by Contributed | Jan 5, 2022 | Technology
This article is contributed. See the original author and article here.
We are excited to announce the preview release of auto-failover groups for Azure SQL Hyperscale tier. This preview release includes support for forced and planned failover for Azure SQL Hyperscale databases that use active geo-replication and auto-failover groups. Some key benefits of auto-failover groups include:
- Simplified management of a group of geo-replicated databases including ability to failover the entire group of databases.
- Ability for application to maintain the same read/write and read-only endpoints after failover.
- Recovery during loss of an entire region through geo-failover which can be initiated manually or through an automatic failover policy.
- Readable online secondaries that can be used for read-only workloads by connecting with read-only listener endpoints which remain unchanged during geo-failovers.
Hyperscale service tier supports 100 TB of database size, rapid scale (out and up) and nearly instantaneous database backups, removing the limits traditionally seen in cloud databases.
How auto-failover groups work for Hyperscale
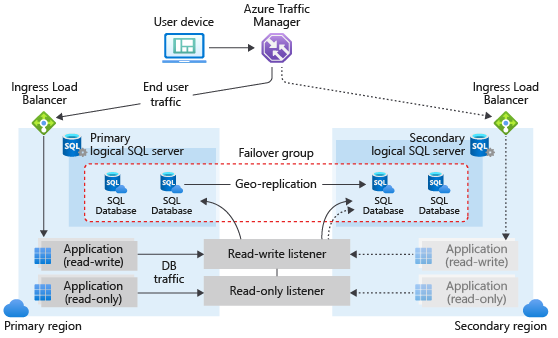
Auto-failover groups are created between servers in 2 regions. The groups can include all or some databases in the servers. If a Hyperscale database is selected to be part of the failover group, then this database will failover with the rest of the failover group unit. The following diagram illustrates a typical configuration of a geo-redundant cloud application using multiple databases and auto-failover group.
Available regions
Auto-failover groups for Hyperscale will be supported in all regions where Azure SQL Hyperscale is supported.
Quick start
a. Create an Auto-failover group using Portal.
- Failover groups can be configured at the server level. Select the name of the server under Server name to open the settings for the server.

- Select Failover groups under the Settings pane, and then select Add group to create a new failover group.

- On the Failover Group page, enter or select your desired values for your failover group.

- Add your Hyperscale database to the failover group then select Create.

b. Create an Auto-failover group using PowerShell.
c. Create an Auto-failover group using CLI.
d. Create an Auto-failover group using REST API.
Geo-failover examples
Example 1: Planned failover for an auto-failover group
a. Execute a failover of an auto-failover group in Portal.
1. Select your failover group.

2. Select Failover to initiate failover for your auto-failover group. Once failover is completed you should see that your primary and secondary servers have swapped roles.

b. Execute a failover of an auto-failover group using Switch-AzSqlDatabaseFailoverGroup in PowerShell.
c. Execute a failover of an auto-failover group using az sql failover-group set-primary in CLI.
d. Execute a failover of an auto-failover group using REST API.
Example 2: Forced failover with active geo-replication
a. Execute a failover using Portal.
1. Select the Replicas tab. In the list of geo replicas click the ellipsis for the secondary you would like to become the new primary. Then select Forced failover.

2. You should now see that the primary and secondary have swapped roles.
b. Execute a failover using Set-AzSqlDatabaseSecondary in PowerShell with the -AllowDataLoss parameter specified.
c. Execute a failover using az sql db replica set-primary in CLI with the –allow-data-loss parameter specified.
d. Execute a failover using REST API.
Learn more
https://docs.microsoft.com/azure/azure-sql/database/auto-failover-group-overview
https://aka.ms/activegeoreplication
https://docs.microsoft.com/en-us/azure/azure-sql/database/service-tier-hyperscale

