This article is contributed. See the original author and article here.
Image with text “Challenge”
Register for the VS Code Day Skills Challenge! Whether you’re just starting or looking to change your career, this program is designed for you to get to know VS Code and GitHub Copilot in different career areas like Data Science, Artificial Intelligence, and much more! With easy-to-follow lessons, exercises, and live workshops, learn what’s new in VS Code. Register now and discover the world of opportunities offered by VS Code at: https://aka.ms/VSCodeDayChallenge!
VS Code Day is our annual event where you’ll learn how to elevate your development workflow with the latest and greatest features of VS Code. This year, we’re excited to delve into AI and you’ll hear from the VS Code team and other industry experts on topics like AI-powered programming with GitHub Copilot, building and deploying generative AI apps to the cloud, enhancing the C# development experience, and more!
Whether you’re just starting out or you’re an experienced developer, join us on April 24th, 2024 for a day focused on the editor that lets you code anything, cross-platform and free!
Image with text “Acknowledgements”
By completing the 11 modules in this challenge you will be able to earn a badge in your Microsoft Learn profile! Stay tuned for more information on social media and on this blog – we’ll share more about this #VSCodeDay’s events!
IMPORTANT!:Your badge will be added to your Microsoft Learn profile within 1 week of the challenge end date.
Image text “Frecuently Asked Questions”
When does this challenge start and end? It starts on April 24, 2024 and ends on May 17, 2024.
How much experience do I need? Just basic programming skills.
How much time should I dedicate to it per day? It is designed for you to learn according to your needs and available time, remember that you have to complete it by May 17.
Prerequisites: None.
Is there a cost to participate in this challenge? There is no cost
image with text “sessions and live-workshops”
Get ready to find out what’s new in VS Code with our livestream series! It will be full of tips, tricks, and practical exercises to help you with your personal and professional projects. Whether you’re just starting out or looking to improve your skills, this is a must-see event for anyone interested in programming.
To register for all these #VSCodeDay sessions, visit here: (aka.ms/VSCodeDay)! It starts on April 24 from 11 am to 6 pm (GMT-6)*.
Live session
Speaker(s)
Social Media
Keynote: View Source: What gets into VS Code and why
If you’ve used VS Code before, please let us know in the comments about your experience: your favorite extensions, your favorite sessions during the livestreams, and even if it’s the first time you’ve heard about VS Code!
We’d love to hear your favorite/funny stories from the times you’ve coded in VS Code!
Tag us on social media using the following hashtag: #VSCodeDayCSC
This article is contributed. See the original author and article here.
O Global AI Bootcamp é um evento gratuito e anual que é realizada em diferentes cidades espalhadas pelo mundo inteiro com o intuito de promover, ensinar e discutir sobre:
Inteligência Artificial
OpenAI
Azure OpenAI
LLM’s
LangChain
RAG
Chatbots
E, muito mais!
O evento é organizado pela comunidade Global AI Community e é realizado em parceria com diversas empresas e organizações locais. E, gostaria de trazer aqui uma grande novidade à toda Comunidade Técnica do Rio de Janeiro!
Em 2024, o Global AI Bootcamp será realizado no Rio de Janeiro! E, será um evento presencial e gratuito. Contará com:
Palestras
Workshops
Laboratórios
Debates
Ementa do Evento
Vamos agora falar um pouco sobre o que será abordado no evento:
Agenda
09:00 – Keynote – Global AI Bootcamp (Abertura)
09:05 – Main Talk –Glaucia Lemos: Como Fazer uma Aplicação com Copilot e IA Generativa?
O evento será realizado na Faculdade Ibmec da Barra da Tijuca, localizada na Avenida Armando Lombardi, 940 – Barra da Tijuca, Rio de Janeiro – RJ.
