=
storage_sas_key=
ssh_port=
github_release=”v1.0.1″
os=”almalinux87″
az deployment group create
–resource-group $resource_group
–template-file lfsazsync.bicep
–parameters
subnet_id=”$subnet_id”
vmsku=$vmsku
admin_user=”$admin_user”
ssh_key=”$ssh_key”
lustre_mgs=$lustre_mgs
storage_account_name=$storage_account_name
storage_container_name=$storage_container_name
storage_sas_key=”$storage_sas_key”
ssh_port=$ssh_port
github_release=$github_release
os=$os
After this call completes the virtual machine will be deployed although it will take more time to install and import the metadata from Azure BLOB storage into the Lustre filesystem. The progress can be monitored by looking at the/var/log/cloud-init-output.logfile on the virtual machine.
Monitoring
The install will set up three systemd services for lhsmd, robinhood and lustremetasync. The log files are located here:
‘lhsmd’: /var/log/lhsmd.log
‘robinhood’: /var/log/robinhood*.log
‘lustremetasync’: /var/log/lustremetasync.log
Default archive settings
The synchronisation parameters can be controlled through the Robinhood config file,/opt/robinhood/etc/robinhood.d/lustre.conf. Below are some of the default settings and their locations in the config file:
Name
Default
Location
Archive interval
5 minutes
lhsm_archive_parameters.lhsm_archive_trigger
Rate limit
1000 files
lhsm_archive_parameters.rate_limit.max_count
Rate limit interval
10 seconds
lhsm_archive_parameters.rate_limit.period_ms
Archive threshold
last modified time > 30 minutes
lhsm_archive_parameters.lhsm_archive_rules
Release trigger
85% of OST usage
lhsm_archive_parameters.lhsm_release_trigger
Small file release
last access > 1 year
lhsm_archive_parameters.lhsm_release_rules
Default file release
last access > 1 day
lhsm_archive_parameters.lhsm_release_rules
File remove
removal time > 5 minutes
lhsmd.lhsmd_remove_rules
To update the config file, edit the file and then restart the robinhood service,systemctl restart robinhood.
The lustremetasync service is processing the Lustre ChangeLog continuously. Therefore, actions will happen immediately unless there is a lot of IO all at once where it may take a few minutes to catch up. The following operations will be handled:
Create/delete directories
Directories are created in BLOB storage as an empty object with the name of the directory. There is metadata on this file to indicate that it is a directory. The same object is deleted when removed on the filesystem.
Create/delete symbolic links
Symbolic links are create in BLOB storage as an empty object with the name of the symbolic link. There is metadata on this file to indicate that it is a symbolic link and this contains the path that it is linking to. The same object is deleted when removed on the filesystem.
Moving files or directories
Moving files or directories requires everything being moved to be restored to the Lustre filesystem. The files are then marked as dirty in their new location and the existing files are deleted from BLOB storage. Robinhood will handle archiving the files again in their new location.
Updating metadata (e.g. ownership and permissions)
The metadata will only be updated for archived files that isn’t modified. Modified files will have the metadata set when Robinhood updated the archived file.
This article is contributed. See the original author and article here.
Welcome to an introduction of the concepts and simple approachrequiredfor executing a successful Proof of Concept (PoC) forMicrosoft Defender External Attack Surface Management (Defender EASM). This article will serve as a high-level guide to help you executea simple framework forevaluating Defender EASM, and other itemsto consider when embarking on the journey tounderstandthe Internet exposed digital assets that comprise your external attack surface, so you can view risks through the same lens as a malicious threat actor.
Planning for the PoC
To ensure success, the first step is planning. This entails understanding the value of Defender EASM, identifying stakeholders who need to be involved, and scheduling planning sessions to determineuse cases & requirements and scope before beginning.
For example, one of the core benefits of the Defender EASM solution is that it provides high value visibility to Security and IT (Information Technology) teams that enables them to:
Identify previously unknown assets
Prioritize risk
Eliminate threats
Extends vulnerability and exposure control beyond the firewall
Next, you should identify all relevant stakeholders, or personas, and schedule in 1-2 short planning sessions to document the tasks and expected outcomes, or requirements. These sessions will establish the definition of success for the PoC.
Who are the common stakeholders that should participate in the initial planning sessions? The answer to that question will be unique to each organization, but some common personas include the following:
Vulnerability Management Teams
IT personnel responsible for Configuration Management, Patching, Asset Inventory Databases
Governance, Risk, & Compliance (GRC) Teams
(Optional) GRC aligned Legal, Brand Protection, & Privacy Teams
Internal Offensive Penetration Testing and Red Teams
Security Operations Teams
Incident Response Teams
Cyber Threat Intelligence, Hunting, and Research Teams
Use Cases & Requirements
Based on the scope, you can begin collaborating with the correct people to establish use cases & requirements to meet the business goals for the PoC. The requirements should clearly define the subcomponents of the overarching business goals within the charter of your External Attack Surface Management Program. Examples of business goals and high-level supporting requirements might include:
Discover Uknown Assets
Find Shadow IT
Discover Abandoned Assets
Resulting from Mergers, Acquistions, or Divestitures
Insufficient Asset Lifecycle Management in Dev/Test/QA Environments
Identification of Vulnerabilities
Lack of Patching or Configuration Management
Assignment of Ownership to Assets
Line of Business or Subsidiary
Based on Geographic Location
On-Prem vs Cloud
Reporting, Automation, and Defender EASM Data Integrations
Determining how success will establish the criteria for a successful or failed PoC. Success and Acceptance Criteria should be established for each requirement identified. Weights may be applied to requirements, but measuring success can be as simple as writing out criteria as below:
Requirement: Custom Reporting
Success Criteria: As a vulnerability manager, I want to view a daily report that shows the assets with CVSSv2 and CVSSv3 scores of 10.