by Contributed | Jan 4, 2022 | Technology
This article is contributed. See the original author and article here.
When your organization is faced with investigating a security incident, whether that’s something as simple as a phishing campaign or more complex like a determined human adversary, time is of the essence. Collecting and analyzing data are two critical things that need to be performed to quickly get an understanding of the initial scope and impact of the incident. There are several variables around both collecting and analyzing data that can affect the speed at which you might be able to respond. While the method or process of collecting data (or even the availability of relevant incident data) is unique to each organization, the analysis of that data is something that can be sped up to reduce the time it takes to make tactical and strategic decisions.
In this blog, we’ll show you how the Microsoft Detection and Response Team (DART) uses the Kusto Query Language (KQL) to quickly analyze data during incident response investigations.
Why KQL?
Kusto allows for various ingestion methods and various data formats. Data can be structured to best suit your use case in a table using data mappings, and when use cases arise that call for additional data (e.g., third party logs) you can import on the fly via Azure Data Explorer using One-Click Ingestion. In order to query the data, we use and recommend Azure Data Explorer.
Data Sources
When Microsoft DART is on the prowl for threat actors in customer environments, we leverage Microsoft Defender for Endpoint and Microsoft Defender for Identity as two primary data sources. Of course, we do not limit our scope to just Microsoft security products. Every organization has its own third-party logs that are vital to the investigation, which typically includes firewalls, VPNs, proxy logs, etc. We take all of this data and ingest it into a Kusto cluster and database to leverage KQL for fast and efficient analysis.
Analyzing data to scope the attack impact
The ultimate outcome of data analysis is to be able to make decisions based on what the data is telling us. Specifically with incident response investigations, data analysis plays a vital role in being able to scope the impact of the attack, identify new leads to hunt down, and provide insight into how to contain the threat. Leaders within the organization need the results of this analysis to quickly understand what they’re facing and to make decisions based on factual data. In the all-too-common cases of a ransomware attack, you may be faced with the decision to minimize the threat by shutting down network access. Do you have enough information to warrant a shutdown of the entire network or are only certain sites affected? Having analysis completed quickly can help in turn allow for faster decision-making.
What used to take hours with reviewing logs in Excel or even SQL databases, can now be done in seconds with KQL. This is possible in part due to the power of KQL which comes from native functions that help quickly parse and/or convert data to something more meaningful to an analyst. Some example functionality this provides is being able to decode Base64 data, parse URLs, and even parse command line arguments. Additionally, for any parsing or working with data that requires a bit more complexity than native querying, KQL does have plug-ins that can extend its use by leveraging Python and R.
Built-in Functions useful for Incident Response
Not unlike other large-data or database query languages, KQL allows you to:
- filter your data (with ‘where’ clauses);
- present your data (with either ‘project’ or ‘render’ clauses); and
- aggregate your data (with ‘summarize’ clauses).
The real power of KQL, though, comes from its various native functions that can be used to parse or transform data on the fly, including (and certainly not limited to) :
These functions are named in a self-explanatory way, but let’s look at a couple use cases that we’ve run across.
Decoding a suspicious PowerShell command
Sample suspicious PowerShell command decoded via KQL.
The suspicious command referenced here contains a value that is Gzip compressed and Base64 encoded. Here we’re using the built-in function parse_command_line() and gzip_decompress_from_base64_string() to get the plaintext.
Parsing a file path using parse_path()

Sample of parse_path function usage and resulting output.
Notice how in this example we’re able to use parse_path() which returns a dynamic object of the various path components (Scheme, RootPath, DirectoryPath, etc) that can then be queried using either bracket or dot notation.
Parsing a suspicious URL using parse_url()

Sample of parse_url function usage and resulting output.
Here we use parse_url() in order to break down the URL into its various components. The result is a dynamic object that (similar to parse_path() example above), can be queried via bracket or dot notation.
Custom Functions
Along with the previously mentioned built-in functions, custom functions can also be created. This allows for the ability to write a query and save it for re-use without having to re-write the query again. Some examples of these can be found on Github for Microsoft 365 Defender Advanced Hunting.
Custom functions go beyond only being able to surface artifacts of interest. Functions can add context to an artifact. Take the example of a malicious file created on a system:
C:Windowstempevil.exe
A function can be created to identify what else may have occurred within a set timeframe around the creation of that file. Depending on the data that is collected, this can include other file creations, modifications, event log entries, and more.

