by Contributed | Jan 26, 2021 | Technology
This article is contributed. See the original author and article here.
Teams is built on the Microsoft 365 hyper-scale, enterprise-grade cloud, delivering advanced security and compliance capabilities. These capabilities can be managed across Microsoft services including Teams through a single pane of glass experience in Microsoft 365 Security and Compliance centers.
Currently these capabilities are available in Teams for chat and file content. As a collaboration hub, Microsoft Teams brings together apps & services you love into Teams. Adaptive Cards, being platform-agnostic, are preferred vehicles for sharing information between Teams and other apps and services whether you are using apps for project management, productivity, sales, support and more.
More than 70% of the apps today generate card content in Teams conversations. Much of this is business communication and would fall under the purview of regulations as it is with Teams chat and file content.
We are excited to announce that Microsoft 365 compliance capabilities are now available for Adaptive Card content generated through apps in Teams messages. The following capabilities are now generally available:
- Legal hold: Preserve Adaptive Card content
- eDiscovery: Identify, collect and produce card content in response to an investigation
- Audit: Audit user activity on Adaptive Cards for forensics
- Retention: Manage card content lifecycle in Teams
The above capabilities are built in platform and will be available for all apps including 1P, 3P and LOB apps. There is no additional work required from app developers to enable them. For the tenant admins, selecting Teams as a location in the above compliance workflows will now automatically include card content generated through apps in the corresponding Teams conversations.
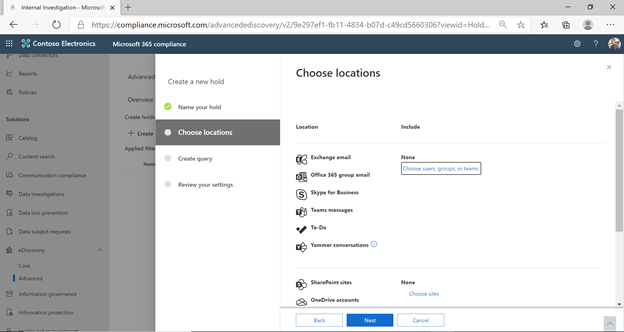
Legal hold
When a reasonable expectation of litigation exists, organizations are required to preserve electronically stored information (ESI), including Teams chat messages that are relevant to the case. Selecting Teams as a location in a Litigation hold workflow will now automatically include Adaptive Card content generated through apps in the corresponding Teams conversations including 1:1 chat, 1:many or group chat, or a channel conversation.
For more information on Teams and eDiscovery holds, please see Create an eDiscovery hold.
Figure 1 – Creating a new Legal hold
eDiscovery
Large Enterprises are often exposed to high penalty legal proceedings that demand submission of all Electronically Stored Information (ESI). Microsoft Teams content can be searched and used during eDiscovery investigations. Now in addition to chat and file content, Adaptive Card content generated through apps in Teams can be searched and exported.
Like Teams chat content, card content generated via Teams apps in 1:1 or group chats is journaled through to the respective user mailboxes and card content generated in channels is journaled through to the group mailbox representing the team. Adaptive Card content is converted to a html file and journaled as a message with the html file as attachment.
Selecting Teams as a location in Core eDiscovery or Advanced eDiscovery workflows will now automatically include card content generated through apps in the corresponding Teams conversations including 1:1 chat, 1:many or group chat, or a channel conversation.
For more information on Teams and eDiscovery, please see Conduct an eDiscovery investigation of content – Microsoft Teams | Microsoft Docs.
 Figure 2 – Selecting Teams location for a custodian in eDiscovery (will automatically include card content from Apps)
Figure 2 – Selecting Teams location for a custodian in eDiscovery (will automatically include card content from Apps)
 Figure 3 – Card content in eDiscovery review set
Figure 3 – Card content in eDiscovery review set
Audit
Audit log can help you investigate specific activities across Microsoft 365 services including Teams. Now inline input actions on Adaptive Cards will be available in the audit log. You can filter audit logs corresponding to actions on cards by selecting “Performed action on card” as the Teams activity.
