This article is contributed. See the original author and article here.
We are thrilled to announce the General Availability (GA) of the new User Experience (UX) in our Field Service Mobile (FSM) application! We heard your feedback during the preview period and are excited to mark this milestone with key enhancements and changes!
When we started this journey, our goal was to deliver an intuitive, modern user experience for frontline workers to streamline workflows and increase user satisfaction. We reduced the number of clicks taken by technicians to accomplish tasks in the app and enabled access to rich step by step instructions for troubleshooting. At Ignite, we announced the addition of Copilot capabilities to help technicians prepare for and document work easily, through Copilot Work Order Summarize and Update. Now, with GA, we have added several admin controls to allow for progressive enablement, new enhancements to the agenda and lists, and several performance and reliability improvements. Read on to learn the details!
GA Highlights of the New UX
1. Updated Agenda view with easy Copilot access
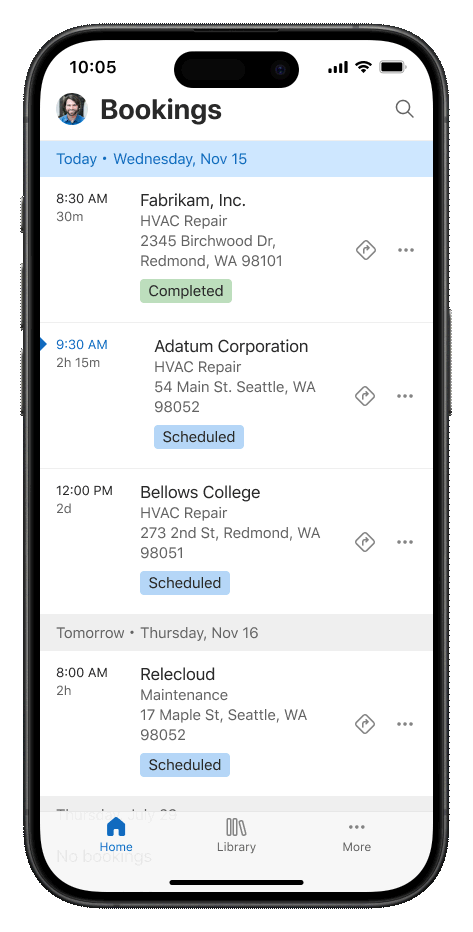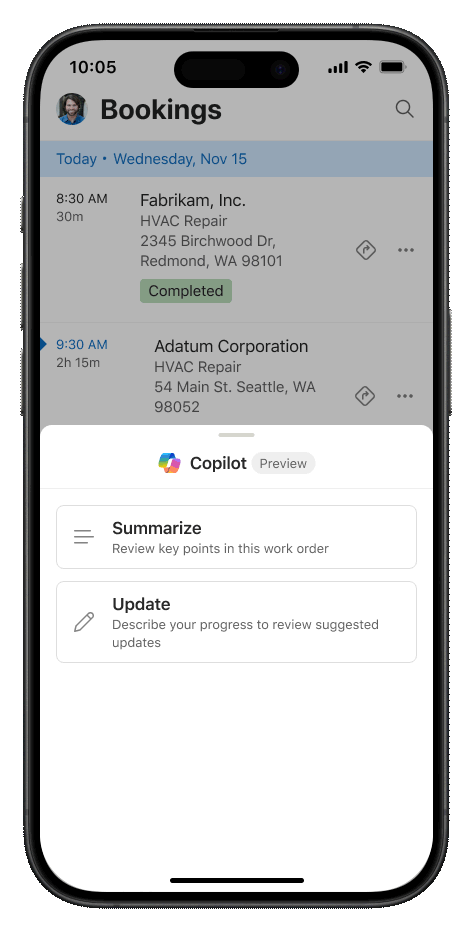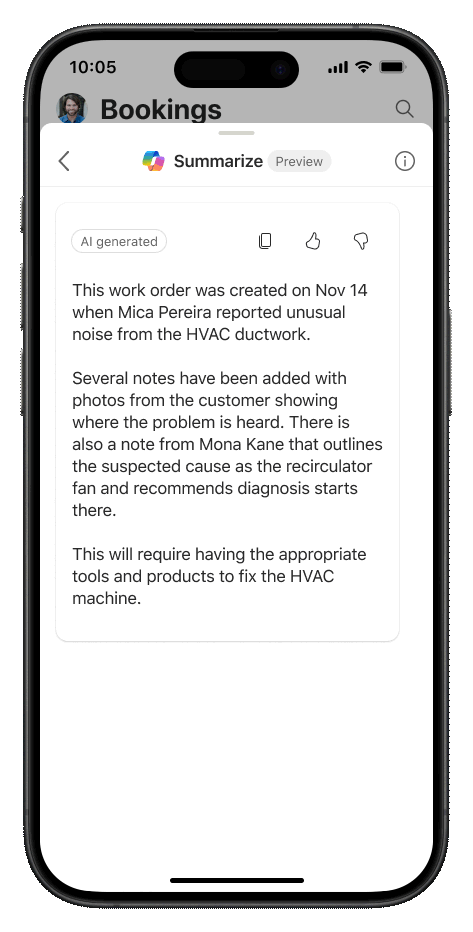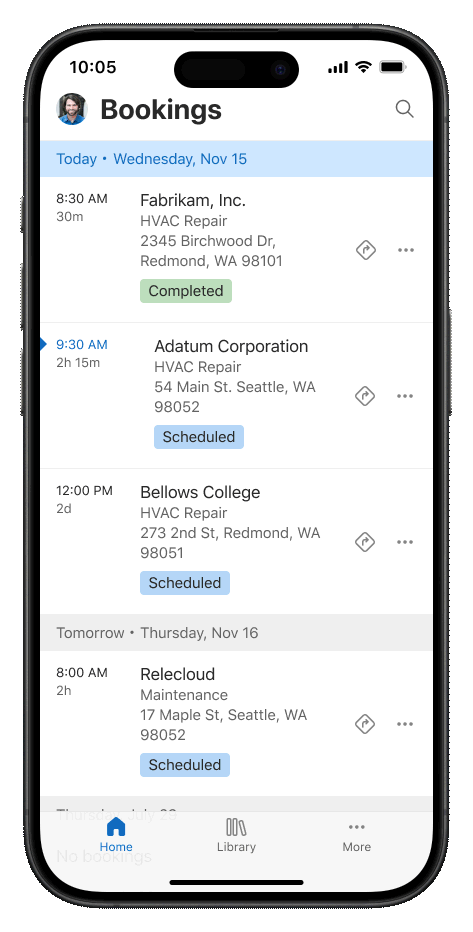
Customers loved the new Agenda experience in preview, which offers intuitive access for service technicians to view and update their bookings, featuring several handy shortcuts. In the GA version, we have introduced several enhancements. These include infinite bidirectional scrolling for quick access to past or future bookings, and visual updates to make it easier to distinguish between different statuses and bookings. Technicians need key information at their fingertips while on the job. Now, makers can customize and display additional information on the agenda based on specific scenarios. Lastly, Copilot (Preview) is now accessible on every booking. All it takes is a simple swipe gesture, allowing technicians to easily summarize or update a work order.
2. Modern configurable lists on mobile
Users spend a lot of time reviewing data in lists (or grids). We’re excited to announce all top-level lists in the mobile app are now part of the new UX – with the ability to configure and display 10 columns per row! With additional at-a-glance information available right in the list, users can avoid navigating into the form, improving clicks to complete the job and perceived performance. The new lists control also supports searching, sorting and landscape and portrait modes (which our tablet users love)!