The custom function called EventsWithinTimeframe() accepts 3 parameters:
- Filepath – in this case, our example from earlier “C:Windowstempevil.exe”
- Timestamp type – for this example we’re focusing on the creation date
- Window of time – using 3h to indicate 3-hour time window before or after the creation date
The underlying query of the function takes the CreationDate of the artifact (C:Windowstempevil.exe) and returns all relevant events (event log entries, other file creation events, etc.) that surround the creation time of the artifact +/- 3 hours. Of course, the data you collect may be different and the underlying query will differentiate based on the schema of the data, however, the logic for this example is something that can be implemented to suit your requirements.
Custom functions are limited only by your imagination. These can be simple one-line queries that help surface a particular artifact, a “utility” type function that converts data to a different format, or a more advanced type query that can provide a full context around a given artifact. You can even invoke functions within functions. Thanks to the power and flexibility of KQL the possibilities are endless.
Joining and External Data
Just like other query languages, KQL can perform a variety of joins. Kusto extends this capability beyond the current database to cross-cluster joins and even allows for external data sources to be queried and referenced. While joining is commonly done when enriching the context of current artifacts of interest (e.g., to another database that contains information about threat actor C2 infrastructure), let’s focus on the external data sources to show how this can be leveraged during incident response engagements, as well.
Using externaldata() to reference SHA256 hashes

Sample query using externaldata operator
This example is taken from a query shared on Microsoft 365 Defender Hunting Queries that checks for SHA256 hashes in an external feed against the SHA256 hashes from mail flow data. What’s great about this is that there is minimal setup to get the external data made useful for enriching the data being analyzed. You can work with a variety of file formats (CSV, JSON, TXT, etc.) and extract the data you need for working with it further.
Going even further with KQL
Beyond the functions that are built-in which help during an incident response investigation, KQL allows for even more capability and flexibility by being able to extend its usage with plugins. Incident responders will appreciate the R and Python plugins that Kusto offers to work with data beyond what is possible in native KQL today.
Both plugins allow for working with tabular input and will produce tabular output that can be worked with in any follow-on KQL. For the example below, we’ll be focusing on Python.
Recreating PowerShell Script from Event Logs
In certain cases, the only remaining artifact that gives the executed PowerShell comes from the PowerShell Operational Event ID 4104 entries, otherwise known as script block logging. In certain cases, the entirety of the PowerShell script is divided into multiple script blocks which must then be merged back together to view the full script. We’ll be using Python to accomplish this.

Lines 1 and 27 are the actual creation of the function. Lines 2 through 10 are used to query our collected data and prepare it for working with Python. Line 11 sets up the output column for our Python script. Line 12 uses the evaluate operator in order to invoke the Python plugin. Lines 13 through 24 are the actual Python that we use to work with the data as a Pandas dataframe. Note that Pandas and numpy are imported by default and other supported Python libraries can be imported as needed.
Conclusion
KQL allows for speed and flexibility when working with large datasets during incident response engagements. The built-in functions that are used to parse various pieces of data allow for analysts to work with what matters to them, rather than spending additional time trying to manually parse and process data. Custom functions provide users a method for taking a query and turning it into a sharable and repeatable action. KQL is further leveraged by enabling users to use scripting languages, such as R and Python, as another way to work with data.
Combined, these attributes and functionality, make KQL a highly effective tool for incident responders.
This blog and its contents are subject to the Microsoft Terms of Use. All code and scripts are subject to the applicable terms on Microsoft’s GitHub Repository (e.g., the MIT License).
by Contributed | Jan 3, 2022 | Technology
This article is contributed. See the original author and article here.
Happy Holidays & Happy New Year from the Microsoft Project team!
Year in Review
We added many new features to Project for the web in the last year. Here are some of our favorites:
- Project Accelerator ~ The Project Accelerator allows users to leverage Power Apps to manage the entire lifecycle of your projects, including demand management, financial goals, team development, and artifact tracking. You can learn more about how to use the Accelerator here.
- Email Notifications ~ Receive email notifications when you are added to a project or a roadmap, or when you are assigned to a task in Project for the web. Learn more about email notification options here.
- Import from Project Desktop ~ Import your .mpp files from Project Desktop to Project for the web. Learn more about how to import your files here.
- Better Filtering ~ Filter your tasks on the Grid, Board, and Timeline views. Additionally, you can now filter using keywords, finish dates, progress, bucket, or assigned to. Learn more about the expanded filtering options here.
- Choice custom fields ~ Create custom fields that allow you to choose from several options. Learn more about how to create choice custom fields here.