 Figure 4 – Audit log for actions on card
Figure 4 – Audit log for actions on card
Retention
Retention policies help you to effectively manage the information in your organization. Use retention policies to keep data that’s needed to comply with your organization’s internal policies, industry regulations, or legal needs, and to delete data that’s considered a liability, that you’re no longer required to keep, or has no legal or business value.
Now, in addition to Teams chat and file content, you can include card content in your retention policies. Selecting Teams as a location while setting up retention policy will now automatically include Adaptive Card content generated through apps in the corresponding Teams conversations including 1:1 chat, 1:many or group chat, or a channel conversation.
 Figure 5 – Selecting Teams location while setting up a retention policy (will automatically include card content from apps)
Figure 5 – Selecting Teams location while setting up a retention policy (will automatically include card content from apps)
What app developers are saying about these new capabilities
We are thrilled to extend these Microsoft 365 compliance capabilities to card content generated from Teams apps. To help highlight how great these capabilities are, take a look at a few testimonials from the app developers that we worked closely to enable this feature!
SurveyMonkey
“SurveyMonkey allows organizations to collaborate on rich insights uncovered using our integrations, while ensuring data remains secure. The latest platform capabilities from Microsoft Teams allowed us to bring our mutual customers the improved data governance and compliance features with no additional implementation effort.”
Fuze
“For organizations with specific compliance, risk, and legal concerns––from manufacturing to financial services––Fuze provides safe and secure collaboration across the distributed workforce,” said Jed Brown, SVP of Product & Design at Fuze. “This extends to organizations utilizing the Fuze for Teams integration for click to call and click to meet. With Fuze for Teams, all interactions with the integration are compatible with Microsoft’s auditing and eDiscovery tools. By adhering to Microsoft’s development guidelines from the start, Fuze was able to easily comply with Teams controls for security and compliance and requires zero effort from customers to enable.”
Medxnote
“We are excited for the roll out of compliance capabilities in 3rd party apps. Being able to integrate into a customer’s existing compliance framework is a real and tangible benefit for Medxnote and our customers!”
We’d like to hear your feedback on the product to keep improving functionality, adding new features, and enhancing existing ones. Sign in today using your Microsoft 365 account, and give us feedback via the Feedback button at the bottom right corner of Microsoft 365 compliance center.
by Contributed | Jan 26, 2021 | Technology
This article is contributed. See the original author and article here.
In today’s fast-paced business environment, agility requires seamless data collaboration across the organization—and data engineers are key to an organization’s success. These professionals know that cloud analytics is a critical first step to resilient business transformation, and they spend their days unlocking data and putting it to work for key insights and ground-breaking value. If you have these skills and want to prove them, check out this certification.
The Azure Data Engineer Associate certification validates that you have subject matter expertise in designing and implementing the management, monitoring, security, and privacy of data solutions using the full stack of Azure data services to successfully support business needs.
You earn the certification by passing Exam DP-200: Implementing an Azure Data Solution and Exam DP-201: Designing an Azure Data Solution, which are live through June 30, 2021. Or, after February 23, 2021, you can earn the certification by passing Exam DP-203: Data Engineering on Microsoft Azure, which will eventually replace both Exam DP-200 and Exam DP-201. Data expertise is essential to the digital revolution, and the updated exam better aligns to the evolving skills of real-world data engineer roles.
Passing either the first set of exams or the new exam will earn you the certification. If you’ve been preparing for Exam DP-200 and Exam DP-201, you still have time to take them before they retire on June 30, 2021. If you’re just beginning your exam prep, consider taking the new exam instead, after the beta version is available on February 23, 2021. For more details, please read our blog post, We’re taking Azure certifications for data and AI to the next level.
What kind of knowledge and experience should you have?
