by Contributed | Jan 14, 2021 | Technology
This article is contributed. See the original author and article here.
Introduction
Customers often want to test and validate the capabilities of products before using them in mission critical environments. Same is true for Azure Web Application Firewall (WAF), where customers often have a need to test its security capabilities and validate their effectiveness before deciding to secure their production workloads with it.
To enable customers in rapidly validating the effectiveness of Azure WAF against real world web application attacks, we have designed this four-part lab tutorial. Part one of the tutorial provides guidance to quickly deploy a test environment with all required components. Parts two through four provide step by step walkthroughs for attacking a vulnerable web application with common, real-world, publicly available hacking and attack tools.
Tutorial Overview
The purpose of the Azure WAF security protection and detection lab tutorial is to demonstrate Azure Web Application Firewall (WAF) capabilities in identifying, detecting, and protecting against suspicious activities and potential attacks against your Web Applications. In this four-part tutorial, you will learn how to
- Configure the working environment to test Azure WAF protection against web application attacks
- Emulate an adversary by attacking and exploiting a vulnerable web application using step by step instructions
- Review Azure Monitor Workbook for WAF to understand WAF detection and processing logic for specific attack patterns used in every tutorial
The lab tutorials provide walkthroughs for running successful attacks against the vulnerable OWASP Juice Shop web application when it is exposed to the internet directly, without Azure WAF. The tutorials then also demonstrate effectiveness of Azure WAF on Application Gateway in blocking the same attacks against the same instance of the vulnerable OWASP Juice Shop Application when it is protected by Azure WAF.
This lab focuses on the OWASP protection ruleset and logging capabilities of Azure WAF. The lab does not include advanced application security concepts and is not intended to be a reference for application security testing as these areas are broader than the use cases demonstrated herein.
Part 1 – Lab Setup
The first tutorial in this four-part series walks you through deploying/creating a lab environment for testing Azure WAF protection and logging capabilities. The tutorial includes information about machines and tools that are needed to set up the lab and complete its playbooks. The instructions assume you are comfortable with deploying and administering resources in Azure and have some familiarity with web application security concepts. The closer your lab is to the suggested lab setup, the easier it will be to follow Azure WAF testing procedures. When your lab setup is complete, use the Azure WAF Security Protection and Detection playbooks for testing.
Setup an Azure WAF Attack Testing Lab
Part 2 – Reconnaissance Playbook
The second tutorial in this four-part series is a reconnaissance playbook. Reconnaissance activities allow attackers to gain a thorough understanding and complete mapping of your web application for later use. The playbook shows Azure WAF capabilities in identifying, detecting, and protecting against suspicious activities from potential recon attacks using examples from common, publicly available hacking and attack tools.
Reconnaissance Playbook
Part 3 – Vulnerability Exploitation Playbook
The vulnerability exploitation playbook is third in the four-part tutorial series. In the exploitation phase, an attacker attempts to exploit known or a previously identified vulnerability with intent to elevate privileges. As you run through this playbook, you will see Cross Site Scripting (XSS) detections and rules get triggered on Azure WAF from the attack you will simulate in your lab.
Cross Site Scripting (XSS) attacks are performed against web applications with the intent of compromising end users or the application itself.
Vulnerability Exploitation Playbook
Part 4 – Data Disclosure and Exfiltration Playbook
The last tutorial in the four-part series is the data exfiltration playbook. During the data exfiltration phase, an attacker has already gained access to your application backend and attempts to disclose and copy sensitive data. You will simulate an SQL Injection (SQLi) attack to see the attack detection and protection capability of Azure WAF.
SQL Injection (SQLi) attacks are performed against web applications with the intent of exposing/exfiltrating sensitive application and user data.
Data Disclosure and Exfiltration Playbook
by Contributed | Jan 14, 2021 | Technology
This article is contributed. See the original author and article here.
We’re pleased to announce that the Microsoft Information Protection SDK version 1.8 is now generally available via NuGet and Download Center.
Highlights
This release of the Microsoft Information Protection SDK we’ve focuses on better support for macOS, as well as quality and performance fixes.
Summary:
- Added support for Mac on ARM.
- Signed all dylib files for Mac.
- All clouds are fully supported across all three SDKs.
- Rename
TelemetryConfiguration to DiagnosticConfiguration.
- Updated
MipContext to accept DiagnosticConfiguration instead of TelemetryConfiguration.
- Exposed new
TelemetryDelegate and AuditDelegate.
- Added support for user-defined labels with double key encryption.