- Critical path ~ Users with Plan 3 & Plan 5 licenses can now highlight their critical path on the Timeline view. Learn more about how to highlight the critical path here.
- Teams Conversations ~ Add teams conversations to your tasks when using Project for Teams. Learn more about this feature here.

We’re so excited to continue improving Project for the web in 2022, including by adding some of our upcoming features:
- Labels ~ Add up to 25 different colored labels to your tasks in Project for the web.
- Charts view ~ As in Planner, use a chart view to visually assess the progress of your work through a Planner-like chart view.
- Guest users ~ Add guest users who are outside of your organization and not a part of your Microsoft 365 Group & assign tasks to them.
Of course, you can always give us feedback in our comments here or on our new Feedback Hub. Let us know what you want to see in Project moving forward!
by Contributed | Jan 1, 2022 | Technology
This article is contributed. See the original author and article here.
UPDATE (1/1/22 @10:45pm PST): We’ve created a solution to address the problem of messages stuck in transport queues on Exchange Server 2016 and Exchange Server 2019 because of a latent date issue in a signature file used by the malware scanning engine within Exchange Server. When the issue occurs, you’ll see errors in the Application event log on the Exchange Server, specifically event 5300 and 1106 (FIPFS), as illustrated below:
Log Name: Application
Source: FIPFS
Logged: 1/1/2022 1:03:42 AM
Event ID: 5300
Level: Error
Computer: server1.contoso.com
Description: The FIP-FS “Microsoft” Scan Engine failed to load. PID: 23092, Error Code: 0x80004005. Error Description: Can’t convert “2201010001” to long.
Log Name: Application
Source: FIPFS
Logged: 1/1/2022 11:47:16 AM
Event ID: 1106
Level: Error
Computer: server1.contoso.com
Description: The FIP-FS Scan Process failed initialization. Error: 0x80004005. Error Details: Unspecified error.
Please note the following regarding the solution:
- Implementation of the solution requires customer actions, and it will take some time to make the necessary changes, download the updated files, and clear the transport queues.
- Customer actions can be automated with the scan engine reset script from https://aka.ms/ResetScanEngineVersion or they can be performed manually. Every action taken by the script is listed in the manual steps below.
- Whether you perform the steps automatically or manually, they must be performed on every Exchange 2016 and Exchange 2019 server in your organization. If you use the automated script, you can run it on multiple servers in parallel.
- We recommend starting with the servers in your environment that have the largest queues. You can use Get-Queue to view queue size and determine which queues are the largest.
- If you previously disabled or bypassed antimalware scanning as a mitigation for this issue, we recommend that you re-enable it using the Enable-AntimalwareScanning.ps1 script after performing the steps below.
- The version info for the updated file represents only a sequence change. Once the solution is implemented, your server will continue to receive new AV updates as expected.
Using the Automated Solution
Run the script on each Exchange mailbox server in your organization. Edge Transport servers are unaffected by this issue. You can run this script on multiple servers in parallel. After the script has completed, you will see the following output:
[PS] C:Program FilesMicrosoftExchange ServerV15Scripts>.Reset-ScanEngineVersion.ps1
EXCH1 Stopping services…
EXCH1 Removing Microsoft engine folder…
EXCH1 Emptying metadata folder…
EXCH1 Starting services…
WARNING: Waiting for service ‘Microsoft Filtering Management Service (FMS)’ to start…
WARNING: Waiting for service ‘Microsoft Filtering Management Service (FMS)’ to start…
WARNING: Waiting for service ‘Microsoft Filtering Management Service (FMS)’ to start…
WARNING: Waiting for service ‘Microsoft Filtering Management Service (FMS)’ to start…
WARNING: Waiting for service ‘Microsoft Exchange Transport (MSExchangeTransport)’ to start…
EXCH1 Starting engine update…
Running as EXCH1-DOMAdministrator.
——–
Connecting to EXCH1.CONTOSO.com.