Acceptance Criteria:
Data must be exported to Kusto
Data must contain assets & CVSS (Common Vulnerability Scoring System) scores
Dashboards must be created with PowerBI and accessible to user
Dashboard data must be updated daily
Validation: Run a test to validate that acceptance criteria has been met.
Pass / Fail: Pass
Executing the PoC
Implementation and Technical Validation
We will now look at five different use cases & requirements, define the success andacceptance criteria for each, andvalidate that the requirements are met by observing the outcome of each in DefenderEASM.
Use Case 1:Discover Unknown Assets, Finding Shadow IT
Success Criteria: As a member of the Contoso GRC team, I want to identify Domain assets in our attack surface that have not been registered with the official company email address we use for domain registrations.
Acceptance Criteria:
Defender EASM allows for searches of Domain WHOIS data that returns the “Registrant Email” field in the result set.
Validation:
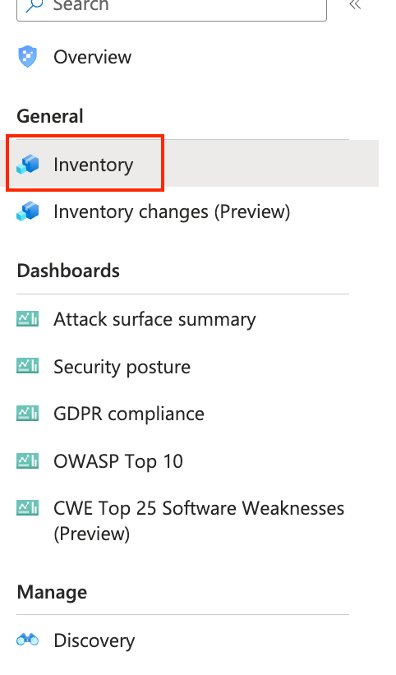
Click the “Inventory” link on the left of the main Defender EASM page.
Figure: Launch the inventory query screen
Execute a search in Defender EASM that excludes Domains registered with our official company email address of ‘domainadmin@constoso.com’ and returns all other Domains that have been registered with an email address that contains the email domain ‘contoso.com’.
Figure: Query for incorrectly registered Domain assets
Click on one of the domains in the result set to view asset details. For example, “woodgrovebank.com” domain.
When the asset details open and confirm that the domain ‘woodgrovebank.com’ is in the upper left corner.
Click on the “Whois” tab.
Note that this Domain asset has been registered with an email address that does not match the corporate standard (i.e., “employeeName@contoso.com”) and should be investigated for the existence of Shadow IT.
Success Criteria: As a member of the Contoso Vulnerability Management team, who just acquired Woodgrove Bank, I want to ensure acquired web sites using the domain “woodgrovebank.com” are redirected to web sites using the domain “contoso.com”. I need to obtain results of web sites that are not redirecting as expected, as those may be abandoned web sites.
Acceptance Criteria:
Defender EASM allows for search of specific initial and final HTTP (Hypertext Transfer Protocol) response codes for Page assets
Defender EASM allows for search of initial and final Uniform Resource Locator (URL) for Page assets
Validation:
Run a search in Defender EASM that looks for Page assets that have:
Initial response codes that cause HTTP redirects (i.e., “301”, “302”)
Initial URLs that contain “woodgrovebank.com”
Final HTTP response codes of “200”
Final URL, post HTTP redirect, that do not contain “contso.com”
Figure: Query for incorrect page redirection
Click one of the Page assets in the result set to see the asset details.
Use Case 3: Identification of Vulnerabilities, Lack of Patching or Configuration Management
Success Criteria: As a member of the Contoso Vulnerability Management team, I need the ability to retrieve a list of assets with high priority vulnerabilities and remediation guidance in my attack surface.
Acceptance Criteria:
Defender EASM provides a dashboard of prioritized risks in my external attack surface
Defender EASM provides remediation guidance for each prioritized vulnerability
Defender EASM provides an exportable list of assets impacted by vulnerability
Validation:
From the main Defender EASM page, click “Attack Surface Summary” to view the “Attack Surface Summary” dashboard
Click the link that indicates the number of assets impacted by a specific vulnerability to view a list of impacted assets
Figure: Attack Surface Insights Dashboard
Validate that Defender EASM provides additional information about vulnerabilities and remediation guidance.
Click the link in the upper right corner titled “Download CSV report” and validate the contents within
Use Case 4: Assignment of Ownership to Assets, Line of Business or Subsidiary
Success Criteria: As a member of the Contoso GRC team, I need the ability to assign ownership of assets to specific business units through, along with a mechanism to quickly visualize this relationship.
Acceptance Criteria:
Defender EASM provides an approach to assigning ownership via labels
Defender EASM allows users to apply labels to assets that meet specific indicators that indicate affiliation with a specific business unit
Defender EASM provides the ability to apply labels in bulk
Validation:
Click the “Inventory” link on the left of the main Defender EASM page to launch the search screen
Run a search that returns all Page assets that are on the IP Block “10.10.10.0/24”. The Page assets on this network all belong to the Financial Services line of business, so it is the only indicator of ownership needed in this example.
Figure: Query to determine Page asset ownership by IP Block
Select all assets in the result set by clicking the arrow to the right of the checkbox as shown in the following image and choose the option for all assets.
Figure: Selecting assets for bulk modification
Click the link to modify assets, followed by the link to “Create a new label” on the blade that appears.
A new screen will appear that allows the creation of a label. Enter a descriptive “Label name”, an optional “Display name”, select a desired color, and click “Add” to finish creating a label.
Figure: Link to modify assets and create a label
Figure: Create label detail
After creating the label, you will be directed back to the screen to modify assets. Validate that the label was created successfully.
