Ingest and Transform Data with Azure Synapse Analytics With Ease
This article is contributed. See the original author and article here.
The Integrate Hub within Azure Synapse Analytics workspace helps to manage, creating data integration pipelines for data movement and transformation. In this article, we will use the knowledge center inside the Synapse Studio to immediately ingest some sample data, US population by gender and race for each US ZIP code sourced from 2010 Decennial Census. Once we have access to the data, we will use a data flow to filter out what we don’t need and transform the data to create a final CSV file stored in the Azure Data Lake Storage Gen2.
Using Sample Data From Azure Synapse Knowledge Center
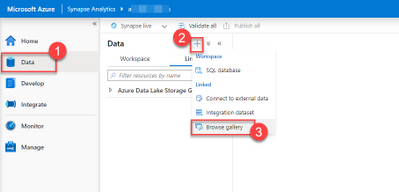
Our first step will be to get access to the data we need. Inside the Synapse workspace, choose the Data option from the left menu to open the Data Hub.
Data Hub is open. The plus button to add new artifacts is selected. Browser Gallery from the list of linked data source options is highlighted.
Once in the gallery, make sure Datasets page is selected. From the list of available sample datasets, choose US Population by ZIP Code and select Continue.

Knowledge Center dataset gallery is open. US Population by ZIP Code dataset is selected. Continue button is highlighted.
On the next screen, you can see the dataset’s details and observe a preview of the data. Select Add dataset to include the dataset into your Synapse workspace as a linked service.

US Population by ZIP Code dataset details are shown. Add dataset button is highlighted.
Data Exploration With the Serverless SQL Pool
Once the external dataset is included to your workspace as a linked service, it will show up under the Data hub as under Azure Blog Storage / Sample Datasets section. Select the Actions button for us-decennial-census-zip represented as “…” to see a list of available actions for the linked data source.

us-decennial-census-zip sample dataset is selected. The actions button is highlighted.
We will now query the remote data source using our serverless SQL pool to test our access to the data source. From the Actions menu Select New SQL Script / Select Top 100 rows. This will bring an auto-generated SQL script.

The actions menu for us-decennial-census-zip is shown. New SQL script is selected, and Select Top 100 rows command is highlighted.
Select Run and see the data presented in Results tab.

The actions menu for us-decennial-census-zip is shown. New SQL script is selected, and Select Top 100 rows command is highlighted.
Creating Integration Datasets for Ingest and Egress
Now that we proved our access to the data source, we can create integration datasets that will be our source and sink datasets. Feel free to close the current SQL Script window and discard all changes.

The Data hub is on screen. Add new resource button is selected. From the list of resources integration dataset is highlighted.
Select the “+” Add new resource button to open the list of available resources we can add to our Synapse workspace. We will create two integration datasets for our example. The first one will help us integrate our newly added remote data source into a data flow. The second one will be an integration point for the sink CSV file we will create in our Azure Data Lake Storage Gen2 location.
Select Integration dataset to see a list of all data sources you can include. From the list, pick Azure Blob Storage and select Continue.

New integration dataset window is open. Azure Blob Storage option is selected. Continue button is highlighted.
Our source files are in the Parquet format. Pick Parquet as the file format type and select Continue.

File format options window is open. Parquet is selected. Continue button is highlighted.
On the next screen set the dataset name to CensusParquetDataset. Select us-decennial-census-zip as the Linked service. Finally, for the file path set censusdatacontainer for Container, and release/us_population_zip/year=2010 for Directory. Select OK to continue.

Dataset properties window is open. The dataset name is set to CensusParquetDataset. Linked Service is set to us-decennial-census-zip. File path is set to censusdatacontainer. File Path folder is set to release/us_population_zip/year=2010. Finally, the OK button is highlighted.
Select the “+” Add new resource button and pick Integration dataset again to create our sink dataset. For this round, choose Azure Data Lake Storage Gen2 for the data store.

New integration dataset window is open. Azure Data Lake Storage Gen2 option is selected. Continue button is highlighted.
Our target file will be a CSV file. Pick DelimitedText as the file format type and select Continue.

File format options window is open. DelimitedText is selected. Continue button is highlighted.
On the next screen, set the dataset name to USCensus. Select Synapse workspace default storage as the Linked service. Finally, for the file path, select the Browse button and pick a location to save the CSV file. Select OK to continue. In our case, we selected default-fs as the file system and will be saving the file to the root folder.

Dataset properties window is open. The dataset name is set to USCensus. Linked Service is set to the default workspace storage. File path is set to default-fs. Finally, the OK button is highlighted.
Now that we have both our source and sink datasets ready. It is time to select Publish all and save all the changes we implemented.

CensusParquetDataset and USCensus datasets are open. Publish All button is highlighted.
Data Transformation With a Pipeline and a Dataflow
Switch to the Integrate Hub from the left menu. Select the “+” Add new resource button and select Pipeline to create a new Synapse Pipeline.

Integrate Hub is open. Add Resource is selected. Pipeline command is highlighted.
Name the new pipeline USCensusPipeline and search for data in the Activities panel. Select Data flow activity and drag and drop one onto the screen.

