by Scott Muniz | Sep 3, 2020 | Uncategorized
This article is contributed. See the original author and article here.
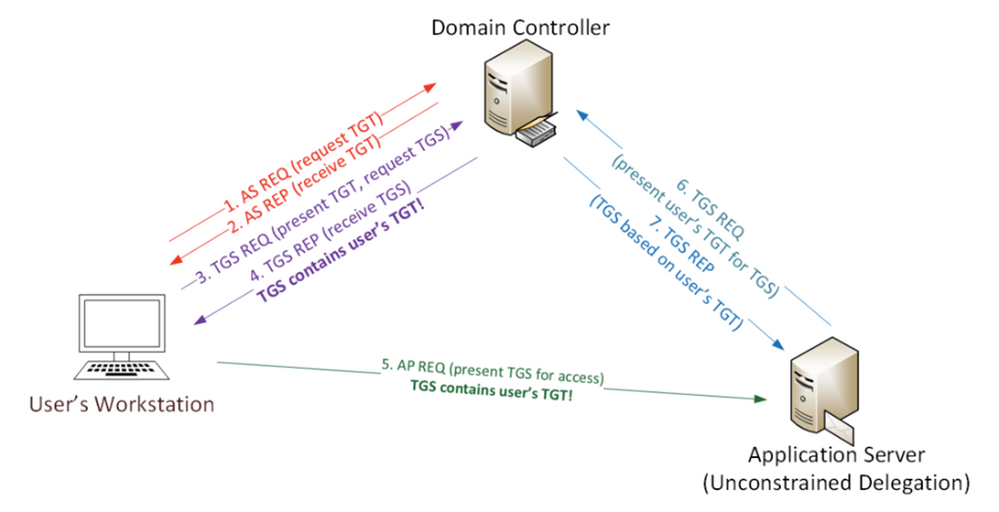
Imagine the following scenario, after a successful phishing campaign, an attacker finds themselves with an active shell on one of your non-sensitive employee’s devices. Using Living-off-the-Land (LotL) tactics (employing built in tools and commands), the attacker starts identifying their next targets and configuration weaknesses to leverage to comprise them. One such vulnerability might be the infamous print spooler bug.
The print spooler bug…
As published on the security conference DerbyCon at (2018), the print spooler bug is a way to gain elevated credentials (a sensitive computer account Kerberos ticket in this case) by exploiting two distinct configurations.
- A privileged device with the “print spooler” service running.
- A victim device configured for Unconstrained Kerberos delegation.
Using these two configurations in tandem, an attacker can “request” the sensitive device Kerberos ticket using the print spooler service through the victim’s device; and because unconstrained Kerberos delegation is enabled, that request will contain the highly sought-after Kerberos authentication ticket (TGT) that allows the attacker to impersonate the domain controller computer account – pretty bad, right?

*Image from https://adsecurity.org/?p=4056
What can you do?
As part of Azure ATP, we introduced the Identity Security Posture assessment that automatically looks for these kinds of risky configurations in your on-premises environment. This assessment and the recommendation are now integrated in Microsoft Secure Score, makes creating a mitigation plan for these recommended actions easier than ever. To view the recommendations you can use the following steps:
- Go to the Microsoft Secure Score portal.
- Use filters to show the relevant product or tags.
- Locate the relevant improvement actions for mitigating the print spooler bug, create an action plan using the built–in options or click “Manage” to find out which entities have risky configurations and what actions are needed to re-configure them to remediate the issue.

Once mitigated, Microsoft Secure Score will reflect the actions taken by increasing your score and mark these improvement actions as “Completed”.
Now, let’s consider another scenario.
After mitigating the print spooler bug , you discover another improvement action called “Stop clear text credential exposure”. After clicking the “Manage” button to access the assessment to view additional details, you discover that a sensitive entity and an accompanying device are authenticating over LDAP simple bind. To make matters even worse, the exposed user is also sensitive (belonging to the Domain admin group)

You then realize that if an attacker can get onto your network, they can “sniff” the transmitted credentials that are in clear text and gain elevated credentials.
To further investigate this case, you will need additional details regarding this type of unsecure communication such as:
- What processes are causing this behavior?
- Are any of them part of a critical application?
- What should I do next?
The hunt is on…
To answer these questions, let’s utilize one of MTP’s cool features called Advanced hunting which is now also enriched with Azure ATP activities alongside other security products such as Microsoft Defender ATP, Cloud App Security and Azure AD, and data from Office 365.
We’ll start by going to the Advanced hunting page in the new M365 security portal and from there, we now have access to all the different types of hunting data available for us, including two main tables relevant for this task:
- IdentityLogonEvents – all logon events generated by Azure ATP including the LDAP Cleartext type
- DeviceNetworkEvents – All networking events generated by Microsoft Defender ATP including LDAP queries generated toward the domain controllers using port 389.
To get started, we can write a query, joining detected logon sessions and network events from both these tables, resulting in a consolidated result that includes the all the unsecure logon activities and their initiating process names.