Click into the label text box to see a list of labels available to choose from and select the one that was just created.
Click “Update”
Figure: Label selected assets
Click the bell icon to view task notifications to validate the status of labels update.
Figure: View status of label update task
When the task is complete, run the search again to validate that labels have been applied to the assets owned by the Financial Services organization.
Figure: Query to validate labels have been applied to assets
Identify how the Defender EASM solution has provided increased visibility to your organization’s attack surface in the PoC.
Have you discovered unknown assets related to Shadow IT?
Were you able to find potentially abandoned assets related to an acquisition?
Has your organization been able to better prioritize vulnerabilities to focus on the most severe risks?
Do you know have a better view of asset ownership in your organization?
Feedback?
We would love to hear any ideas you may have to improve our Defender EASM platform or where and how you might use Defender EASM data elsewhere in the Microsoft Security ecosystem or other security 3rd party applications. Please contact us via email at mdesam-pm@microsoft.com to share any feedback you have regarding Defender EASM.
Interested in Learning About New Defender EASM Features?
Please join our Microsoft Security Connection Program if you are not a member and follow our Private & Public Preview events. You will not have access to this exclusive Teams channel until you complete the steps to become a Microsoft Security Connection Program member. Users that would like to influence the direction/strategy of our security products are encouraged to participate in our Private Preview events. Members who participate in these events will earn credit for respective Microsoft product badges delivered by Credly.
Conclusion
You now understand how to execute a simple Defender EASM PoC, to include deploying your first Defender EASM resource, identifying common personas, how to set requirements, and measure success. Do not forget! – you can enjoy a free 30-day trial by clicking on the link below.
This article is contributed. See the original author and article here.
This post is co-authored by John Ryan, Manager Functional Architect Dynamics 365 Field Service, Avanade.
One of the most exciting things about the introduction of AI into tools people use every day to do their jobs is the way AI can help revolutionize the way people work. Especially at the frontlines of business, AI provides organizations with innovative and personalized ways to serve customers. According to IDC, 28% of organizations are investing significantly in generative AI.1 This is what’s exciting about the introduction of Copilot in Microsoft Dynamics 365 Field Service.
No doubt about it: modern solutions like Microsoft Dynamics 365 Field Service have already come a long way in helping frontline workers be more productive and efficient in helping customers. But Copilot takes things to the next level by bringing the power of next-generation AI to the frontlines, enabling faster resolution and better service.
Streamline Field Service operations with Copilot
Copilot provides a leap forward in the field service space.
Enabling next-level support with Copilot for Field Service in Outlook and Microsoft Teams
Email has long been a critical communications tool for frontline managers and technicians. New data from Microsoft’s 2023 Work Trend Index Annual Report reveals that over 60% of frontline workers struggle with having to do repetitive or menial tasks that take time away from more meaningful work.2 Now, the Copilot in Dynamics 365 Field Service Outlook add-in can streamline work order creation with relevant details pre-populated from emails.
So, what does that mean, exactly? Copilot can also optimize technician scheduling with data-driven recommendations based on factors such as travel time, availability, and skillset. Frontline managers can see relevant work orders and review them before creating new work orders, and they can easily reschedule or update those work orders as customers’ needs change. In addition, organizations can customize work orders for their frontline needs by adding, renaming, or rearranging fields. Even better, Copilot can assist frontline managers with work order scheduling in Microsoft Teams, saving time and effort to find the right worker for the job.
Frontline managers can also easily open the Field Service desktop app directly from the Copilot add-in via Outlook or Teams to view work orders. There, they can see booking suggestions in the work order and book a field technician without opening the schedule board. The booking is created in Microsoft Dataverse and also gets recorded on the Field Service schedule board automatically. All this saves frontline managers valuable time because they can stay in the flow of work, reduce clicks and context-switching between apps, and create work orders quickly without copy/paste errors. In the Field Service app, they can also review work order list views and edit a work order right in the list without having to reopen it.
Getting answers faster with natural language search with Copilot in Teams
Searching work orders to find specific details about customer jobs or looking for information about parts inventory used to mean switching between apps and searching across different sources for information. Now, to search for work orders or other customer data, agents can ask Copilot through a Teams search. They simply ask what they’re looking for using natural language, and Copilot will return specific information related to their work orders in Dynamics 365 Field Service including status updates, parts needed, or instructions to help them complete the job. The more agents use Copilot, the more the AI assistant learns and can assist agents at their jobs. The future is now.
Empowering field technicians with modern user experience
Frontline managers aren’t the only team members getting a productivity boost from more modern tools. The new Dynamics 365 Field Service mobile experience, currently in preview for Windows 10 and higher, iOS, and Android devices, empowers field technicians by giving them all the relevant, most up-to-date information they need to manage work orders, tasks, services, and products and get their jobs done thoroughly and efficiently. This modern user experience supports familiar mobile navigation, gestures, and controls to streamline managing work order Tasks, Services, and Products. Technicians can save valuable time by quickly updating the status of a booking, getting driving directions to a customer site, and changing or completing work order details. They can even get detailed information about tasks with embedded Microsoft Dynamics 365 Guides, which provide step-by-step instructions, pictures, and videos.
Changing the game for frontline technicians with Copilot in mobile
For field service technicians, having Copilot generate work order summaries that include concise, detailed descriptions of services as well as pricing and costs is a game changer. Work order summaries are generated by Copilot on the fly, synthesizing information from various tabs and fields to break down tasks, parts, services, and problem descriptions into a simple narrative, making it easy for technicians to understand job requirements. And because field technicians often need to work with their hands, they can use the voice-to-text feature to update work orders by describing details including exactly what they did on a job, when they started and finished, and what parts they used. When the work is completed, they can use the app to collect a digital signature from the customer or use voice-to-text to capture customer feedback.