Então, vamos resumir as informações:
Data:19 de Abril de 2024
Horário:09:00 às 14:00
Local:Faculdade Ibmec da Barra da Tijuca
Endereço:Avenida Armando Lombardi, 940 – Barra da Tijuca, Rio de Janeiro – RJ
Inscrições
As inscrições para o evento já estão abertas e as vagas são limitadas. Então, clique na imagem abaixo e garanta já a sua vaga!
As inscrições pelo site oficial do evento é extremamente importante para àqueles que participarão. Pois se você decidir fazer um dos workshops que serão administrados, será gerado uma chave para fazer uso dos recursos da OpenAI de graça!
Material de Apoio para quem já se inscreveu!
Se você já se inscreveu no evento, acessem agora mesmo o material de apoio. Pois, será muito importante para ajudar a vocês a se prepararem para o evento:
A área de Inteligência Artificial é uma das áreas que mais estão em grande ascensão no mercado de tecnologia nos dias de hoje. E, eventos como o Global AI Bootcamp são essenciais para aprendermos e discutirmos sobre essas novas tecnologias e seus impactos em nossas vidas, seja pessoal e principalmente profissional!
Assim sendo, não percam a oportunidade de participar desse grande evento que será realizado no Rio de Janeiro em 2024. E, espero encontrar vocês por lá!
This article is contributed. See the original author and article here.
Imagen “reto”.
¡Regístrate al VS Code Day Skills Challenge!Ya sea que estes comenzando o buscando cambiar tu carrera, este programa está diseñado para que conozcas VS Code y GitHub Copilot en diferentes áreas profesionales como Ciencia de Datos, Inteligencia Artificial y Desarrollo Web. Con lecciones fáciles de seguir, ejercicios prácticos y talleres en vivo, aprende las novedades en VS Code. ¡Regístrate ahora y descubre el mundo de oportunidades que te ofrece VS Code en:https://aka.ms/VSCodeDayChallenge!
VS Code Day es nuestro evento anualen el cualaprenderás a mejorar tu proceso de programación con las novedades y grandes características de VS Code! Este año, estamos muy emocionados ya que tendremos sesiones enfocadas en la Inteligencia Artificial y escucharás al equipo de VS Code y a expertos de la industria hablar sobre temas como GitHub Copilot, la creación e implementación de aplicaciones de IA generativa en la nube, la mejora de la experiencia de programación en C# y ¡mucho más!
Si estás empezando en el mundo de programación o si eres un programador con experiencia, ¡acompáñanos este 24 de abril de 2024 para conocer más sobre este super editor de código gratuito que te permite programar cualquier cosa!
Imagen de “Reconocimientos”
Al completar los 11 módulos de este reto, podrás obtener un reconocimiento (badge) digital en tu perfil de Microsoft Learn por haber finalizado esta experiencia. ¡Mantente al tanto de más información en redes sociales y en este blog – te compartiremos más sobre los eventos de este #VSCodeDay!
¿Cuándo inicia y finaliza este reto?Inicia el 24 de abril 2024 y finaliza el 17 de mayo del 2024.
¿Cuánta experiencia necesito? Solo conocimientos básicos de programación.
¿Cuánto tiempo debo dedicarle al día? Está diseñado para que vayas aprendiendo conforme a tus necesidades y tiempo disponible, recuerda que tienes que completarlo hasta el 17 de mayo.
Prerrequisitos:Ninguno.
¿Tiene costo alguno?No tiene costo
Imagen de “Charlas y talleres en vivo”
¡Prepárate para conocer las novedades de VS Code con nuestra serie de charlas y talleres en vivo! Estarán llenas de consejos, trucos y ejercicios prácticos para ayudarles con sus proyectos personales y profesionales. Ya sea que estas comenzando o buscando mejorar tus habilidades, este es un evento imperdible para cualquier persona interesada en programación.
¡Para registrarte a todas estas charlas del #VSCodeDay ingresa a la siguiente página web (aka.ms/VSCodeDay)! Inicia el 24 de Abril desde las 11 am hasta las 6 pm (GMT-6)*.