3. Admin controls for progressive enablement
A key preview ask from makers was enabling gradual deployment of the new UX for their workforce for effective change management. We heard and delivered! The new UX for technicians works in the existing FSM app (no new app installs, or migration needed). Via the new FSM settings page, makers can quickly deploy this to a pilot group of users using security roles. And makers can turn on or off specific features such Copilot based on their organizational requirements.
4. Additional user settings
Besides look , feel, and navigation enhancements, users can also update their time zone and language settings within the app. They can also select their preferred maps app to use for navigation.
5. Fundamentals
Most importantly, with this release we’ve greatly enhanced performance and reliability of all new features. Whether scrolling in various lists to handling issues with actionable error messages, we’ve ensured users have a robust and delightful experience.
Closing thoughts
As with any technical milestone, we must also callout things that lie ahead of us. We’re looking forward to releasing the view selector inside the list control for users with multiple views. The Guides and Copilot features accessible from the new UX continue to be in preview (and can be turned off if desired).
As part of this GA, we are discontinuing the streamlined booking experience introduced during preview. Form-based experiences will continue to leverage the classic UCI experience in the app, which supports layout and business logic customization. And at present, users enabled for the offline mode will be taken directly to the classic UCI experience as well.
The launch of the new UX in Field Service Mobile marks a significant milestone in our mission to deliver the best tools and technology for frontline workers. We are confident that these innovative features and user-centric design will greatly enhance your daily operations, making your work more efficient and enjoyable.
Enable these features today and share your thoughts with us! We eagerly await your feedback and stay tuned for more updates!
This article is contributed. See the original author and article here.