Learn more about the AI-powered experiences in Dynamics 365 Field Service, Teams, and Microsoft’s mixed reality applications for your frontline workforce announced at Microsoft Ignite 2023:
[1] IDC Analyst Brief sponsored by Microsoft, Generative AI and Mixed Reality Power the Future of Field Service Resolution (Doc #US51300223), October 2023
[2] The Work Trend Index survey was conducted by an independent research firm, Edelman Data x Intelligence, among 31,000 full-time employed or self-employed workers across 31 markets, 6,019 of which are frontline workers, between February 1, 2023, and March 14, 2023. This survey was 20 minutes in length and conducted online, in either the English language or translated into a local language across markets. One thousand full-time workers were surveyed in each market, and global results have been aggregated across all responses to provide an average. Each market is evenly weighted within the global average. Each market was sampled to be representative of the full-time workforce across age, gender, and region; each sample included a mix of work environments (in-person, remote vs. non-remote, office settings vs. non-office settings, etc.), industries, company sizes, tenures, and job levels. Markets surveyed include: Argentina, Australia, Brazil, Canada, China, Colombia, Czech Republic, Finland, France, Germany, Hong Kong, India, Indonesia, Italy, Japan, Malaysia, Mexico, Netherlands, New Zealand, Philippines, Poland, Singapore, South Korea, Spain, Sweden, Switzerland, Taiwan, Thailand, United Kingdom, United States, and Vietnam.
This article is contributed. See the original author and article here.
We are excited to announce that Personal Desktop Autoscale on Azure Virtual Desktop is generally available as of November 15, 2023! With this feature, organizations with personal host pools can optimize costs by shutting down or hibernating idle session hosts, while ensuring that session hosts can be started when needed.
Personal Desktop Autoscale
Personal Desktop Autoscale is Azure Virtual Desktop’s native scaling solution that automatically starts session host virtual machines according to schedule or using Start VM on Connect and then deallocates or hibernates (in preview) session host virtual machines based on the user session state (log off/disconnect).
The following capabilities are now generally available with Personal Desktop Autoscale:
Scaling plan configuration data can be stored in all regions where Azure Virtual Desktop host pool objects are, including Australia East, Canada Central, Canada East, Central US, East US, East US 2, Japan East, North Central US, North Europe, South Central US, UK South, UK West, West Central US, West Europe, West US, West US 2, and West US 3. It needs to be stored in the same region as the host pool objects it will be assigned to, however, we support deploying session host virtual machines in all Azure regions.
You can use the Azure portal, REST API, PowerShell to enable and manage Personal Desktop Autoscale.
The following capabilities are new in public preview with Personal Desktop Autoscale:
Hibernation is available as a scaling action. With the Hibernate-Resume feature in public preview, you will have a better experience as session state persists when the virtual machine hibernates. As a result, when the session host virtual machine starts, the user will be able to quickly resume where they left off. More details of the Hibernate-Resume feature can be found here.
Getting started
To enable Personal Desktop Autoscale, you need to:
Create a personal scaling plan.
Define whether to enable or disable Start VM on Connect.
Choose what action to perform after a user session has been disconnected or logged off for a configurable period of time.
Assign a personal scaling plan to one or more personal host pools.
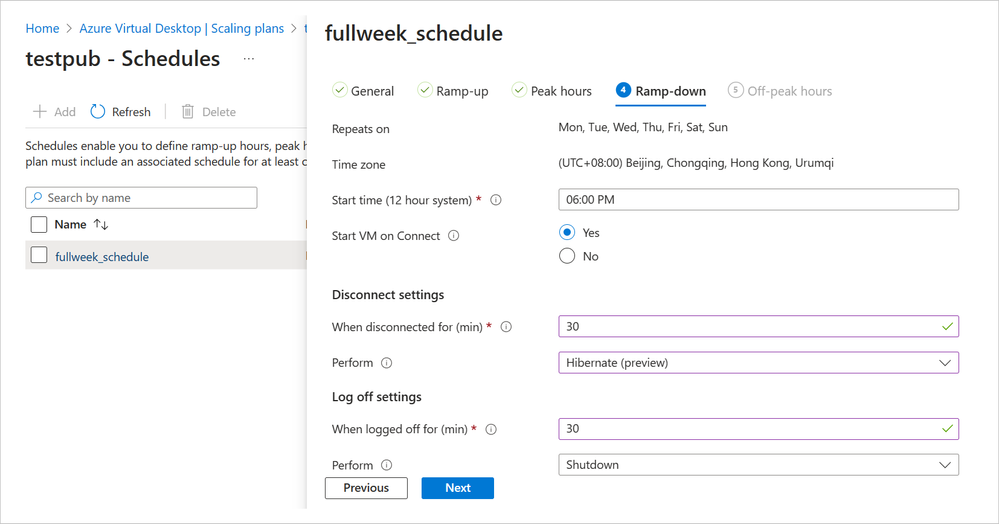
A screenshot of a scaling plan in Azure Virtual Desktop called “fullweek_schedule”. The ramp-down is shown as repeating every day of the week at 6:00 PM Beijing time, starting VM on Connect. Disconnect settings are set to hibernate at 30 minutes. Log off settings are set to shut down after 30 minutes.
If you want to use Personal Desktop Autoscale with the Hibernate-Resume option, you will need to self-register your subscription and enable Hibernate-Resume when creating VMs for your personal host pool. We recommend you create a new host pool of session hosts and virtual machines that are all enabled with Hibernate-Resume for simplicity. Hibernation can also work with Start VM on Connect for cost optimization.
You can set up diagnostics to monitor potential issues and fix them before they interfere with your Personal Desktop Autoscale scaling plan.