Azure data engineers integrate, transform, and consolidate data from various systems into structures that are suitable for building analytics solutions. They explore and investigate specific data questions posed by stakeholders, and they build and maintain secure and compliant processing pipelines by using different tools and techniques. These professionals use various Azure data services and languages to store and produce cleansed and enhanced datasets for analysis.
Data engineers help ensure that data pipelines and stores are high-performing, efficient, organized, and reliable, given a specific set of business requirements and constraints. They deal with unanticipated issues swiftly, and they minimize data loss. They also design, implement, monitor, and optimize platforms to meet the pipeline needs.
These professionals must have solid knowledge of data processing languages, such as SQL, Python, or Scala, and they need to understand parallel processing and data architecture patterns.
To see how the required knowledge and experience will change with the new version of the exam, review the Exam DP-203 skills outline guide.
How can you get ready?
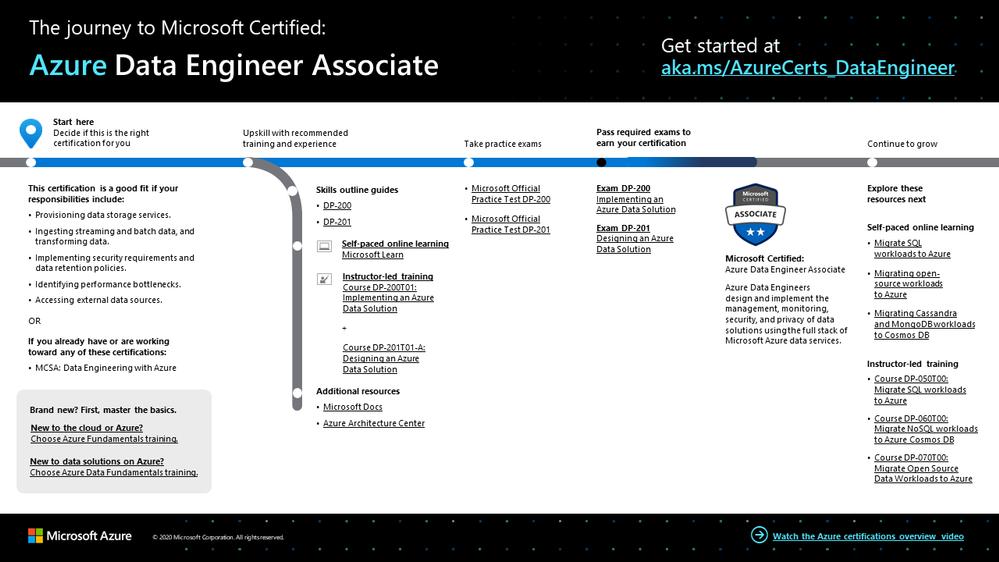
To help you plan your journey, check out our infographic, The journey to Microsoft Certified: Azure Data Engineer Associate. You can also find it in the resources section on the certification and exam pages, which contains other valuable help for Azure data engineers.
The journey to Azure Data Engineer Associate
To map out your journey, follow the sequence in the infographic. First, decide whether this is the right certification for you.
Next, to understand what you’ll be measured on, review the Exam DP-200 skills outline guide and the Exam DP-201 skills outline guide on the exam pages. To understand the skills measured by the new exam, check out the Exam DP-203 skills outline guide.
Sign up for training that fits your learning style and experience:
Complement your training with additional resources, like Microsoft Docs or the Azure Architecture Center. Don’t miss the Data Exposed show on Channel 9, which explores everything about data—relational and non-relational, on-premises and in the cloud, big and small.
Then take a trial run with Microsoft Official Practice Test DP-200: Implementing an Azure Data Solution or Microsoft Official Practice Test DP-201: Designing an Azure Data Solution. All objectives of the exam are covered in depth, so you’ll find what you need to be ready for any question.