Microsoft 365 offers the cloud-backed apps, security, and storage that customers worldwide rely on to achieve more in a connected world – and lays a secure foundation for leveraging generative AI to go even further. Investing in our cloud productivity solutions and the AI-powered innovation they support will continue to be Microsoft’s priority.
Still, we know that some customer scenarios require a different approach. Some devices must never be connected to the internet; others need to remain unchanged for years at a time. We remain committed to supporting our customers and these scenarios. Earlier this year, we offered a public preview of Microsoft Office Long Term Servicing Channel (LTSC) 2024. Today, we’re announcing the general availability of this next perpetual version of Office for commercial and government customers.
An updated solution for specialized needs
Office LTSC 2024 offers a locked-in-time version of familiar productivity tools, updated with a subset of the features that have been added to Microsoft 365 Apps for enterprise over the last three years. New features for this release include Dynamic Charts and more than a dozen new text and array functions in Excel, enhanced search and meeting creation options in Outlook, and improvements to performance, security, and accessibility. Learn more about what’s new.
Office LTSC 2024 will besupported forfive yearsunder theFixed Lifecycle Policy, and – like prior versions – will be deployable alongside Microsoft 365 Apps using a common set of tools to enable customers to more easily manage hybrid environments. Learn more about how to deploy and manage Office LTSC at Overview of Office LTSC 2024.
Choosing the best productivity suite for your organization
While Office LTSC 2024 offers many significant improvements over the previous Office LTSC release, as an on-premises product it does not include the cloud-based capabilities of Microsoft 365 Apps, like real-time collaboration, AI-driven automation, or cloud-backed security and compliance capabilities. And for customers who need additional flexibility on deployment and connectivity – but not a fully disconnected solution – Microsoft 365 has options that can help. For example, device-based licensing can simplify management of Microsoft 365 Apps in settings like computer labs or hospitals where devices are shared by many users. And extended offline access can be used to maintain access to Microsoft 365 Apps on devices that need to be disconnected from the internet for up to six months at a time. Microsoft 365 (or Office 365) is also required to subscribe to Microsoft 365 Copilot; as a disconnected product, Office LTSC does not qualify.
Microsoft 365 Apps [1]
Office LTSC 2024
Apps included
Word, Excel, PowerPoint, Outlook, OneNote, OneDrive, Microsoft Access (Windows Only), Microsoft Publisher (Windows Only) [2], Sway, Microsoft Forms
Word, Excel, PowerPoint, Outlook, OneDrive, OneNote, Microsoft Access (Windows Only) [3]
Internet connection required for activation, license validation, and internet-based functionality. Extended offline access available to enable devices to stay disconnected for up to six months at a time.
No internet connection required
Embracing the future of work
Microsoft 365 offers the most secure, productive, and cost-effective solution for most organizations, and positions customers to unlock the transformative power of AI with Microsoft 365 Copilot. Especially as we approach the end of support for Office 2016 and Office 2019 on October 14, 2025, we encourage customers still using these solutions to transition to a Microsoft 365 subscription that suits their needs as a small business or a larger organization. And for scenarios where that is not possible – where a disconnected, locked-in-time solution is required – this new release reflects our commitment to supporting that need.
Learn more
Office LTSC 2024 is available to existing commercial and government volume-licensed customers today, along with new on-premises versions of Project and Visio. These products will be generally available to all customers on October 1. We will share more about Office 2024 for consumers in the coming weeks. For more information about Office LTSC 2024 and how it compares to Microsoft 365 Apps for enterprise, please visit the Office LTSC plan comparison page. If your organization is ready to take the next step toward the AI-powered future, find out how to get started with Microsoft 365 today.
Notes:
[1] Applies to Microsoft 365 Apps for enterprise and Microsoft 365 Apps for business. All Microsoft 365 and Office 365 suites that include desktop apps also include everything listed here – and more. Learn about the available options.
[3] Microsoft Access is included only with Office LTSC Professional Plus.
[4] Microsoft 365 Copilot may not be available for all markets and languages. To purchase, customers must have a qualifying Microsoft 365 plan for enterprise or business.
This article is contributed. See the original author and article here.
We are introducing Wave 2 of Microsoft 365 Copilot innovation, with three key updates. From enterprises to small businesses, they help Copilot get better every day. Nearly 1,000 customers have given us direct feedback on Copilot, and we’ve made more than 700 product updates based on that feedback.
This article is contributed. See the original author and article here.
The Azure Storage product group is heading to the SNIA Developer Conference (SDC) 2024 in Santa Clara, California, USA from September 16th through September 18th. We have a large contingent of Product Managers and Engineers responsible for Azure Blob Storage and Azure Files presenting across multiple sessions at the conference as well as the Cloud Object Storage Plugfest.