- Added an API,
MsgInspector.BodyType to expose body encoding type for MSG files.
- Added APIs to support Double Key Encryption with User-Defined Permissions.
For a full list of changes to the SDK, please review our change log.
Metadata Updates
In November, we announced that the metadata location for Office files would be moving. While the legacy metadata storage in custom.xml is still in use, Office features will be made available in 2021 that require the new storage location. For more details on this update, please review https://aka.ms/mipsdkmetadata. We encourage you to begin updating, testing, and deploying MIP SDK 1.8 so that your customers, applications, and services can take advantage of these new features as they become available. Also be sure to checkout the MIP SDK FAQ for a section on these changes.
Java Support
In MIP SDK 1.7, we announced the public preview of our Java wrapper. We aren’t quite ready to announce that it’s generally available, yet, and will continue to look for feedback as we start work on MIP SDK 1.9.
The Java Wrapper for MIP SDK 1.8 now supports streams. You’ll no longer be required to pass in files directly.
Wrap Up
As always, we appreciate your support, feedback, and efforts to integrate the MIP SDK into your applications and services. Here’s a quick recap of some helpful MIP SDK resources.
-Tom Moser
by Contributed | Jan 14, 2021 | Technology
This article is contributed. See the original author and article here.
This document provides an overview of how enterprise customers can deploy Microsoft Teams-DLP for protecting sensitive information that is traversing with-in or outside of the organization. Unified DLP has integration with multiple workloads that help to protect customer data with a single policy. Teams-DLP is one of the workloads within the Unified-DLP console. This guide walks through the different aspects of deploying use cases across content/containers and shows the effectiveness of the unified DLP portal as a single place to define all aspects of your DLP strategy.
In summary, this play book will help to
- Understand the unified console and interface.
- Develop a strategy for deploying Teams-DLP across the organization.
- Provide near real time Alerts with notifications.
- Review various scenarios to test Teams-DLP over chat and channel communication.
This document helps readers plan and protect sensitive information scenarios that normally exist in every organization. This Playbook helps as a user guide to mitigate the risk of exchanging crucial data while communicating over chat or giving access to sites for guest users.
If you have any questions on this play book or suggestions, please reach out to our yammer group at aka.ms/askmipteam
Thank you Pavan and team for writing this!!! :)
by Contributed | Jan 14, 2021 | Technology
This article is contributed. See the original author and article here.
Happy New Year! We are excited to announce that the January 2021 release (1.2020.1219.0) of the MSIX Packaging Tool is now available!
We have released the MSIX Packaging Tool through the Microsoft Store, and are offering the offline download of the tool and license here as well. You can also check out the Quick Create VM to easily get the latest release in a clean environment.
Our January 2021 release features UX improvements to places like Package files and the Select installer page, as well as a full transition to supporting Device Guard Signing version 2. To learn more about the features and fixes we’ve made, you can check out our release notes. If you have any questions, feature ideas, or just want to connect with the Product Team, join our Tech Community. We love connecting and hearing from you, so don’t hesitate to file any feedback with us via the Feedback Hub as well!
Don’t forget about our Insider Program, which gets you early access to releases as they are in development!
Sharla Akers (@shakers_msft)
Program Manager, MSIX
by Contributed | Jan 14, 2021 | Technology
This article is contributed. See the original author and article here.