After you pass the exam and earn your certification, check out the many other training and certification opportunities. Want to increase your knowledge and experience around Azure data engineering? Consider taking additional self-paced learning, like Migrate SQL workloads to Azure, or more in-depth instructor-led training, like Migrate Open Source Data Workloads to Azure.
Note: Remember that Microsoft Certifications assess how well you apply what you know to solve real business challenges. Our training resources are useful for reinforcing your knowledge, but you’ll always need experience in the role and with the platform.
Keep your certification up to date
If you’ve already earned your Azure Data Engineer Associate certification, but it’s expiring in the near future, we’ve got good news. You’ll soon be able to renew your current certifications by passing a free renewal assessment on Microsoft Learn—anytime within six months before your certification expires. For more details, please read our blog post, Stay current with in-demand skills through free certification renewals.
It’s time to level up!
Many organizations today have petabytes of data, and analytics and AI play pivotal roles in putting this data to work—as do data engineers. These professionals work with data from many sources, and they know how to do this quickly and securely to deliver cost savings, new insights, improved business processes, and ground-breaking value. Ready to prove your worth to your team—and to current and future employers? Roll up your sleeves, and get started earning your Azure Data Engineer certification.
Related announcements
Understanding Microsoft Azure certifications
Finding the right Microsoft Azure certification for you
Master the basics of Microsoft Azure – cloud, data, and AI
We’re taking Azure certifications for data and AI to the next level
Stay current with in-demand skills through free certification renewals
by Contributed | Jan 26, 2021 | Technology
This article is contributed. See the original author and article here.
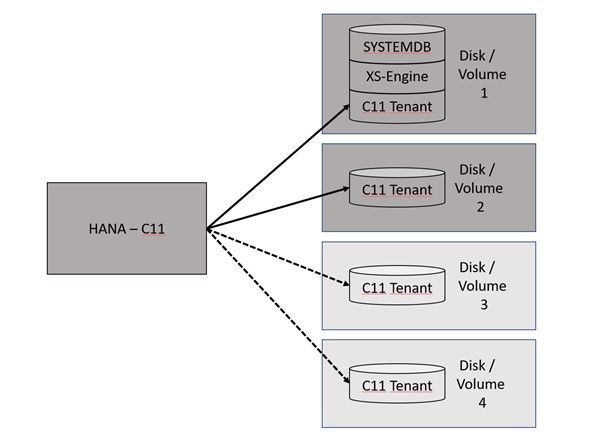
HANA Data Path Striping (partitioning)
Since SAP HANA 2.0 SPS03 (Rev 35) and above versions, data volumes on the Indexserver can be partitioned so that read and write operations can run in parallel with increased data throughput. Also, the HANA startup time will benefit from this feature because the data throughput will increase massively, depending in the number and performance of the additional disks or volumes.
HANA data partitioning is only available for data volumes not for log volumes.
This, of course, can be configured on our HLI’s and on VM’s with Premium Managed Disks or Azure NetApp Files (ANF).
There is no additional certification required.
Interesting Links:
SAP HANA – Partitioning Data Volumes | SAP Blogs
2400005 – FAQ: SAP HANA Persistence – SAP ONE Support Launchpad
2700123 – Indexserver Crash at PageAccess::PageFlushCallback::pageChunkWritten With “Unexpected offset” – SAP ONE Support Launchpad
Partitioning Data Volumes – SAP Help Portal
It can be one option to create a HANA partitioning with 2 or 4 volumes…
This documentation is covering the configuration of 2 data volumes.