If you’re attending the conference, stop by our sessions, listen in, say “Hello!” and introduce yourself as we demonstrate how Azure Storage can accommodate the largest AI training and AI inference workloads using Azure Blob Storage. Or if you’re a Files customer, stop by our sessions on Azure Files and SMB.
“I always compare Azure Arc to the Lord of the Rings, seeing it as the one ring to rule them all. If you’re seeking a solution to manage all your Windows and Linux servers, Azure Arc could be the answer. It provides a unified management experience across diverse environments, whether on-premises, in Azure, or other clouds.
Using Azure Arc, I’ve also gained valuable insights into other technologies, such as Kubernetes (AKS) and AWS, through its Multi-Cloud Connector. This feature enhances your ability to manage and govern resources across multiple cloud platforms seamlessly.
In essence, if you’re looking for a comprehensive solution to manage your hybrid and multi-cloud infrastructure efficiently, Azure Arc offers the tools and capabilities you need.”
*Relevant Blog: In my blog post I explained how to use pre and post events fro Azure Update Manager on Azure Arc Enabled Servers.
“This content is comprehensive, helping with the solution support of Azure Arc and the supported resources. Understanding how to innovate with Azure Arc is essential nowadays, and by contributing Azure Arc content to the community, without a doubt, this training is the one I most like to recommend.”
“Networking is core to Azure, and core to architecting excellent solutions. While the architecture center offers a range of guidance from foundational to niche, the networking section should be common to nearly all deployments. It is unique in its importance to Azure design.”
“Hyperscaler Cloud offerings, like Microsoft Azure, offer businesses worldwide to compete on a global stage, but with the ability to scale up business offerings comes more complexity and additional risk of outages. One of the key pillars (for good reason) of the Azure Well-Architected Framework is Resiliency, and Microsoft Learn offers a great way of checking off, using a data-validated approach, of not only your Resiliency at a Technical level, but Business as well, using resources, such as the Design review checklist for Reliability.”
This article is contributed. See the original author and article here.
At Microsoft Learn, we continually review and evolve our portfolio of Microsoft Certifications to help learners around the world stay up to date with the latest technologies in our fast-changing digital world, especially as AI skills become increasingly important in the workplace. Microsoft Certifications are globally recognized credentials that validate your skills for various job roles using these technologies.
According to the 2023 Skillsoft IT Skills & Salary report, 62% of those who earned certifications felt that the quality of their work improved. They’re also more engaged at work (47%) and perform their duties faster (45%). Whether you’re a student, a professional, or someone changing careers, earning a Microsoft Certification can help you accomplish your goals and demonstrate your commitment to continuous learning and improvement. This achievement can also help boost your confidence and credibility at work as you showcase your expertise to employers and customers.
What’s changing?
We regularly update our exam content, format, and delivery to help ensure that our exams are aligned with industry standards and best practices. In recent years, we’ve made significant investments in developing and launching new exams and certifications for critical roles that use Microsoft apps and services, like Azure, Microsoft 365, Dynamics 365, and Microsoft Power Platform.
We also review and adjust exam prices to help maintain the quality and value of our Certification program. As a result, effective November 1, 2024, Microsoft is updating the retail prices for its Certification exams to reflect the current market conditions and the value of the Certifications. Our goal is to make the exam pricing simpler and more consistent across geographies while still offering a fair and affordable value proposition for our Certification candidates.
What are the new prices?
The new retail prices for Certification exams vary depending on the country or region where you take the exam. For most areas, there will be no change in the price. For some areas, the price will decrease to make the exams more affordable. In a few areas, the price will increase to align with global and regional standards. To find the updated price of the exams in your area, check out the full list of new prices for Microsoft Certifications by country or region.
How does this news affect you?
If you’re planning to take a Microsoft Certification exam, you can register for and take the exam at the current price until October 31, 2024. If you register to take the exam on or after November 1, 2024, you’ll pay the updated price. Remember, in many countries and regions, the retail price is not changing and might even be decreasing. For more information on how to register and pay for your exam, go to the Microsoft Certification exam policies and FAQs.
Microsoft Certification exams are more than just a test of your knowledge. They demonstrate your commitment, passion, and excellence in the IT industry. Earning a Certification is an investment in your professional life that can pay off in many ways, helping you build your skills and enhance your career. A Certification can boost your career prospects, improve your professional credibility, and unlock new opportunities for growth and success. Invest in your future and earn a certification today!
This article is contributed. See the original author and article here.
Viva Connections is the gateway for the employee experience and provides an extensible platform through the dashboard, where employees can see a targeted list of actionable cards that can connect to Microsoft Teams apps, Viva apps and services, partner apps, and custom solutions using the SharePoint Framework (SPFx) framework, internal links, and external links.