*Horario Ciudad de México
Evento
Ponente
Redes Sociales
Keynote: View Source: What gets into VS Code and why
Si anteriormente has utilizado VS Code, por favor, cuéntanos en los comentarios tu experiencia: tus extensiones favoritas, que te han parecido las charlas del evento e incluso si es la primera vez que has escuchado sobre VS Code!
¡Nos fascinaría escuchar tus historias o anécdotas favoritas/divertidas de las veces que has programado en VS Code!
Etiquétanos en redes sociales usando el siguiente hashtag: #VSCodeDayCSC
This article is contributed. See the original author and article here.
At Microsoft, trust is the foundation of everything we do. As more organizations adopt Copilot in Dynamics 365 and Power Platform, we are committed to helping everyone use AI responsibly. We do this by ensuring our AI products deliver the highest levels of security, compliance, and privacy in accordance with our Responsible AI Standard—our framework for the safe deployment of AI technologies.
Take a moment to review the latest steps we are taking to help your organization securely deploy Copilot guided by our principles of safety, security, and trust.
Copilot architecture and responsible AI principles in action
Let’s start with an overview of how Copilot works, how it keeps your business data secure and adheres to privacy requirements, and how it uses generative AI responsibly.
First, Copilot receives a prompt from a user within Dynamics 365 or Power Platform. This prompt could be in the form of a question that the user types into a chat pane, or an action, such as selecting a button labeled “Create an email.”
Copilot processes the prompt using an approach called grounding, which might include retrieving data from Microsoft Dataverse, Microsoft Graph, or external sources. Grounding improves the relevance of the prompt, so the user gets responses that are more appropriate to their task. Interactions with Copilot are specific to each user. This means that Copilot can only access data that the current user has permissions to.
Copilot uses Azure OpenAI Service to access powerful generative AI models that understand natural language inputs and returns a response to the user in the appropriate form. For example, a response might be in the form of a chat message, an email, or a chart. Users should always review the response before taking any action.
How Copilot uses your proprietary business data
Responses are grounded in your business content and business data. Copilot has real-time access to both your content and context to generate answers that are precise, relevant, and anchored in your business data for accuracy and specificity. This real-time access goes through our Dataverse platform (which includes all Power Platform connectors), honoring the data loss prevention and other security policies put in place by your organization. We follow the pattern of Retrieval Augmentation Generation (RAG), which augments the capabilities of language models by adding dynamic grounding data to the prompt that we send to the model. Our system dynamically looks up the relevant data schema using our own embedding indexes and then uses the language models to help translate the user’s question into a query that we can run against the system of record.
We do not use your data to train language models. We believe that our customers’ data is their data in accordance with Microsoft’s data privacy policy. AI-powered language models are trained on a large but limited corpus of data—but prompts, responses, and data accessed through Microsoft Graph and Microsoft services are not used to train Copilot for Dynamics 365 or Power Platform capabilities for use by other customers. Furthermore, the models are not improved through your usage. This means that your data is accessible only by authorized users within your organization unless you explicitly consent to other access or use.
How Copilot protects business information and data
Enterprise-grade AI, powered by Azure OpenAI Service. Copilot is powered by the trusted and compliant Azure OpenAI Service, which provides robust, enterprise-grade security features. These features include content filtering to identify and block output of harmful content and protect against prompt injections (jailbreak attacks), which are user prompts that provoke the generative AI model into behaving in ways it was trained not to. Azure AI services are designed to enhance data governance and privacy and adhere to Microsoft’s strict data protection and privacy standards. Azure OpenAI also supports enterprise features like Azure Policy and AI-based security recommendations by Microsoft Defender for Cloud, meeting compliance requirements with customer-managed data encryption keys and robust governance features.