HANA Disk Partitioning
Create a second data path directory.
mkdir -p /hana/data2/ML4/mnt00001
Create the /etc/fstab entry.
vi /etc/fstab
10.20.255.31:/hana_data2_a91_t250_vol /hana/data2/ML4/mnt00001 nfs rw,hard,nosuid,timeo=600,vers=4.1,rsize=1048576,wsize=1048576,intr,noatime,lock 0 0
Set the user permissions.
chown -R ml4adm:sapsys /hana/data2
Enable HANA to work with multi data partitioning.
su – ml4adm
cdcoc
vi global.ini
[customizable_functionalities]
persistence_datavolume_partition_multipath = true
restart HANA
sapcontrol -nr 02 -function StopSystem
sapcontrol -nr 02 -function StartSystem
See the actual size of the datavolume 1:
ls -l /hana/data/ML4/mnt00001/hdb00003.00003/
ml4adm sapsys 127708168192 Jan 18 08:01 datavolume_0000.dat
Execute the following SQL statement against the tenant database:
hdbsql -u system -p <PASSWD> -n localhost:30215
ALTER SYSTEM ALTER DATAVOLUME ADD PARTITION PATH '/hana/data2/ML4';
HANA will do the striping over time.
ls -l /hana/data2/ML4/mnt00001/hdb00003.00003/
ml4adm sapsys 0 Jan 18 08:04 datavolume_0001.dat
After some time the situation will change….
ls -l /hana/data2/ML4/mnt00001/hdb00003.00003/
ml4adm sapsys 23219666944 Jan 18 2021 datavolume_0001.dat
ls -l /hana/data/ML4/mnt00001/hdb00003.00003/
ml4adm sapsys 127708168192 Jan 18 08:43 datavolume_0000.dat
Benefits of Data Partitioning
With HANA data partitioning the HANA Savepoint will benefit massively from the striping over many disks/volumes. This Graph shown the savepoint behavior with a single data volume:
HCMT with multiple volumes
To measure the additional data files with HCMT use the appropriate json config file.
This config file is called multivolume.json…
Here is a place where we can add the additional datafiles…
"Variables": [
{
"Comment": "The <Value> should be adapted to the HANA log multi volume paths",
"Name": "LogVolumes",
"Value": "/hana/log/ML4/mnt00001",
"Request": "true"
},
{
"Comment": "The <Value> should be adapted to the HANA data multi volume paths",
"Name": "DataVolumes",
"Value": "/hana/data/ML4/mnt00001,/hana/data2/ML4/mnt00001",
"Request": "true",
"Profile": "LNX"
},
This is just a result on my system. Performance surly is dependent on many different parameter and configuration options.
As a result, we can compare the data write results.
Block size Data Write values with one data-file Data write values with two data-files
Initialwrite Overwrite Initialwrite Overwrite

Backup
For snapshot-based backups, please play close attention that you snapshot all data volumes belonging to the same database.
by Contributed | Jan 26, 2021 | Technology
This article is contributed. See the original author and article here.
So are you new to Git, GitHub, REST, Poweshell and Bash?
The following Modules are perfect introductions for you to get started on your developer journey.
Introduction to Git
Learn Series Length/Time to complete: 1 hr 15 min
Find out what source control is, and get an introduction to Git – the world’s most popular version control system.
Learning objectives
In this module, you will:
- Learn what version control is
- Understand distributed version control systems, like Git
- Create a new Git project and configure it
- Make and track changes to code using Git
- Use Git to recover from simple mistakes
Collaborate with Git
Learn Series Length/Time to complete: 55 mins
Use Git to track changes to source code and collaborate with other developers
Learning objectives
In this module, you will:
- Clone a repository
- Learn about and make a pull request
- Stash changes
- Push your changes and update your repo by pulling
Level up your Git knowledge by learning about how to keep code separate using branches and how to merge them later
Learning objectives
In this module, you will:
- Understand what Git branches are
- Create new branches and switch between branches
- Merge branches together
- Learn basic techniques for resolving merge conflicts
Do you want to communicate more effectively with other GitHub users? Are you looking for a free way to promote your GitHub project?
Learn how to use Markdown to effectively communicate with others in your GitHub issues, pull requests, comments, and documentation. Then learn how to build project sites and blog posts to promote your projects with GitHub Pages.