A Viva Connections dashboard showing some examples of third party cards.
This blog will explore a few of our diverse third-party card integrations available from can extend the capabilities of Viva Connections, allowing organizations to incorporate third party external tools, services, and data directly into their flow of work and ensure business critical investments that they have made in other services can be added directly into employee dashboards. There are countless ways to customize or build your own dashboard cards to meet the needs of employees at virtually any organization, but this blog will highlight a few pre-packaged cards from Microsoft partners that can easily be added to your app.
With the ServiceNow card, enable employees to get support, find answers, and act on tasks across HR, IT, and other departments. Once deployed, the card offers a quick view of their task list by selecting View My Tasks. The ServiceNow Adaptive Card extension also provides a quick entry point into the app by simply selecting Visit Employee Center.
With the UKG card employees can view their respective pay information and review their work schedules, shifts, and PTO, to see a clearer picture of upcoming priorities.
Achievers for Viva Connections extends the Achievers Employee Experience platform into employees’ daily workflows. Members can enjoy some of their favorite activities found on their Achievers program: view upcoming celebrations, recognitions received, the latest trending recognitions, and perform quick actions, all on one dashboard within Viva Connections.
The Qualtrics card brings experience management into Viva Connections seamlessly. It enables quick access to surveys and feedback tools, allowing organizations to gather valuable insights and act on employee, customer, and product experiences right from the dashboard. The Qualtrics card can link directly to surveys and let employees know when feedback is due, eliminating common barriers to organization-wide feedback.
With the Workday card, Viva Connections brings Workday data and actions to employees’ fingertips right in the dashboard. With this integration, users can access Workday tasks such as inbox items, time off balances, and more, simplifying HR processes and saving employees time on administrative tasks.
Features:
Customizable Workday® Web part in SharePoint & Adaptive Card extension for Viva Connections dashboard
Seamless Microsoft 365 integration: Get instant access to your Workday® data right within SharePoint using our Web part integration.
Developer-friendly: Easily customize the integration to fit your organization’s unique needs.
Streamlined workflows: Enjoy a seamless connection between Workday® and your Microsoft 365 apps for smooth data sharing and collaboration.
The Zendesk card for Viva Connections allows users to access and manage their Zendesk tickets directly, facilitating a more efficient customer support workflow.
Features:
Display your Zendesk data right within SharePoint with a custom web part
Enjoy a seamless experience within your Microsoft 365 environment
Redefine productivity by viewing and creating tickets from a single place
This seamless connection allows for the direct embedding of Asana tasks into your Viva Connections dashboard, creating a unified workspace where you can manage tasks without switching between applications.
Features:
Integrate Asana tasks directly into SharePoint, providing a centralized view of your projects
Utilize advanced search capabilities within Asana’s data to generate dynamic views for your SharePoint web part
Ensure a cohesive workflow across the Microsoft 365 suite, enhancing productivity and collaboration
Turn Viva Connections into a project management superhub by adding Asana cards
Many of the third-party cards highlighted in this blog are available through the Microsoft partner Adenin. Check out more about their Viva Connections cards in our recent partner showcase blog.
How to access and install third-party cards
There are a few simple steps to . Anyone can look up the available applications but only IT administrators can install them.
All users can find applications via Microsoft AppSource or the SharePoint store. Installation requires administration permissions in SharePoint.
Select “Get it Now” to request the application is added to the App Catalogue site in your SharePoint environment.
Work with the IT Admin to Deploy the app and add it to your Viva Connections dashboard.
Once Viva Connections is deployed for the organization, all employee users can access the app on their Viva Connections .
With dozens of third-party partner apps and M365 Viva apps to choose from, the opportunities for customization and enhanced productivity are vast. To start leveraging these powerful integrations, visit the SharePoint store and Microsoft AppSource today.
To learn more about the extensibility capabilities within the Viva Connections dashboard. View this course on Microsoft Learn.
This article is contributed. See the original author and article here.
If you work in smartcard federated authentication environments, here’s a much-anticipated security feature for you. Starting with the September 10, 2024 Windows security update, you can use strong name-based mapping on Windows Server 2019 and newer. This feature helps you with the hardening changes for certificate-based authentication on Windows domain controllers.
What are weak and strong mappings in Active Directory?
All certificate names must be correctly mapped onto the intended user account in Active Directory (AD). If there’s a likelihood that they aren’t, we call these mappings weak. Weak mappings give rise to security vulnerabilities and demand hardening measures such as Certificate-based authentication changes on Windows domain controllers.