Dispatched remote command. Start-EngineUpdate -UpdatePath http://amupdatedl.microsoft.com/server/amupdate
——–
[PS] C:Program FilesMicrosoftExchange ServerV15Scripts>Get-EngineUpdateInformation
Engine : Microsoft
LastChecked : 01/01/2022 08:58:22 PM -08:00
LastUpdated : 01/01/2022 08:58:31 PM -08:00
EngineVersion : 1.1.18800.4
SignatureVersion : 1.355.1227.0
SignatureDateTime : 01/01/2022 03:29:06 AM -08:00
UpdateVersion : 2112330001
UpdateStatus : UpdateAttemptSuccessful
Using the Manual Solution
In lieu of using the script, customers can also manually perform steps to resolve the issue and restore service. To manually resolve this issue, you must perform the following steps on each Exchange mailbox server in your organization. Edge Transport servers are unaffected by this issue.
Remove existing engine and metadata
1. Stop the Microsoft Filtering Management service. When prompted to also stop the Microsoft Exchange Transport service, click Yes.
2. Use Task Manager to ensure that updateservice.exe is not running.
3. Delete the following folder: %ProgramFiles%MicrosoftExchange ServerV15FIP-FSDataEnginesamd64Microsoft.
4. Remove all files from the following folder: %ProgramFiles%MicrosoftExchange ServerV15FIP-FSDataEnginesmetadata.
Update to latest engine
1. Start the Microsoft Filtering Management service and the Microsoft Exchange Transport service.
2. Open the Exchange Management Shell, navigate to the Scripts folder (%ProgramFiles%MicrosoftExchange ServerV15Scripts), and run Update-MalwareFilteringServer.ps1 <server FQDN>.
Verify engine update info
1. In the Exchange Management Shell, run Add-PSSnapin Microsoft.Forefront.Filtering.Management.Powershell.
2. Run Get-EngineUpdateInformation and verify the UpdateVersion information is 2112330001.
After updating the engine, we also recommend that you verify that mail flow is working and that FIPFS error events are not present in the Application event log.
Original post below:
We are aware of and working on an issue causing messages to be stuck in transport queues on Exchange Server 2016 and Exchange Server 2019. The problem relates to a date check failure with the change of the new year and it not a failure of the AV engine itself. This is not an issue with malware scanning or the malware engine, and it is not a security-related issue. The version checking performed against the signature file is causing the malware engine to crash, resulting in messages being stuck in transport queues.
We are actively working on resolving this issue and expect to release details on how to resolve this issue later today. In the meantime, if your organization performs malware scanning of messages outside of your on-premises Exchange servers (for example, by routing mail through Exchange Online, or by using a third-party message hygiene solution), you can bypass or disable malware scanning on your Exchange servers and clear your transport queues. You should use one of these workarounds only if you have an existing malware scanner for email other than the engine in Exchange Server. See the following articles for details on how to disable or bypass malware scanning:
Our engineers were working around the clock on a fix that would eliminate the need for customer action, but we determined that any change that did not involve customer action would require several days to develop and deploy. We are working on another update which is in final test validation. The update requires customer action, but it will provide the quickest time to resolution.
We expect to have this update to you shortly along with the actions required by you. We are sorry for any inconvenience that this issue has caused.
— The Exchange Team
by Contributed | Dec 31, 2021 | Technology
This article is contributed. See the original author and article here.
Overview:
We sometimes see customers asking questions related to a discrepancy between the server storage usage and their expectations on the actual data usage. In this blog we will go through how to investigate storage consumption for Azure Database for PostgreSQL.
Solution:
In this section, I am listing down some thoughtful insights and recommendations to breakdown the storage usage to some extent.
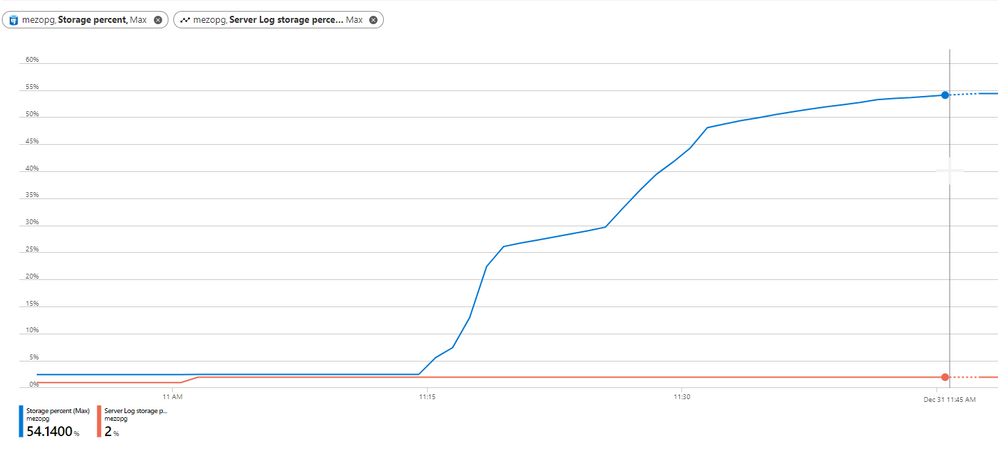