This article is contributed. See the original author and article here.
Azure AI Health Insights: New built-in models for patient-friendly and radiology insights
Azure AI Health Insights is an Azure AI service with built-in models that enable healthcare organizations to find relevant trials, surface cancer attributes, generate summaries, analyze patient data, and extract information from medical images.
Earlier this year, we introduced two new built-in models available for preview. These built-in models handle patient data in different modalities, perform analysis on the data, and provide insights in the form of inferences supported by evidence from the data or other sources.
The following models are available for preview:
Patient-friendly reports model* This model simplifies medical reports and creates a patient-friendly simplified version of clinical notes while retaining the meaning of the original clinical information. This way, patients can easily consume their clinical notes in everyday language. Patient-friendly reports model is available in preview.
Radiology insights model* This model uses radiology reports to surface relevant radiology insights that can help radiologists improve their workflow and provide better care. Radiology insights model is available in preview.
Simplify clinical reports
Patient-friendly reports is an AI model that provides an easy-to-read version of a patient’s clinical report. The simplified report explains or rephrases diagnoses, symptoms, anatomies, procedures, and other medical terms while retaining accuracy. The text is reformatted and presented in plain language to increase readability. The model simplifies any medical report, for example a radiology report, operative report, discharge summary, or consultation report.
The Patient-friendly reports model uses a hybrid approach that combines GPT models, healthcare-specialized Natural Language Processing (NLP) models, and rule-based methods. Patient-friendly reports also uses text alignment methods to allow mapping of sentences from the original report to the simplified report to make it easy to understand.
The system uses scenario-specific guardrails to detect hallucinations, omissions, and any other ungrounded content and does several steps to ensure the full information from the original clinical report is kept and no new additional information is added.
The Patient-friendly reports model helps healthcare professionals and patients consume medical information in a variety of scenarios. For example, Patient-friendly reports model saves clinicians the time and effort of explaining a report. A simplified version of a clinical report is generated by Patient-Friendly reports and shared with the patient, side by side with the original report. The patient can review the simplified version to better understand the original report, and to avoid unnecessary communication with the clinician to help with interpretation. The simplified version is marked clearly as text that was generated automatically by AI, and as text that must be used together with the original clinical note (which is always the source of truth).
Figure 1 Example of a simplified report created by the patient-friendly reports model
Improve the quality of radiology findings and flag follow-up recommendations
Radiology insights is a model that provides quality checks with feedback on errors and mismatches and ensures critical findings within the report are surfaced and presented using the full context of a radiology report. In addition, follow-up recommendations and clinical findings with measurements (sizes) documented by the radiologist are flagged.
Radiology insights inferences, with reference to the provided input that can be used as evidence for deeper understanding of the conclusions of the model. The radiology insights model helps radiologists improve their reports and patient outcomes in a variety of scenarios. For example:
Surfaces possible mismatches. A radiologist can be provided with possible mismatches between what the radiologist documents in a radiology report and the information present in the metadata of the report. Mismatches can be identified for sex, age and body site laterality.
Highlights critical and actionable findings. Often, a radiologist is provided with possible clinical findings that need to be acted on in a timely fashion by other healthcare professionals. The model extracts these critical or actionable findings where communication is essential for quality care.
Flags follow-up recommendations. When a radiologist uncovers findings for which they recommend a follow up, the recommendation is extracted and normalized by the model for communication to a healthcare professional.
Extracts measurements from clinical findings. When a radiologist documents clinical findings with measurements, the model extracts clinically relevant information pertaining to the findings. The radiologist can then use this information to create a report on the outcomes as well as observations from the report.
Assists generate performance analytics for a radiology team. Based on extracted information, dashboards and retrospective analyses, Radiology insights provides updates on productivity and key quality metrics to guide improvement efforts, minimize errors, and improve report quality and consistency.
Figure2 Example of a finding with communication to a healthcare professional
Figure 3 Example of a radiology mismatch (sex) between metadata and content of a report with a follow-up recommendation
Get started today
Apply for the Early Access Program (EAP) for Azure AI Health Insights here.
After receiving confirmation of your entrance into the program, create and deployAzure AI Health Insightson Azure portal or from the command line.
Figure 4 Example of how to create an Azure Health Insights resource on Azure portal
After a successful deployment, you send POST requests with patient data and configuration as required by the model you would like to try and receive responses with inferences and evidence.
Do more with your data with Microsoft Cloud for Healthcare
With Azure AI Health Insights, health organizations can transform their patient experience, discover new insights with the power of machine learning and AI, and manage protected health information (PHI) data with confidence. Enable your data for the future of healthcare innovation with Microsoft Cloud for Healthcare.
We look forward to working with you as you build the future of health.
Patient-friendly reports models and radiology insights model are capabilities provided “AS IS” and “WITH ALL FAULTS.” Patient-friendly reports and Radiology insights aren’t intended or made available for use as a medical device, clinical support, diagnostic tool, or other technology intended to be used in diagnosis, cure, mitigation, treatment, or prevention of disease or other conditions, and no license or right is granted by Microsoft to use this capability for such purposes. These capabilities aren’t designed or intended to be implemented or deployed as a substitute for professional medical advice or healthcare opinion, diagnosis, treatment, or the clinical judgment of a healthcare professional, and should not be used as such. The customer is solely responsible for any use of Patient-friendly reports model or Radiology insights model.
This article is contributed. See the original author and article here.
A few days ago, a customer asked us to find out details about the active connections of a connection pooling, how many connection poolings their application has, etc. In this article, I would like to share the lessons learned to see these details.