Following up on our May 2022 round of updates to address these vulnerabilities, we’re introducing a new feature called strong name-based mapping. You can now distinguish between “strong” and “weak” mappings within existing Alternative Security Identities (AltSecIDs) based on likelihood. With the new feature, you can allow some weak name-based mappings to be treated as strong name-based mappings. You just need to properly configure both the public key infrastructure (PKI) and the AD deployment.
Key features and benefits of strong name-based mapping
Strong name-based mapping has two main benefits:
Compliance with strong certificate mapping enforcement. Strong name-based mapping allows certain weak certificate mappings, such as Issuer/Subject AltSecID and User Principal Names (UPN) mappings, to be treated as strong mappings. This type of strong mapping is compatible with the enforcement mode of certificate-based authentication changes on Windows domain controllers.
Compatibility with government PKI deployments. Strong name-based mappings work by asking PKI deployments to attest certain security guarantees of certificates via object identifiers (OIDs) stamped on the certificate. It’s a common practice among government PKI and AD deployments.
Security requirements for PKI deployments for strong name-based mapping
Warning
Unless you have a strong need for this type of deployment AND have a deep knowledge of how PKI deployments and AD authentication interact together, we DO NOT recommend deploying strong name-based mapping. We instead recommend that you following the guidance in KB5014754: Certificate-based authentication changes on Windows domain controllers.
Fundamentally, strong name-based mapping deployment is your promise to Microsoft that your PKI is not susceptible to the attacks addressed by May 2022 and later updates. Namely, you take responsibility for the vulnerabilities that can arise from any unintentional mapping of the names in a certificate to multiple AD accounts.
To prevent unintentional and unsafe mappings, we recommend that you take steps to strengthen your PKI and AD deployments. Some of these steps include:
Names used in either the Subject Name and/or the Subject Alternative Name of certificates MUST NOT contain names that are queried and/or built from AD.
Names used in either the Subject Name and/or the Subject Alternative Name of certificates MUST be both immutable and globally unique to the entire PKI deployment.
AD and PKI administrators must ensure that certificate issuance for logons is not automatic. Instead, ensure that strong manual checks are in place to prevent a certificate with an incorrect or clashing name from being issued.
Failing to secure your PKI and AD deployments can degrade the security of your environment.
If your PKI meets or exceeds these security requirements, you MUST add an OID in the Issuance Policy of the certificate to denote this compliance. This OID (or multiple OIDs) will be used further below in the strong name-based mapping configuration.
Setup instructions
To enable strong name-based mapping on Windows Server 2019 and later, you need to take the following steps:
Enable the Group Policy (GPO) Setting on the Domain Controllers: Computer Configuration > Administrative Template > System > KDC > “Allow name-based strong mappings for certificates”.
Configure the GPO with the necessary tuples (more details below).
This configuration relies on adding tuples to the GPO when strong name-based mapping is enabled. These tuples tell the Domain Controller which certificates meet the above security requirements by specifying both the Issuer certificate authority (CA) thumbprint and the OID(s) that denote that the PKI deployment is secured against the May 2022 vulnerabilities. Furthermore, the tuples also configure which “weak” name-based mappings can be upgraded to “strong” name-based mappings.
The tuple is in the following format: ;;
Issuer CA Certificate Thumbprint: This is the certificate thumbprint of the Issuing CA. There can only be one Issuer CA Thumbprint in this field. If multiple Issuer CA Thumbprints are placed, it can prevent proper processing of the GPO policy.
OID(s): This is a comma-separated list of OIDs that the PKI deployment has stamped on the certificate to attest that the security requirements against name collisions have been met. There can be multiple OIDs denoted in this field.
IssuerSubject/UpnSuffix: This is a comma-separated list to denote what type of weak mapping should be treated as strong:
IssuerSubject: This string behaves as a tag to denote that the Issuer/SubjectName AltSecID can be upgraded from “weak” to “strong.” There can only be one IssuerSubject tag in this field.
UPNSuffix: This string denotes that certificate mappings can be upgraded form “weak” to “strong” wherever the UPN suffix of the SubjectName (that is, everything that comes after the @ symbol) matches the suffix in the tuple exactly. There can be multiple UPN suffixes in this field.