Using the query result, we can construct a cohesive story:
“On Aug 05, Testuser2 used the LDP.exe executable to generate an unsecure authentication using LDAP Simple Bind from Client5.”
We now have the relevant details to create a full remediation plan for this activity, such as simply blocking LDP.exe or configuring the application to require a more secure authentication while blocking insecure authentications at the domain level.
Conclusion
And there you have it! Using Azure ATP’s Identity Security Posture assessment with Microsoft Secure Score and Advanced hunting, we can build a simple mitigation plan for our organization’s security weak spots, making it that much harder for the bad guy the get in
For more information about Identity Security Posture assessments and MTP, see
* Learn more about Identity security posture assessments.
* Learn more about Microsoft Secure Score
* Azure ATP activities in advanced hunting
Or Tsemah, Senior Product Manager, Azure ATP.
by Scott Muniz | Sep 3, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Azure Data Factory orchestration allows conditional logic and enables user to take different based upon outcomes of a previous activity. In total we allows four conditional paths: Upon Success (default pass), Upon Failure, Upon Completion, and Upon Skip. Using different paths allow users to build robust pipelines and incorporates error handling in their ETL/ELT logic.

Here are two common error handling pattern we see customers use:
- TRY-CATCH block. Define the business logic, and only defines Upon Failure path to catch any error from previous activities

- DO-IF-ELSE block. Define the business logic, and depends on the outcome of the activity, enacts either Upon Success path or Upon Failure path

Both are valid ways to incorporate error handling into the pipeline. However, upon pipeline execution, they may show different outcomes. Approach #1, TRY-CATCH, shows pipeline succeeds if Upon Failure path clears, where as approach #2, DO-IF-ELSE show pipeline failed if Upon Failure path is enacted.
Technical reasons for the difference is that, Azure Data Factory defines pipeline success and failures as follows:
- Evaluate outcome for all leaves activities. If a leaf activity was skipped, we evaluate its parent activity instead
- Pipeline result is success if and only if all leaves succeed
Applying the logic to previous examples.
- In approach #1 TRY-CATCH block:
- when previous activity succeeds: the node activity, Upon Failure, is skipped and its parent node succeeds, so overall pipeline succeeds
- when previous activity fails: the node activity, Upon Failure, enacted and overall pipeline succeeds if Upon Failure path succeeds
- In approach #2 DO-IF-ELSE block:
- when previous activity succeeds: one node activity, Upon Success, succeeded, and the other node activity, Upon Failure, is skipped and its parent node succeeds; so overall pipeline succeeds
- when previous activity fails: one node activity, Upon Success, is skipped and its parent node failed; so overall pipeline failed
Here is a table summarizing the difference
| Approach |
Error Handling Defines |
When Activity Succeeds |
When Activity Fails |
| TRY-CATCH |
Only Upon Failure path |
Pipeline shows Success |
Pipeline shows Success |
| DO-IF-ELSE |
Upon Failure and Upon Success paths |
Pipeline shows Success |
Pipeline shows Failure |
by Scott Muniz | Sep 2, 2020 | Uncategorized
This article is contributed. See the original author and article here.
Pre-requirements:
Before we start, please read these document about Duplicate Detection, Partitioned queues and topics and Message Sessions
From the above Pre-requirements, we learn the followings
- Enabling Duplicate detection helps to ensure that a duplicate message, which has the same message Id cannot be sent into a messaging entity during a specified time.
- Service Bus Partitions enable queues and topics or message entities to be partitioned across multiple message brokers and messaging stores. Enable partitioning the overall throughput will separate to different partition. Partition key can be used in some scenarios, such as sessions or transactions, require messages to be stored in a specific partition.
- Microsoft Service Bus Session enable joint and ordered handling of unbounded sequences of messages. There are two patterns of it , first out and request-response pattern. Any sender can create a session when submitting messages into a topic or queue by setting the SessionId property to some application-defined identifier that is unique to the session.
So, from these above knowledges, we know that Azure Service Bus Queue and Topic/Subscription can enable for Duplicate Detection, Partitions and Sessions. But what’s the relationship between them?
From the meaning of Duplication detection, we know that there is a MessageId of each message. Definition of MessageId is shown below
“If the queue or topic has the RequiresDuplicateDetection property set to true and the SessionId or PartitionKey properties are not set, then the MessageId property value serves as the partition key”
This means the duplicate detection only can work when SessionID or PartitionKey are not be set. Is that a correct statement? Let’s do a test!
Test Entities:
Queues:
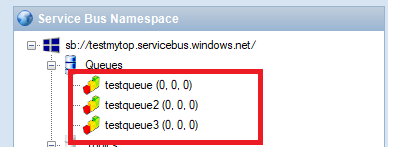
There are three queue I used, testqueue, testqueue2, testqueue3. At first time all of them have 0 messages.