Once we executed our application we started seeing the following information:
2023-11-26 09:38:18.998: Actual active connections currently made to servers 0
2023-11-26 09:38:19.143: Active connections retrieved from the connection pool 0
2023-11-26 09:38:19.167: Number of connections not using connection pooling 0
2023-11-26 09:38:19.176: Number of connections managed by the connection pool 0
2023-11-26 09:38:19.181: Number of active unique connection strings 1
2023-11-26 09:38:19.234: Number of unique connection strings waiting for pruning 0
2023-11-26 09:38:19.236: Number of active connection pools 1
2023-11-26 09:38:19.239: Number of inactive connection pools 0
2023-11-26 09:38:19.242: Number of active connections 0
2023-11-26 09:38:19.245: Number of ready connections in the connection pool 0
2023-11-26 09:38:19.272: Number of connections currently waiting to be ready 0
As our application is using a single connection string and using a single connection pooler, the details that appear below are stable and understandable. But let’s make a couple of changes to the code to see how the numbers change.
Our first change will be to open 100 connections and once we reach those 100, we will close and reopen them to see how the counters fluctuat. The details we observe while our application is running indicate that connections are being opened but not closed. Which is expected.
2023-11-26 09:49:01.606: Actual active connections currently made to servers 13
2023-11-26 09:49:01.606: Active connections retrieved from the connection pool 13
2023-11-26 09:49:01.607: Number of connections not using connection pooling 0
2023-11-26 09:49:01.607: Number of connections managed by the connection pool 13
2023-11-26 09:49:01.608: Number of active unique connection strings 1
2023-11-26 09:49:01.608: Number of unique connection strings waiting for pruning 0
2023-11-26 09:49:01.609: Number of active connection pools 1
2023-11-26 09:49:01.609: Number of inactive connection pools 0
2023-11-26 09:49:01.610: Number of active connections 13
2023-11-26 09:49:01.610: Number of ready connections in the connection pool 0
2023-11-26 09:49:01.611: Number of connections currently waiting to be ready 0
But as we keep closing and opening new ones, we start to see how our connection pooling is functioning
2023-11-26 09:50:08.600: Actual active connections currently made to servers 58
2023-11-26 09:50:08.601: Active connections retrieved from the connection pool 50
2023-11-26 09:50:08.601: Number of connections not using connection pooling 0
2023-11-26 09:50:08.602: Number of connections managed by the connection pool 58
2023-11-26 09:50:08.602: Number of active unique connection strings 1
2023-11-26 09:50:08.603: Number of unique connection strings waiting for pruning 0
2023-11-26 09:50:08.603: Number of active connection pools 1
2023-11-26 09:50:08.604: Number of inactive connection pools 0
2023-11-26 09:50:08.604: Number of active connections 50
2023-11-26 09:50:08.605: Number of ready connections in the connection pool 8
2023-11-26 09:50:08.605: Number of connections currently waiting to be ready 0
In the following example, we can see how once we have reached our 100 connections, the connection pooler is serving our application the necessary connection.
2023-11-26 09:53:27.602: Actual active connections currently made to servers 100
2023-11-26 09:53:27.602: Active connections retrieved from the connection pool 92
2023-11-26 09:53:27.603: Number of connections not using connection pooling 0
2023-11-26 09:53:27.603: Number of connections managed by the connection pool 100
2023-11-26 09:53:27.604: Number of active unique connection strings 1
2023-11-26 09:53:27.604: Number of unique connection strings waiting for pruning 0
2023-11-26 09:53:27.605: Number of active connection pools 1
2023-11-26 09:53:27.606: Number of inactive connection pools 0
2023-11-26 09:53:27.606: Number of active connections 92
2023-11-26 09:53:27.606: Number of ready connections in the connection pool 8
2023-11-26 09:53:27.607: Number of connections currently waiting to be ready 0
Let’s review the counters:
Actual active connections currently made to servers (100): This indicates the total number of active connections that have been established with the servers at the given timestamp. In this case, there are 100 active connections.
Active connections retrieved from the connection pool (92): This shows the number of connections that have been taken from the connection pool and are currently in use. Here, 92 out of the 100 active connections are being used from the pool.
Number of connections not using connection pooling (0): This counter shows how many connections are made directly, bypassing the connection pool. A value of 0 means all connections are utilizing the connection pooling mechanism.
Number of connections managed by the connection pool (100): This is the total number of connections, both active and idle, that are managed by the connection pool. In this example, there are 100 connections in the pool.
Number of active unique connection strings (1): This indicates the number of unique connection strings that are currently active. A value of 1 suggests that all connections are using the same connection string.
Number of unique connection strings waiting for pruning (0): This shows how many unique connection strings are inactive and are candidates for removal or pruning from the pool. A value of 0 indicates no pruning is needed.
Number of active connection pools (1): Represents the total number of active connection pools. In this case, there is just one connection pool being used.
Number of inactive connection pools (0): This counter displays the number of connection pools that are not currently in use. A value of 0 indicates that all connection pools are active.
Number of active connections (92): Similar to the second counter, this shows the number of connections currently in use from the pool, which is 92.
Number of ready connections in the connection pool (8): This indicates the number of connections that are in the pool, available, and ready to be used. Here, there are 8 connections ready for use.
Number of connections currently waiting to be ready (0): This shows the number of connections that are in the process of being prepared for use. A value of 0 suggests that there are no connections waiting to be made ready.
These counters provide a comprehensive view of how the connection pooling is performing, indicating the efficiency, usage patterns, and current state of the connections managed by the Microsoft.Data.SqlClient.
One thing, that pay my attention is Number of unique connection strings waiting for pruning This means that if there have been no recent accesses to the connection pooler, we might find that if there have been no connections for a certain period, the connection pooler will be eliminated, and the first connection that is made will take some time (seconds) to be recreated, for example, in the night when we might not have active workload:
Idle Connection Removal: Connections are removed from the pool after being idle for approximately 4-8 minutes, or if a severed connection with the server is detected.