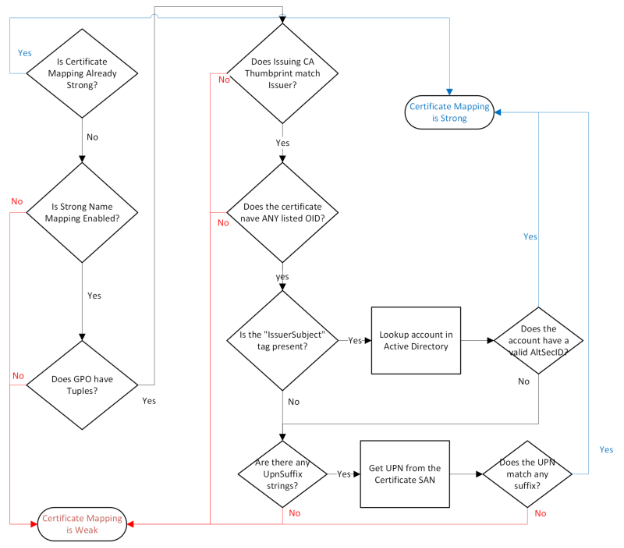
The logic of the tuple is the following. For certificates whose Issuer is X that has any of the OID(s) Y, upgrade any of the weak mappings C to “strong.” This logic is summarized in the diagram.
Flow chart illustrating the logic of strong name-based mapping configuration. The chart starts with a decision diamond asking if the certificate’s Issuer Certificate Thumbprint matches the specified thumbprint. If yes, it proceeds to check if the certificate has any of the specified OIDs. If both conditions are met, it allows a strong mapping for the certificate based on either Issuer/SubjectName AltSecID or UPNSuffix, depending on the configuration.
Two important configuration details are required for UPN Suffix mapping to work:
Certificates must have the UPN of the user in the SAN.
For certificates whose Issuer Certificate Thumbprint is fe40a3146d935dc248504d2dcd960d15c4542e6e, and
The certificate has the OID 2.16.840.1.101.3.2.1.3.45,
Allow a strong mapping if the certificate is mapped via Issuer/SubjectName AltSecID.
This tuple would allow a certificate logon which passes checks (1) and (2) issued to the user Bob, if the AD object for Bob has the Issuer/SubjectName AltSecID correctly configured for the certificate.
Policy tuple example 2
Use this policy tuple to allow a strong mapping via a specified UPNSuffix.
For certificates whose Issuer Certificate Thumbprint is fe40a3146d935dc248504d2dcd960d15c4542e6e, and
The certificate has the OID 2.16.840.1.101.3.2.1.3.45,
Allow a strong mapping if the certificate is mapped via UPNSuffix, which should be “corp.contoso.com.”
This tuple would allow a certificate logon which passes checks (1) and (2) issued to the user Bob, if the AD object for Bob has the Issuer/SubjectName AltSecID correctly configured for the certificate.
Policy tuple example 3
Use this policy tuple to allow a strong mapping via any of the approved specifications.
For certificates whose Issuer Certificate Thumbprint is fe40a3146d935dc248504d2dcd960d15c4542e6e, and
The certificate has ANY of the following OIDs:
2.16.840.1.101.3.2.1.3.45
2.16.840.1.101.3.2.1.3.44
Allow a strong name-based mapping if the certificate is mapped via either of the following:
The user account in AD has a valid Issuer/SubjectName AltSecID mapping
UPNSuffix, where the suffix is “corp.contoso.com”
UPNSuffix, where the suffix is “my.corp.contoso.com”
Event Log changes
Two Event Log updates are here to help you as an AD administrator better troubleshoot strong name-based mapping scenarios. These are available to you with the September 10, 2024 and later updates.
Updates to current event logs
The current event logs now include policy OIDs found on the certificate used for authentication. This modifies the Key Distribution Center (KDC) events introduced by the May 10, 2022 and later updates.
New event logs
Additionally, a new event is available to log when the strong name-based mapping GPO encounters an issue processing the policy tuples. Track these events through Event ID 311.
The Key Distribution Center (KDC) encountered invalid certificate strong name match policy.
Faulting line:
Ready to improve Windows Server security?
We’re excited to bring this feature to your government scenario. Consider strong name-based mappings on Active Directory and PKI deployments in Windows Server 2019 or later if you meet the security requirements and recommendations. If you have any questions or need assistance, our support team is here to help.
This article is contributed. See the original author and article here.
The new semester is just beginning, and over the past few months, we’ve enhanced Copilot with exciting new features to support your quiz creation. With the capabilities like generating detailed answer explanations for each question, rewriting questions, and smart suggestions for fine tuning the quiz. Copilot is now more powerful than ever. Let’s explore how these updates can help you create quizzes more effectively and efficiently this semester.
Please note that a Copilot for Microsoft 365 license is required to access the following features.