- testqueue: Enable Batched Operation, Requires Duplicate Detection. And set duplicate detection for 10 mins.

- testqueue2: Enable Batched Operation, Requires Duplicate Detection, Requires Session

- testqueue3: Enable Batched Operation, Requires Duplicate Detection, Requires Session, Enable Partition

My Program:
Here is the code. The different in this program used in each time, just the BrokeredMessage SessionID and PartitionKey that in red color.
The Session ID here set with a random value. From the above document, when enable both Partition key and Session ID, the value of them need to be same. Otherwise Service Bus returns an invalid operation exception.
class Program
{
static string connectionString = [ConnectionString];
static string queueName = “testqueue3”;// testqueue,testqueue2
static void Main(string[] args)
{
MainAsync();
}
static void MainAsync()
{
QueueClient sendClient = QueueClient.CreateFromConnectionString(connectionString, queueName);
//create a sender on the queue
var session = Guid.NewGuid().ToString();
var partitionKey = session;
sendClient.SendBatch(Enumerable.Range(0, 10).Select(n =>
{
Console.WriteLine(“test my message n{0}”, session);
BrokeredMessage test = new BrokeredMessage(“Hello World!”) { SessionId = session, , PartitionKey = session, MessageId = “deadbeef-dead-beef-dead-beef” + n };
return test;
}
));
}
}
Test Round 1:
To find the message, I sent 10 message each time first.
- testqueue (Enable Batched Operation, Requires Duplicate Detection): send 10 messages first, then immediately send another same 10 messages, it still displays 10 messages.

- testqueue2(Enable Batched Operation, Requires Duplicate Detection, Requires Session): send 10 messages first, and send another same 10 messages, here also display 10 messages.

- testqueue3(Enable Batched Operation, Requires Duplicate Detection, Requires Session, Enable Partition): Add new message twice the message count turn to 20.

You can see in the list there are message with duplicate MessageId.

Then I checked for same MessageId “deadbeef-dead-beef-dead-beef0” , and I found they have different Partition Keys.


Here are these three queues result in this test.

The above test about messages sent in duplicate detection duration. How about we wait for 10 mins to check after the duplicate detection time?
Test Round 2
After 10 mins, I sent 1000 messages again twice. The result shows, testqueue and testqueue2 have 1000 included the 10 messages sent before. For testqueue3, there are 2020 messages.