Authors: Lei Sun, Neta Haiby, Cha Zhang, Sanjeev Jagtap
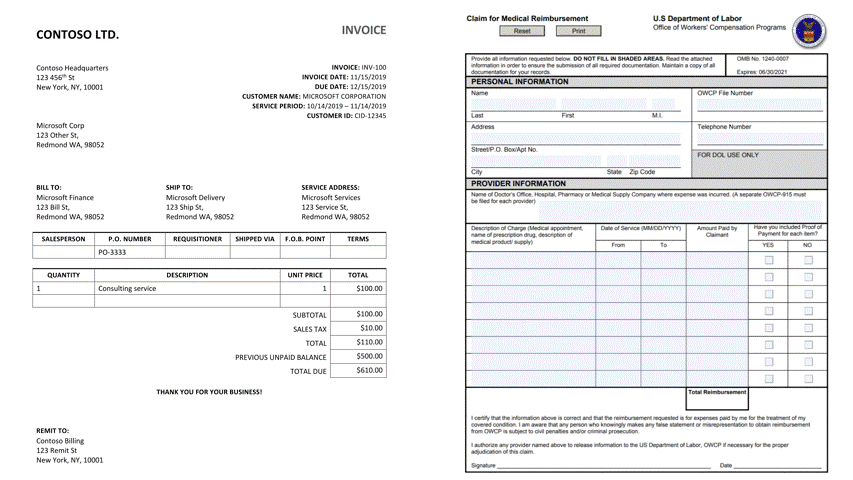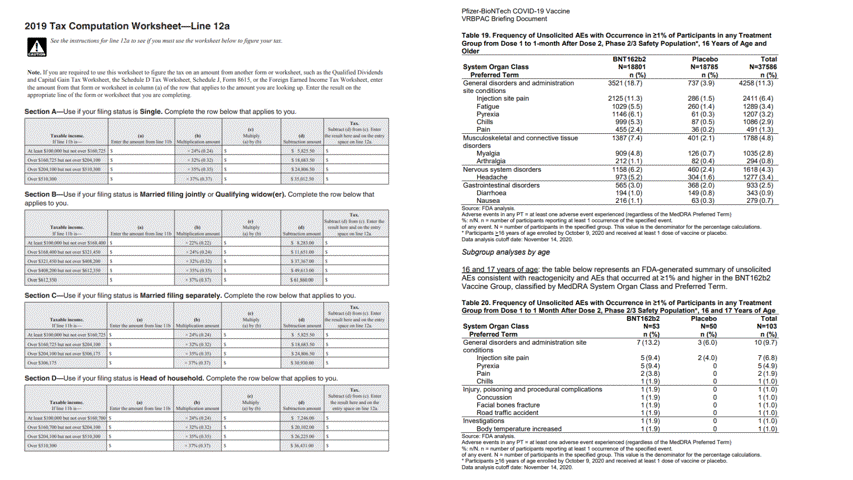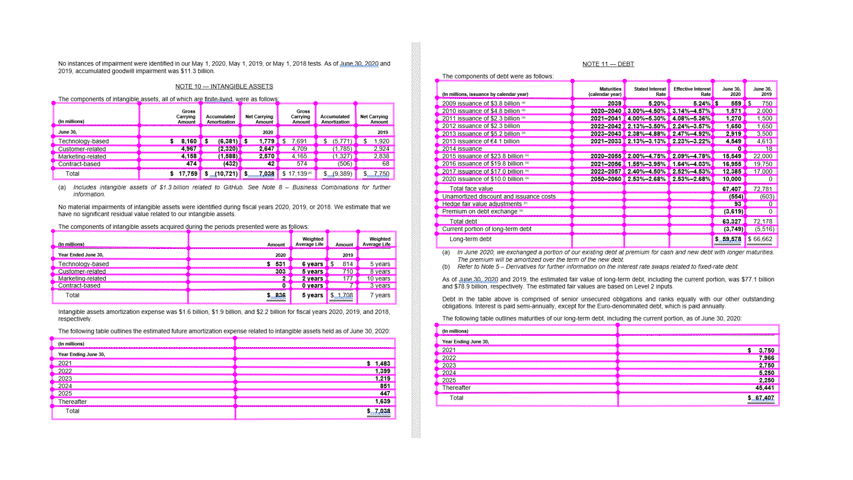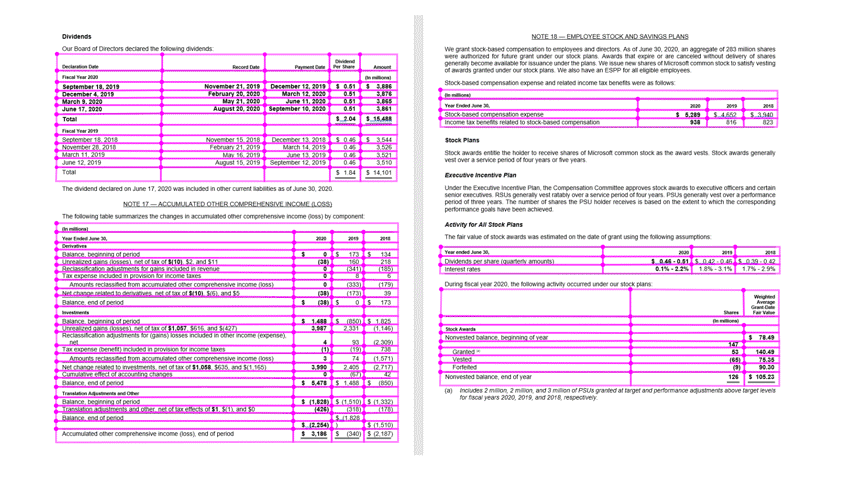
Documents containing tables pose a major hurdle for information extraction. Tables are often found in financial documents, legal documents, insurance documents, oil and gas documents and more. Tables in documents are often the most important part of the document but extracting data from tables in documents presents a unique set of challenges. Challenges include an accurate detection of the tabular region within an image, and subsequently detecting and extracting information from the rows and columns of the detected table, merged cells, complex tables, nested tables and more. Table extraction is the task of detecting the tables within the document and extracting them into a structured output that can be consumed by workflow applications such as robotic process automation (RPA) services, data analyst tools such as excel, databases and search services.