Minimum Pool Size: If the Min Pool Size is not specified or set to zero in the connection string, the connections in the pool will be closed after a period of inactivity. However, if Min Pool Size is greater than zero, the connection pool is not destroyed until the AppDomain is unloaded and the process ends. This implies that as long as the minimum pool size is maintained, the pool itself remains active.
We could observe in Microsoft.Data.SqlClient in the file SqlClient-mainSqlClient-mainsrcMicrosoft.Data.SqlClientsrcMicrosoftDataProviderBaseDbConnectionPoolGroup.cs useful information about it:
Line 50: private const int PoolGroupStateDisabled = 4; // factory pool entry pruning method Line 268: // Empty pool during pruning indicates zero or low activity, but Line 293: // must be pruning thread to change state and no connections Line 294: // otherwise pruning thread risks making entry disabled soon after user calls ClearPool
These parameters work together to manage the lifecycle of connection pools and their resources efficiently, balancing the need for ready connections with system resource optimization. The actual removal of an entire connection pool (and its associated resources) depends on these settings and the application’s runtime behavior. The documentation does not specify a fixed interval for the complete removal of an entire connection pool, as it is contingent on these dynamic factors.
To conclude this article, I would like to conduct a test to see if each time I request a connection and change something in the connection string, it creates a new connection pooling.
For this, I have modified the code so that half of the connections receive a clearpool. As we could see new inactive connection pools shows.
2023-11-26 10:34:18.564: Actual active connections currently made to servers 16
2023-11-26 10:34:18.565: Active connections retrieved from the connection pool 11
2023-11-26 10:34:18.566: Number of connections not using connection pooling 0
2023-11-26 10:34:18.566: Number of connections managed by the connection pool 16
2023-11-26 10:34:18.567: Number of active unique connection strings 99
2023-11-26 10:34:18.567: Number of unique connection strings waiting for pruning 0
2023-11-26 10:34:18.568: Number of active connection pools 55
2023-11-26 10:34:18.568: Number of inactive connection pools 150
2023-11-26 10:34:18.569: Number of active connections 11
2023-11-26 10:34:18.569: Number of ready connections in the connection pool 5
2023-11-26 10:34:18.570: Number of connections currently waiting to be ready 0
Source code
using System;
using Microsoft.Data.SqlClient;
using System.Threading;
using System.IO;
using System.Diagnostics;
namespace HealthCheck
{
class ClsCheck
{
const string LogFolder = "c:tempMydata";
const string LogFilePath = LogFolder + "logCheck.log";
public void Main(Boolean bSingle=true, Boolean bDifferentConnectionString=false)
{
int lMaxConn = 100;
int lMinConn = 0;
if(bSingle)
{
lMaxConn = 1;
lMinConn = 1;
}
string connectionString = "Server=tcp:servername.database.windows.net,1433;User Id=username@microsoft.com;Password=Pwd!;Initial Catalog=test;Persist Security Info=False;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=5;Pooling=true;Max Pool size=" + lMaxConn.ToString() + ";Min Pool Size=" + lMinConn.ToString() + ";ConnectRetryCount=3;ConnectRetryInterval=10;Authentication=Active Directory Password;PoolBlockingPeriod=NeverBlock;Connection Lifetime=5;Application Name=ConnTest";
Stopwatch stopWatch = new Stopwatch();
SqlConnection[] oConnection = new SqlConnection[lMaxConn];
int lActivePool = -1;
string sConnectionStringDummy = connectionString;
DeleteDirectoryIfExists(LogFolder);
ClsEvents.EventCounterListener oClsEvents = new ClsEvents.EventCounterListener();
//ClsEvents.SqlClientListener olistener = new ClsEvents.SqlClientListener();
while (true)
{
if (bSingle)
{
lActivePool = 0;
sConnectionStringDummy = connectionString;
}
else
{
lActivePool++;
if (lActivePool == (lMaxConn-1))
{
lActivePool = 0;
for (int i = 0; i = 5)
{
Log($"Maximum number of retries reached. Error: " + ex.Message);
break;
}
Log($"Error connecting to the database. Retrying in " + retries + " seconds...");
Thread.Sleep(retries * 1000);
}
}
return connection;
}
static void Log(string message)
{
var ahora = DateTime.Now;
string logMessage = $"{ahora.ToString("yyyy-MM-dd HH:mm:ss.fff")}: {message}";
//Console.WriteLine(logMessage);
try
{
using (FileStream stream = new FileStream(LogFilePath, FileMode.Append, FileAccess.Write, FileShare.ReadWrite))
{
using (StreamWriter writer = new StreamWriter(stream))
{
writer.WriteLine(logMessage);
}
}
}
catch (IOException ex)
{
Console.WriteLine($"Error writing in the log file: {ex.Message}");
}
}
static void ExecuteQuery(SqlConnection connection)
{
int retries = 0;
while (true)
{
try
{
using (SqlCommand command = new SqlCommand("SELECT 1", connection))
{
command.CommandTimeout = 5;
object result = command.ExecuteScalar();
}
break;
}
catch (Exception ex)
{
retries++;
if (retries >= 5)
{
Log($"Maximum number of retries reached. Error: " + ex.Message);
break;
}
Log($"Error executing the query. Retrying in " + retries + " seconds...");
Thread.Sleep(retries * 1000);
}
}
}
static void LogExecutionTime(Stopwatch stopWatch, string action)
{
stopWatch.Stop();
TimeSpan ts = stopWatch.Elapsed;
string elapsedTime = String.Format("{0:00}:{1:00}:{2:00}.{3:00}",
ts.Hours, ts.Minutes, ts.Seconds,
ts.Milliseconds / 10);
Log($"{action} - {elapsedTime}");
stopWatch.Reset();
}
public static void DeleteDirectoryIfExists(string path)
{
try
{
if (Directory.Exists(path))
{
Directory.Delete(path, true);
}
Directory.CreateDirectory(path);
}
catch (Exception ex)
{
Console.WriteLine($"Error deleting the folder: {ex.Message}");
}
}
}
}
This article is contributed. See the original author and article here.