Built on Microsoft’s comprehensive approach to security, privacy, and compliance. Copilot is integrated into Microsoft Dynamics 365 and Power Platform. It automatically inherits all your company’s valuable security, compliance, and privacy policies and processes. Copilot is hosted within Microsoft Cloud Trust Boundary and adheres to comprehensive, industry-leading compliance, security, and privacy practices. Our handling of Copilot data mirrors our treatment of other customer data, giving you complete autonomy in deciding whether to retain data and determining the specific data elements you wish to keep.
Safeguarded by multiple forms of protection. Customer data is protected by several technologies and processes, including various forms of encryption. Service-side technologies encrypt organizational content at rest and in transit for robust security. Connections are safeguarded with Transport Layer Security (TLS), and data transfers between Dynamics 365, Power Platform, and Azure OpenAI occur over the Microsoft backbone network, ensuring both reliability and safety. Copilot uses industry-standard secure transport protocols when data moves over a network—between user devices and Microsoft datacenters or within the datacenters themselves.
Watch this presentation by James Oleinik for a closer look at how Copilot allows users to securely interact with business data within their context, helping to ensure data remains protected inside the Microsoft Cloud Trust Boundary. You’ll also learn about measures we take to ensure that Copilot is safe for your employees and your data, such as how Copilot isolates business data from the language model so as not to retrain the AI model.
Architected to protect tenant, group, and individual data. We know that data leakage is a concern for customers. Microsoft AI models are not trained on and don’t learn from your tenant data or your prompts unless your tenant admin has opted in to sharing data with us. Within your environment, you can control access through permissions that you set up. Authentication and authorization mechanisms segregate requests to the shared model among tenants. Copilot utilizes data that only you can access. Your data is not available to others.
Committed to building AI responsibly
As your organization explores Copilot for Dynamics 365 and Power Platform, we are committed to delivering the highest levels of security, privacy, compliance, and regulatory commitments, helping you transform into an AI-powered business with confidence.
This article is contributed. See the original author and article here.
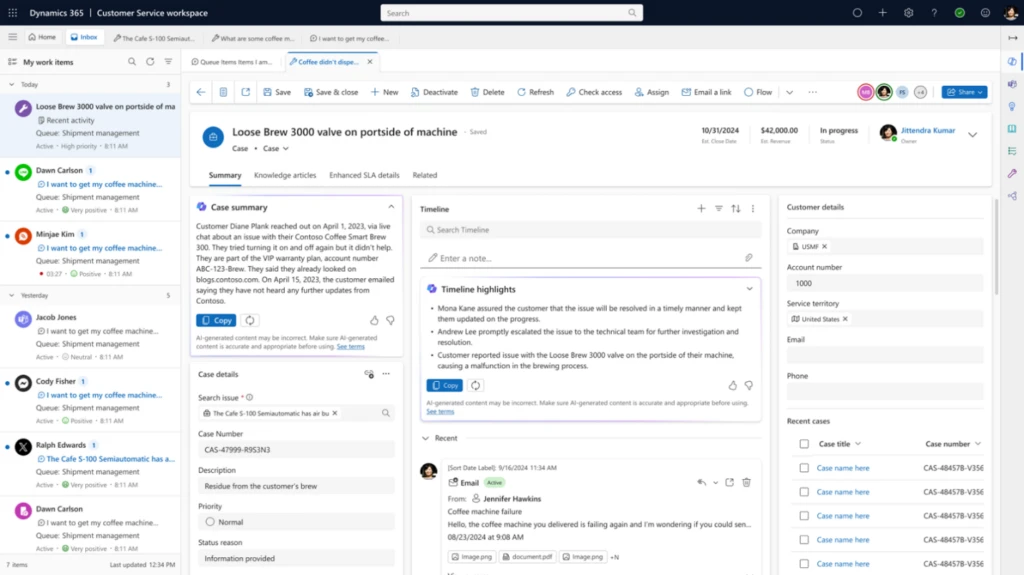
The timeline is a crucial tool for users to monitor customer engagements, track activities, and stay updated on record progress. With Generative AI, we’re introducing timeline highlights, enabling users to grasp activity details in milliseconds.