In this learning path, you’ll learn how:
- Markdown enables you to organize your thoughts through code, images, lists, and tables.
- GitHub-Flavored Markdown (GFM) enables syntax highlighting for popular programming languages and enables you to link to issues, pull requests, and commits.
- GitHub Pages helps you create project pages and blog posts that include custom themes.
Utilize the tight integration of Visual Studio Code with the Git source-control management system.
Learning objectives
In this module, you will:
- Use the Command Palette in Visual Studio Code to perform many Git tasks, such as cloning repositories and creating branches.
- Take visual cues from Visual Studio Code to understand the status of your work.
- Harness the Source Control view in Visual Studio Code to stage and unstage changes and create commits.
- Uncover numerous time-saving shortcuts that are tucked into the Visual Studio Code user interface.
Take full control of your GitHub projects. Through work planning and tracking, effective branching strategies, and extending GitHub through its API, manage releases all the way from idea to working software in the hands of your users.
In this learning path, you’ll learn how to:
- Use GitHub project boards to plan and track work.
- Package, version, and deliver software releases to consumers.
- Choose a branching strategy that enables team members to work in parallel.
- Resolve conflicts in code changes from multiple contributors.
- Use the GitHub API and GitHub Apps to build tools that improve your processes.
- Explore the history of your GitHub repository through issues, pull requests, and search.
Introduction to Bash
Learn Series Length/Time to complete: 57 mins
Use Bash to manage IT infrastructure.
Learning objectives
In this module, you will:
- Learn what shells are and what Bash is.
- Learn about the syntax of Bash commands.
- Learn about important Bash commands, such as ls, cat, and ps.
- Learn how to use I/O operators to redirect input and output.
- Learn how to update a server’s operating system.
- Learn how to find and terminate rogue processes.
- Learn how to use Bash to filter Azure CLI output.
Learn about the basics of PowerShell. This cross-platform command-line shell and scripting language is built for task automation and configuration management. You’ll learn basics like what PowerShell is, what it’s used for, and how to use it.
Learning objectives
After completing this module, you’ll be able to:
- Understand what PowerShell is and what you can use it for.
- Explore cmdlets.
- Construct a sequence of cmdlets in a pipeline.
- Apply sound filtering and formatting principles to your commands.
Learn about how to build a basic API, how to query APIs, and authentication strategies in Python and JavaScript while discovering unique art by using museum APIs.
Learning objectives
In this module, you will:
- Learn about RESTful APIs.
- Build your own simple API.
- Learn various strategies to connect to external APIs.
- Learn how to query two different museum APIs.
Learn how to enable the Windows Subsystem for Linux (WSL), install your favorite Linux distribution, set up an integrated dev environment with Visual Studio Code, and more.
The time it takes to complete this course could vary because you will need to install multiple tools.
Learning objectives
In this module, you will:
- Enable the Windows Subsystem for Linux on your Windows device.
- Install a Linux distribution.
- Use Linux commands and work across Windows and Linux file systems.
- Create a website with Node.js, running on WSL.
- Set up your dev environment with Visual Studio Code.
- Debug a Node.js Express app.
- Manage multiple Linux distributions.

by Contributed | Jan 26, 2021 | Technology
This article is contributed. See the original author and article here.
Learn to develop real-world Internet of Things solutions built with Microsoft Azure services from experts from around the world!
On January 19, the IoT Advocacy team partnered with 9 amazing IoT focused MVPs from around the world plus our very own Olivier Bloch and CVP of Azure IoT Sam George to deliver a live event across Asia Pacific, Europe Middle East, and the Americas in three unique time zones. This event served as a flagship demonstration of the Internet of Things – Event Learning Path, an open-source collection of IoT focused sessions designed for IoT Solution Architects, Business Decision Makers, and Development teams.
Each session begins with a 15 minute Introductory presentation and is supported by a 45 minute video recording which deep dives into the topics introduced. We encourage partners, field teams, and general IoT enthusiasts to reuse any portions of the content as they see fit for example: user group presentations, third party conferences, or internal training systems!