Test Result Summary
- From the first round test result, it indicates that messages with same MessageId can be detected as duplication in a non-partitioned entity within specified duplicate detection duration (10 mins).
- However with partitioned entity, duplicate messages which has same MessageId may not be detected as duplication due to they can end up in a different partition. In conclusion, messages can only be detected as duplication within the specified duplicate detection duration when they are landed in the same partition, i.e. same partition key
- For the second test with 1000 message were sent twice, it indicates that the duplicate duration detect only works for the specified duration. After the duplicate detection period, the Messages with same MessageId can be sent to the same Service Bus messaging entity.
by Scott Muniz | Sep 2, 2020 | Azure, Microsoft, Technology, Uncategorized
This article is contributed. See the original author and article here.
One of the challenges of large scale data analysis is being able to get the value from data with least effort. Doing that often involves multiple stages: provisioning infrastructure, accessing or moving data, transforming or filtering data, analyzing and learning from data, automating the data pipelines, connecting with other services that provide input or consume the output data, and more. There are quite a few tools available to solve these questions, but it’s usually difficult to have them all in one place and easily connected.
If this article was helpful or interesting to you, follow @lenadroid on Twitter.
Introduction
This is the first article in this series, which will cover what Azure Synapse is and how to start using it with Azure CLI. Make sure your Azure CLI is installed and up-to-date, and add a synapse extension if necessary:
$ az extension add --name synapse
What is Azure Synapse?
In Azure, we have Synapse Analytics service, which aims to provide managed support for distributed data analysis workloads with less friction. If you’re coming from GCP or AWS background, Azure Synapse alternatives in other clouds are products like BigQuery or Redshift. Azure Synapse is currently in public preview.
Serverless and provisioned capacity
In the world of large-scale data processing and analytics, things like autoscale clusters and pay-for-what-you-use has become a must-have. In Azure Synapse, you can choose between serverless and provisioned capacity, depending on whether you need to be flexible and adjust to bursts, or have a predictable resource load.
Native Apache Spark support
Apache Spark has demonstrated its power in data processing for both batch and real-time streaming models. It offers a great Python and Scala/Java support for data operations at large scale. Azure Synapse provides built-in support for data analytics using Apache Spark. It’s possible to create an Apache Spark pool, upload Spark jobs, or create Spark notebooks for experimenting with the data.
SQL support
In addition to Apache Spark support, Azure Synapse has excellent support for data analytics with SQL.
Other features
Azure Synapse provides smooth integration with Azure Machine Learning and Spark ML. It enables convenient data ingestion and export using Azure Data Factory, which connects with many Azure and independent data input and output sources. Data can be effectively visualized with PowerBI.
At Microsoft Build 2020, Satya Nadella announced Synapse Link functionality that will help get insights from real-time transactional data stored in operational databases (e.g. Cosmos DB) with a single click, without the need to manage data movement.
Get started with Azure Synapse Workspaces using Azure CLI
Prepare the necessary environment variables:
$ StorageAccountName='<come up with a name for your storage account>'
$ ResourceGroup='<come up with a name for your resource group>'
$ Region='<come up with a name of the region, e.g. eastus>'
$ FileShareName='<come up with a name of the storage file share>'
$ SynapseWorkspaceName='<come up with a name for Synapse Workspace>'
$ SqlUser='<come up with a username>'
$ SqlPassword='<come up with a secure password>'
Create a resource group as a container for your resources:
$ az group create --name $ResourceGroup --location $Region
Create a Data Lake storage account:
$ az storage account create
--name $StorageAccountName
--resource-group $ResourceGroup
--location $Region
--sku Standard_GRS
--kind StorageV2
The output of this command will be similar to:
{- Finished ..
"accessTier": "Hot",