1) First and foremost, monitor the server storage usage using the available Azure PostgreSQL Metrics:
Storage percentage |
Percent |
The percentage of storage used out of the server’s maximum. |
Storage used |
Bytes |
The amount of storage in use. The storage used by the service may include the database files, transaction logs, and the server logs. |
Server Log storage percent |
Percent |
The percentage of server log storage used out of the server’s maximum server log storage. |
Server Log storage used |
Bytes |
The amount of server log storage in use. |
Server Log storage limit |
Bytes |
The maximum server log storage for this server. |
Storage limit |
Bytes |
The maximum storage for this server. |
On Azure Portal, you can use more than one metrics as shown in below figure:
Note:- Azure PostgreSQL flexible server comes with “Transaction Log Storage Used” metric, which depicts the amount of storage space used by the transaction logs. |
2) The following queries can help you to have insights upon the database storage usage:
- run below query to know each database size
SELECT pg_database.datname as "database_name", pg_database_size(pg_database.datname)/1024/1024 AS size_in_mb FROM pg_database where datname not like ('%azure%') ORDER by size_in_mb DESC;
- Check out the tables’ vacuum status, if dead rows are being vacuumed using pg_stat_user_tables
SELECT relname,n_dead_tup, n_tup_del,n_tup_upd, last_vacuum, last_autovacuum,last_analyze,last_autoanalyze FROM pg_stat_user_tables;
- You can get each database temporary files and size using view pg_stat_database
SELECT * FROM pg_stat_database;
- A quick look at view pg_stat_archiver can be a good idea, the view is showing statistics about the WAL archiver process’s activity.
select * from pg_stat_archiver;
3) Examine the following server parameters which might contribute into the storage usage growth
The general advice that you should be careful with the verbose logging, More information can be found in my colleague blog How to configure Postgres log settings – Microsoft Tech Community
It worth to mention that you can set the retention period for this short-term log storage using the log_retention_period parameter. The default value is 3 days; the maximum value is 7 days. The short-term storage location can hold up to 1 GB of log files. However, after 1 GB, the oldest files, regardless of retention period, will be deleted to make room for new logs.
For longer term retention and larger storage, consider using Azure diagnostic settings. see the Azure PostgresSQL logging documentation for more information.
4) Logical Decoding
Unnecessary PostgreSQL Logical decoding replication slots can have high impact on the server availability and storage consumption, replication slots hold on to Postgres WAL logs and relevant system catalogs until changes have been read by a consumer. in case this is failing to do so, the unconsumed logs will pile up and fill the server storage.
Therefore, it is critical that logical replication slots are consumed continuously. If a logical replication slot is no longer used, you need to drop it immediately.
You can check replication slots on server by running:
select * from pg_replication_slots;
In case the slot is no longer needed, you can simply delete it using the command:
SELECT pg_drop_replication_slot('<slot-name>');
For more information, see Azure PostgreSQL Logical Decoding.
5) Leverage PostgreSQL VACUUM and Autovacuum to reclaim the unused space.
Note:- VACUUM FULL, which can reclaim more space, but takes much longer and exclusively locks the table. Plus an extra disk space will be needed, since it writes a new copy of the table and doesn’t release the old copy until the operation is complete. |
6) Enable Storage Auto-grow and set up an alert
Last but not least, we always recommend that you enable storage auto-grow or set up an alert to notify you when your server storage is approaching the threshold so you can avoid getting into the read-only state. For more information, see the documentation on how to set up an alert.

Note:- Keep in mind that storage can only be scaled up, not down. |
I hope you find this article helpful. If you have any feedback, please do not hesitate to provide it in the comment section below.
Ahmed S. Mazrouh

Recent Comments