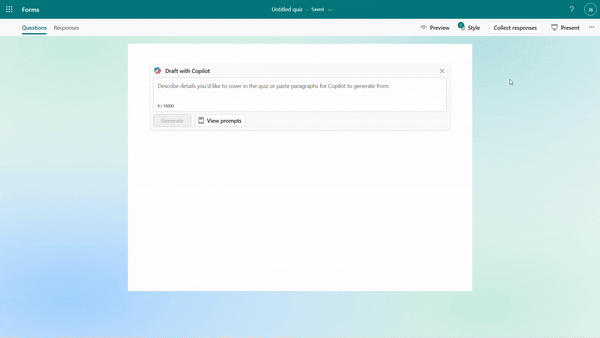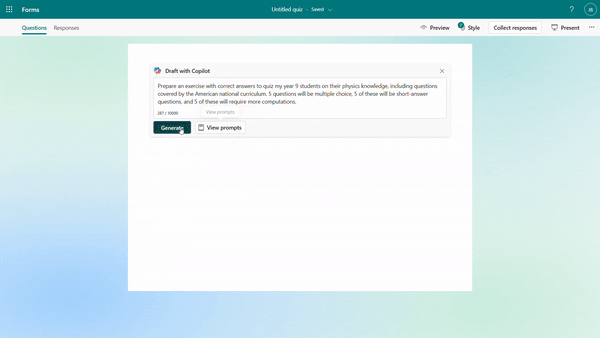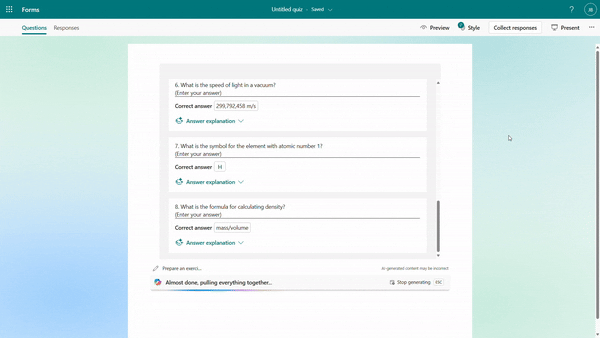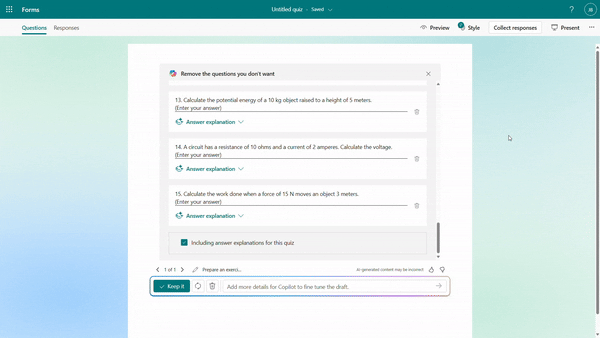
Generate quiz draft based on prompt/pasted content
You can specify your intentions, such as the quiz subject, audience, types of questions, and more to generate a quiz. Besides, Copilot can also generate a quiz from pasted content, such as a paragraph in textbook. For example, as a middle school teacher, you could instruct Copilot to create a physics quiz for 9th grade students or simply copy and paste content from a textbook to generate the quiz.
Generate quiz draft based on prompt
Quiz draft with answer explanations
After the quiz draft is generated, if you select “Including answer explanations,” each question will come with detailed explanations to clarify the reasoning behind the correct answers. You can review the solutions for each question and keep the draft to use. As shown below, when we are generating a math quiz for grade 9 students, Copilot shows us the step-by-step solutions to calculate the correct answer.
Step-by-step answer explanation
Further instructions to refine the draft
You have the flexibility to add/remove questions and refine the draft further by providing additional details to Copilot. For instance, if you forgot to include trigonometric questions in a math quiz, you could keep asking to add two questions on that topic.
Further instructions to refine the draft
Rewrite questions and answer explanations
Once you keep the draft to use, if you need to do further modifications on questions, options or the answer explanation, you can easily rewrite it with Copilot’s assistance. For example, you can make the question easier or add more details to the answer explanation for better clarity. You can also manually customize the answer explanations as needed.
Rewrite answer explanations
Generate answer explanation for newly created questions
After adjusting the generated questions, if you still need to add new ones, Copilot can help by generating answer explanations based on the correct answers you mark, saving you time on manual input.
Generate answer explanation for newly created questions
Copilot smart suggestions Before sending out the quiz, Copilot will offer suggestions to enhance its quality. You can add a fun theme to boost students’ motivation and enthusiasm, adjust settings such as time duration and practice mode, and choose appropriate distribution channels like sharing via URL or presenting live. With just one click, you can apply these suggestions to create a more engaging and effective quiz.
Copilot smart suggestions
Immediate results and answer explanation for responders
When respondents submit the quiz, they can view the results immediately and review the answer explanations to understand which areas they already mastered or where they could improve.
Check result with answer explanations after submitting





































Recent Comments