"creationTime": "2020-05-19T01:32:42.434045+00:00",
"customDomain": null,
"enableAzureFilesAadIntegration": null,
"enableHttpsTrafficOnly": false,
"encryption": {
"keySource": "Microsoft.Storage",
"keyVaultProperties": null,
"services": {
"blob": {
"enabled": true,
"lastEnabledTime": "2020-05-19T01:32:42.496550+00:00"
},
"file": {
"enabled": true,
"lastEnabledTime": "2020-05-19T01:32:42.496550+00:00"
},
"queue": null,
"table": null
}
},
"failoverInProgress": null,
"geoReplicationStats": null,
"id": "/subscriptions/<subscription-id>/resourceGroups/Synapse-test/providers/Microsoft.Storage/storageAccounts/<storage-account-name>",
"identity": null,
"isHnsEnabled": null,
"kind": "StorageV2",
"lastGeoFailoverTime": null,
"location": "eastus",
"name": "<storage-account-name>",
"networkRuleSet": {
"bypass": "AzureServices",
"defaultAction": "Allow",
"ipRules": [],
"virtualNetworkRules": []
},
"primaryEndpoints": {
"blob": "https://<storage-account-name>.blob.core.windows.net/",
"dfs": "https://<storage-account-name>.dfs.core.windows.net/",
"file": "https://<storage-account-name>.file.core.windows.net/",
"queue": "https://<storage-account-name>.queue.core.windows.net/",
"table": "https://<storage-account-name>.table.core.windows.net/",
"web": "https://<storage-account-name>.z13.web.core.windows.net/"
},
"primaryLocation": "eastus",
"provisioningState": "Succeeded",
"resourceGroup": "<resource-group-name>",
"secondaryEndpoints": null,
"secondaryLocation": "westus",
"sku": {
"capabilities": null,
"kind": null,
"locations": null,
"name": "Standard_GRS",
"resourceType": null,
"restrictions": null,
"tier": "Standard"
},
"statusOfPrimary": "available",
"statusOfSecondary": "available",
"tags": {},
"type": "Microsoft.Storage/storageAccounts"
}
Retrieve the storage account key:
$ StorageAccountKey=$(az storage account keys list
--account-name $StorageAccountName
| jq -r '.[0] | .value')
Retrieve Storage Endpoint URL:
$ StorageEndpointUrl=$(az storage account show
--name $StorageAccountName
--resource-group $ResourceGroup
| jq -r '.primaryEndpoints | .dfs')
You can always check what your storage account key and endpoint are by looking at them, if you’d like:
$ echo "Storage Account Key: $StorageAccountKey"
$ echo "Storage Endpoint URL: $StorageEndpointUrl"
Create a fileshare:
$ az storage share create
--account-name $StorageAccountName
--account-key $StorageAccountKey
--name $FileShareName
Create a Synapse Workspace:
$ az synapse workspace create
--name $SynapseWorkspaceName
--resource-group $ResourceGroup
--storage-account $StorageAccountName
--file-system $FileShareName
--sql-admin-login-user $SqlUser
--sql-admin-login-password $SqlPassword
--location $Region
The output of the command should show the successful creation:
{- Finished ..
"connectivityEndpoints": {
"dev": "https://<synapse-workspace-name>.dev.azuresynapse.net",
"sql": "<synapse-workspace-name>.sql.azuresynapse.net",
"sqlOnDemand": "<synapse-workspace-name>-ondemand.sql.azuresynapse.net",
"web": "https://web.azuresynapse.net?workspace=%2fsubscriptions%<subscription-id>%2fresourceGroups%2fS<resource-group-name>%2fproviders%2fMicrosoft.Synapse%2fworkspaces%<synapse-workspace-name>"
},
"defaultDataLakeStorage": {
"accountUrl": "https://<storage-account-name>.dfs.core.windows.net",
"filesystem": "<file-share-name>"
},
"id": "/subscriptions/<subscription-id>/resourceGroups/<resource-group-name>/providers/Microsoft.Synapse/workspaces/<synapse-workspace-name>",
"identity": {
"principalId": "<principal-id>",
"tenantId": "<tenant-id>",
"type": "SystemAssigned"
},
"location": "eastus",
"managedResourceGroupName": "<managed-tesource-group-id>",
"name": "<synapse-workspace-name>",
"provisioningState": "Succeeded",
"resourceGroup": "<resource-group-name>",
"sqlAdministratorLogin": "<admin-login>",
"sqlAdministratorLoginPassword": <admin-password>,
"tags": null,
"type": "Microsoft.Synapse/workspaces",
"virtualNetworkProfile": null
}
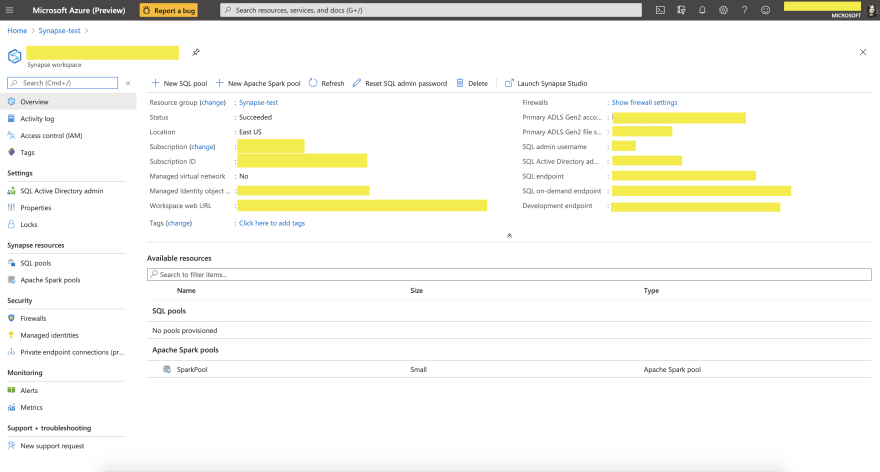
After you successfully created these resources, you should be able to go to Azure Portal, and navigate to the resource called $SynapseWorkspaceName within $ResourceGroup resource group. You should see a similar page:

What’s next?
You can now load data and experiment with it in Synapse Data Studio, create Spark or SQL pools and run analytics queries, connect to PowerBI and visualize your data, and many more.
Stay tuned for next articles to learn more! Thanks for reading!
If this article was interesting to you, follow @lenadroid on Twitter.

Recent Comments