Customers often use manual processes for data extraction and digitization. However, with the new enhanced table extraction feature you can send a document (PDF or images) to Form Recognizer for extraction of all the information into a structured usable data at a fraction of the time and cost, so you can focus more time acting on the information rather than compiling it.

Table extraction challenges
Table extraction from a wide variety of document images is a challenging problem due to the heterogeneous table structures, diverse table contents, and erratic use of ruling lines. To name a few concrete examples, in financial reports and technical publications, some borderless tables may have complex hierarchical header structures, contain many multi-line, empty or spanned cells, or have large blank spaces between neighboring columns. In forms, some tables may be embedded in other more complex tabular objects (e.g., nested tables) and some neighboring tables may be very close to each other which makes it hard to determine whether they should be merged or not. In invoices, tables may have different sizes, e.g., some key-value pairs composed tables may contain only two rows/columns and some line-item tables may span multiple pages. Sometimes, some objects in document images like figures, graphics, code listings, structurally laid out text, or flow charts may have similar textures as tables, which poses another significant challenge for successful detection of tables and reduction of false alarms. To make matters worse, many scanned or camera-captured document images are of poor image quality, and tables contained in them may be distorted (even curved) or contain artifacts or noises. Existing table extraction solutions fall short of extracting tables from such document images with high accuracy, which has prevented workflow applications from effectively leveraging this technology.

Form Recognizer Table extraction
In recent years, the success of deep learning in various computer vision applications has motivated researchers to explore deep neural networks like convolutional neural networks (CNN) or graph neural networks (GNN) for detecting tables and recognizing table structures from document images. With these new technologies, the capability and performance of modern table extraction solutions have been improved significantly.
In the latest release of Form Recognizer, we created a state-of-the-art table extraction solution with cutting-edge deep learning technology. After validating that Faster/Mask R-CNN based table detectors are effective in detecting a variety of tables (e.g., bordered or borderless tables, tables embedded in other more complex tabular objects, and distorted tables) in document images robustly, we further proposed a new method to improve the localization accuracy of such detectors, and achieved state-of-the-art results on the ICDAR-2019 cTDaR table detection benchmark dataset by only using a lightweight ResNet18 backbone network (Table 1).
For the challenge of table recognition or table cell extraction, we leveraged existing CNN/GNN based approaches, which have proven to be robust to complex tables like borderless tables with complex hierarchical header structures and multi-line/empty/spanned cells. We further enhanced them to deal with distorted or even slightly curved tables in camera-captured document images, making the algorithm more widely applicable to different real-world scenarios. Figure 1 below shows a few examples to demonstrate such capabilities.

Easy and Simple to use
Try it out with the Form Recognizer Sample Tool.

Extracting tables from documents is as simple as 2 API calls, no training, preprocessing, or anything else needed. Just call the Analyze Layout operation with your document (image, TIFF, or PDF file) as the input and extracts the text, tables, selection marks, and structure of the document.
Step 1: The Analyze Layout Operation –
https://{endpoint}/formrecognizer/v2.1-preview.2/layout/analyze
The Analyze Layout call returns a response header field called Operation-Location. The Operation-Location value is a URL that contains the Result ID to be used in the next step.
Operation location –
https://cognitiveservice/formrecognizer/v2.1-preview.2/prebuilt/layout/analyzeResults/44a436324-fc4b-4387-aa06-090cfbf0064f
Step 2: The Get Analyze Layout Result Operation –
Once you have the operation location call the Get Analyze Layout Result operation. This operation takes as input the Result ID that was created by the Analyze Layout operation.
https://{endpoint}/formrecognizer/v2.1-preview.2/layout/analyzeResults/{resultId}
The output of the Get Analyze Layout Results will provide a JSON output with the extracted table – rows, columns, row span, col span, bounding box and more.
For example:

Get started

Recent Comments