Streamlined timeline highlights revolutionize the way users interact with essential activities such as emails, notes, appointments, tasks, phone calls, and conversations. With a single click, agents gain access to summaries of key events, including records like cases, accounts, contacts, leads, opportunities, and customized entities.
Agents save time with timeline highlights
This new feature optimizes agent productivity, eliminating the need for excessive clicks and extra reading. Agents can efficiently absorb crucial information, enabling faster and more transparent interactions with customers. Users can expand the highlights section in the timeline by clicking on the chevron.
The highlights show relevant items in a clear and concise bulleted format, facilitating quick analysis and easy reference. The copy functionality empowers users to reuse content by pasting it into notes, with the flexibility to make modifications as needed.
In summary, our innovative approach to timelines, driven by generative AI technology, offers users a transformative experience. Consequently, agents can effortlessly track customer engagements and monitor progress with unparalleled speed and accuracy.
The timeline highlights feature is available within the apps like Dynamics 365 Customer Service, Dynamics 365 Sales, Dynamics 365 Marketing, Dynamics Field Service and custom model-driven Power Apps, providing a unified experience across Dynamics 365.
Timeline highlights are enabled by default. You can enable and disable timeline highlights at the app level and also at form level via the maker portal make.powerapps.com

.png") Image with text “Acknowledgements”
Image with text “Acknowledgements”.png") Image text “Frecuently Asked Questions”
Image text “Frecuently Asked Questions”.png") image with text “sessions and live-workshops”
image with text “sessions and live-workshops”.png") Image with text “Share your experience!”
Image with text “Share your experience!”


.png")
.png")
.png")
.png")
 ¡Nos fascinaría escuchar tus historias o anécdotas favoritas/divertidas de las veces que has programado en VS Code!
¡Nos fascinaría escuchar tus historias o anécdotas favoritas/divertidas de las veces que has programado en VS Code!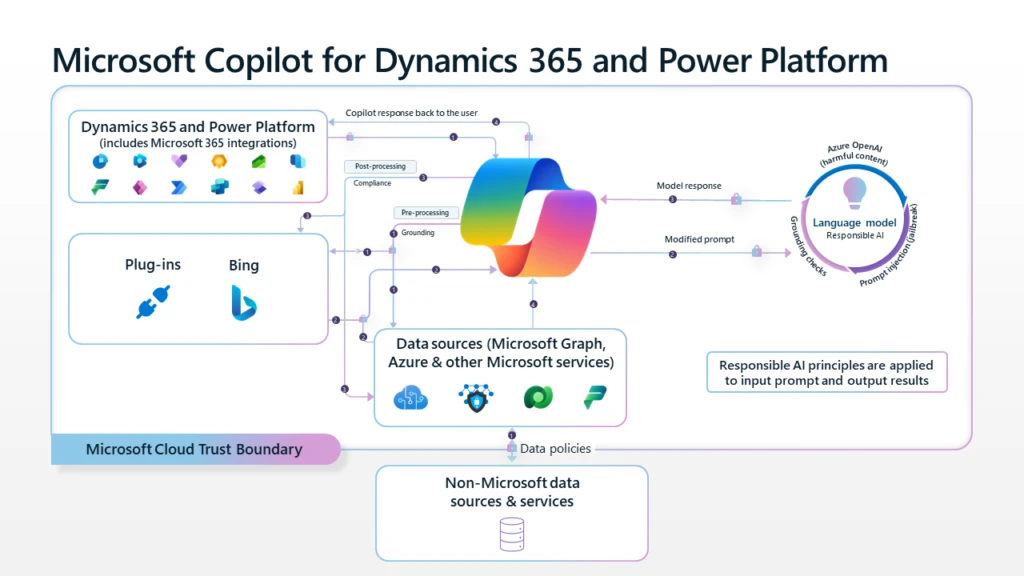


Recent Comments