New pipeline window is open. Pipeline’s name is set to USCensusPipeline. The activities search box is searched for data. Data flow activity is highlighted.
Pick Create new data flow and select Data flow. Select Continue.

New data flow window is open. Create new data flow option is selected. Data flow is selected. The OK button is highlighted.
Once you are in the Dataflow designer give your Dataflow a name. In our case, it is USCensusDataFlow. Select CensusParquetDataset as the Dataset in the Source settings window.

Dataflow name is set to USCensusDataFlow. The source dataset is set to CensusParquetDataset.
Select the “+” button on the right of the source in the designer panel. This will open the list of transformation you can do. We will filter out the data to only include the ZIP Code 98101. Select Filter Row Modifier to add the activitiy into the data flow.

Data transformations menu is open. Filter row modifier is highlighted.
On the Filter settings tab you can define your filtering expression in the Filter on field. Select the field box to navigate to the Visual expression builder.

Filter settings tab is open. Filter on field is highlighted.
The data flow expression builder lets you interactively build expressions to use in various transformations. In our case, we will use equals(zipCode, “98101”) to make sure we only return records with the 98101 ZIP code. Before selecting Save and finish make sure you take a look at the Expression elements list and the Expression values that includes the fields extracted from the source data schema.

Visual expression builder is open. Expression is set to equals(zipCode, “98101”). Expression elements, expression values are highlighted. Save and finish button is selected.
Our data flow’s final step is to create the CSV file in Azure Data Lake Storage Gen2 for further use. We will add another step to our data flow. This time, it will be a sink as our output destination.

Data transformations menu is open. Sink is highlighted.
Once the sink is in place, set the dataset to USCensus. This is the dataset targeting our Azure Data Lake Storage Gen2.

Sink dataset is set to USCensus.
Switch to the Settings tab for the sink. Set the File name option to Output to single file. Output to single file combines all the data into a single partition. This leads to long write times, especially for large datasets. In our case, the final dataset will be very small. Finally, set the Output to single file value to USCensus.csv.

Sink settings panel is open. Output to single file is selected and it’s value is set to USCensus.csv. Set Single partition button is highlighted.
Now, it’s time to hit Publish All and save all the changes.

Publish all button is highlighted.
Close the data flow editor. Go back to our USCensusPipeline. Select Add Trigger and Trigger now to kick start the pipeline for the first time.

USCensusPipeline is open. Add trigger is selected and Trigger now command is highlighted.
Results Are In
To monitor the pipeline execution go to the Monitor Hub. Select Pipeline runs and observe your pipeline executing.

Monitor Hub is open. Pipeline runs is selected. USCensusPipeline pipeline row is highlighted showing status as in progress.
Once the pipeline is successfully executed, you can go back to the Data hub to see the final result. Select the workspace’s default Azure Data Lake Storage Gen2 location that you selected as your sink and find the resulting USCensus.csv file that is only 26.4KB with census data for the ZIP code used as the filter.

Data Hub is open. Workspace’s default ADLS Gen2 storage is open. USCensus.csv file and its 26.5KB size is highlighted.
Keeping Things Clean and Tidy
We created a list of artifacts in our Synapse workspace. Let’s do some cleaning before we go.
First of all, delete the CSV file our pipeline created. Go to the Data hub, select the workspace’s default Azure Data Lake Storage Gen2 location that you selected as your sink and find the resulting USCensus.csv file. Select Delete from the command bar to delete the file.

Data Hub is open. Workspace’s default ADLS Gen2 storage is open. USCensus.csv file is selected. Delete command is highlighted.
Go to the Integrate hub and select the USCensusPipeline we created. Select the Actions command and select Delete to remove the pipeline. Don’t forget to hit Publish All to execute the delete operation on the Synapse workspace.

Integrate Hub is open. USCensusPipeline is selected. Actions menu is open and delete command is highlighted.
Go to the Develop hub and select the USCensusDataFlow we created. Select the Actions command and select Delete to remove the dataflow. Don’t forget to hit Publish All to execute the delete operation on the Synapse workspace.

Develop Hub is open. USCensusDataFlow is selected. Actions menu is open and delete command is highlighted.
Go to the Data hub and select the USCensus we created. Select the Actions command and select Delete to remove the dataset. Repeat the same steps for the CensusParquetDataset as well. Don’t forget to hit Publish All to execute the delete operation on the Synapse workspace.

Develop Hub is open. USCensus is selected. Actions menu is open and delete command is highlighted.
Go to the Manage hub and select Linked services. From the list, select the us-decennial-census-zip. Select Delete to remove the linked service.

Manage Hub is open. The Linked services section is selected. The delete button for us-decennial-census-zip linked service is highlighted.
We are done. Our environment is the same as it was before.
Conclusion
We connected to a third-party data storage service that has parquet files in it. We looked into the files with the serverless SQL Pool. We created a pipeline with a data flow connecting to the outside source, filtering data out and putting the result in a CSV file in our data lake. While going through these steps, we have met with linked services, datasets, pipelines, dataflows, and a beautiful expression builder.
Go ahead, try out this tutorial yourself today by creating an Azure Synapse workspace.
- Sign up for an Azure free account and receive $200 of credit to try Azure Synapse
- Create an Azure Synapse workspace in minutes to access these new features

Recent Comments