That is exactly what we did for the All Around Azure – A Developer’s Guide to IoT Event, with the help of a worldwide team of experts from the Azure IoT Community, we adapted the 15 minute introductory sessions for delivery to a global audience. The sessions drew 1,800+ live viewers over three local-specific timeslots.
There really is no better time than now to leverage our IoT skilling content as you can now officialize as an official Azure Certified IoT Developer with the availability of the AZ-220 IoT Developer Exam. And even better, we are currently running a “30 Days to Learn It – IoT Challenge” which challenges you to complete a collection of IoT focused modules on Microsoft Learn, and rewards you with a 50% off voucher to sit for the AZ-220 IoT Developer Exam!
You can catch up on all the excitement and learning from the All Around Azure IoT Event on Channel 9 or right here on the #IoTTechCommunity!
Keynote with Sam George and Olivier Bloch with SketchNote by @nityan
Live Sessions and Associated Deep Dives
With 80% of the world’s data collected in the last 2 years, it is estimated that there are currently 32 billion connected devices generating said data. Many organizations are looking to capitalize on this for the purposes of automation or estimation and require a starting point to do so. This session will share an IoT real world adoption scenario and how the team went about incorporating IoT Azure services.
Data collection by itself does not provide business values. IoT solutions must ingest, process, make decisions, and take actions to create value. This module focuses on data acquisition, data ingestion, and the data processing aspect of IoT solutions to maximize value from data.
As a device developer, you will learn about message types, approaches to serializing messages, the value of metadata and IoT Plug and Play to streamline data processing on the edge or in the cloud.
As a solution architect, you will learn about approaches to stream processing on the edge or in the cloud with Azure Stream Analytics, selecting the right storage based on the volume and value of data to balance performance and costs, as well as an introduction to IoT reporting with PowerBI.
For many scenarios, the cloud is used as a way to process data and apply business logic with nearly limitless scale. However, processing data in the cloud is not always the optimal way to run computational workloads: either because of connectivity issues, legal concerns, or because you need to respond in near-real time with processing at the Edge.
In this session we dive into how Azure IoT Edge can help in this scenario. We will train a machine learning model in the cloud using the Microsoft AI Platform and deploy this model to an IoT Edge device using Azure IoT Hub.
At the end, you will understand how to develop and deploy AI & Machine Learning workloads at the Edge.
A large part of value provided from IoT deployments comes from data. However, getting this data into the existing data landscape is often overlooked. In this session, we will start by introducing what are the existing Big Data Solutions that can be part of your data landscape. We will then look at how you can easily ingest IoT Data within traditional BI systems like Data warehouses or in Big Data stores like data lakes. When our data is ingested, we see how your data analysts can gain new insights on your existing data by augmenting your PowerBI reports with IoT Data. Looking back at historical data with a new angle is a common scenario. Finally, we’ll see how to run real-time analytics on IoT Data to power real time dashboards or take actions with Azure Stream Analytics and Logic Apps. By the end of the presentation, you’ll have an understanding of all the related data components of the IoT reference architecture.
In this session we will explore strategies for secure IoT device connectivity in real-world edge environments, specifically how use of the Azure IoT Edge Gateway can accommodate offline, intermittent, legacy environments by means of Gateway configuration patterns. We will then look at implementations of Artificial Intelligence at the Edge in a variety of business verticals, by adapting a common IoT reference architecture to accommodate specific business needs. Finally, we will conclude with techniques for implementing artificial intelligence at the edge to support an Intelligent Video Analytics solution, by walking through a project which integrates Azure IoT Edge with an NVIDIA DeepStream SDK module and a custom object detection model built using CustomVision.AI to create an end-to-end solution that allows for visualization of object detection telemetry in Azure services like Time Series Insights and PowerBI.






Recent Comments