Introduction
APractical Guide for Beginners: Azure OpenAI with JavaScript and TypeScriptis an essential starting point for exploring Artificial Intelligence in the Azure cloud. This guide will be divided into 3 parts, covering: ‘How to create the Azure OpenAI Service resource,’ How to implement the model created in Azure OpenAI Studio, and finally, how to consume this resource in a Node.js/TypeScript application. This series will help you learn the fundamentals so that you can start developing your applications with Azure OpenAI Service. Whether you are a beginner or an experienced developer, discover how to create intelligent applications and unlock the potential of AI with ease.
Responsible AI
Before we start discussing Azure OpenAI Service, it’s crucial to talk about Microsoft’s strong commitment to the entire field of Artificial Intelligence. Microsoft is deeply dedicated to this topic. Therefore, Microsoft is committed to ensuring that AI is used in a responsible and ethical manner. Furthermore, Microsoft is working with the AI community to develop and share best practices and tools to help ensure that AI is used in a responsible and ethical way, thereby incorporating the six core principles, which are:
Fairness
Inclusivity
Reliability and Safety
Transparency
Security and Privacy
Accountability
If you want to learn more about Microsoft’s commitment to Responsible AI, you can access the linkMicrosoft AI Principles.
Now, we can proceed with the article!
Understand Azure OpenAI Service
Azure OpenAI Service provides access to advanced OpenAI language models such asGPT-4,GPT-3.5-Turbo, andEmbeddingsvia a REST API. The GPT-4 and GPT-3.5-Turbo models are now available for general use, allowing adaptation for tasks such as content generation, summarization, semantic search, and natural language translation to code. Users can access the service through REST APIs, Python SDK, or Azure OpenAI Studio.
To learn more about the models available in Azure OpenAI Service, you can access them through the linkAzure OpenAI Service models.
Create the Azure OpenAI Service Resource
The use of Azure OpenAI Service is limited. Therefore, it is necessary to request access to the service atAzure OpenAI Service. Once you have approval, you can start using and testing the service!
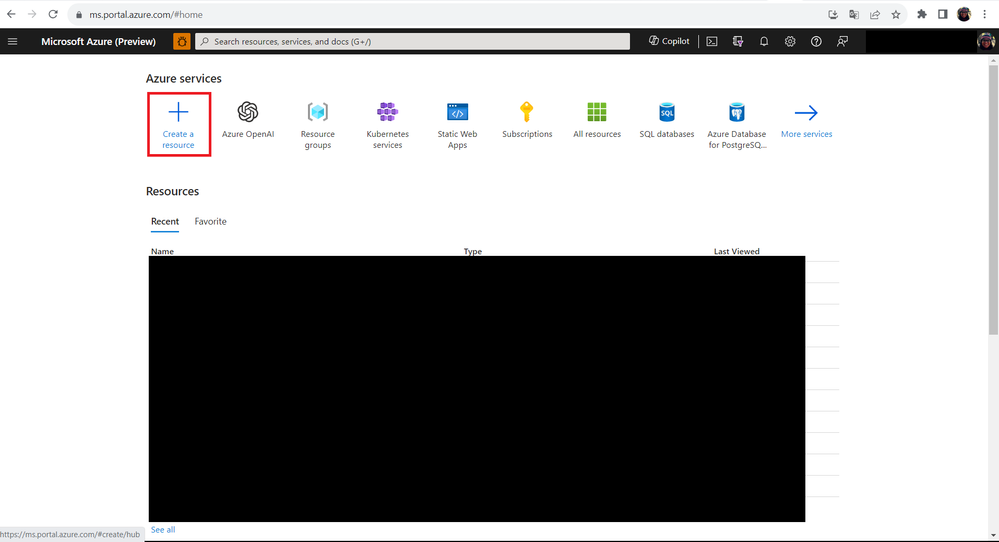
Once your access is approved, go to theAzure Portaland let’s create the Azure OpenAI resource. To do this, follow the steps below:
Step 01:Click on theCreate a resourcebutton.
Step 02:In the search box, typeAzure OpenAIand then clickCreate.
Step 03:On the resource creation screen, fill in the fields as follows:
Note that in thePricing tierfield, you can test Azure OpenAI Service for free but with some limitations. To access all features, you should choose a paid plan. For more pricing information, access the linkAzure OpenAI Service pricing.
Step 04:Under theNetworktab, choose the option:All networks, including the internet, can access this resource.and then clickNext.
Step 05:After completing all the steps, click theCreatebutton to create the resource.
Step 06:Wait a few minutes for the resource to be created.
Next steps
In the next article, we will learn how to deploy a model on the Azure OpenAI Service. This model will allow us to consume the Azure OpenAI Service directly in our code.
Oh, I almost forgot to mention! Don’t forget to subscribe to myYouTube Channel! In 2023/2024, there will be many exciting new things on the channel!
Some of the upcoming content includes:
Microsoft Learn Live Sessions
Weekly Tutorials on Node.js, TypeScript, & JavaScript
And much more!
If you enjoy this kind of content, be sure to subscribe and hit the notification bell to be notified when new videos are released. We already have an amazing new series coming up on the YouTube channel this week.





























Recent Comments