This article is contributed. See the original author and article here.
Using replication in a MySQL setup, allows to copy data from a master server to one or more MySQL replica servers. There are a couple of reasons of using MySQL replication:
- It spreads read load across replica servers for improving performance;
- Enhance business security, continuity and performance using cross-region read replica: the replica can be in a different region from the master server;
- BI and analytical workloads can be used on a replica server without affecting the performance of the master server.
Regardless of scenario and the number of Azure Database for MySQL read replicas configured, since the replication is asynchronous there is a latency between master and replica server.
Replication latency due to IO or SQL errors
When the replication is started on the replica servers 2 threads are running:
- IO thread that connects to the master server, reads the binary logs and copies them to a local file that is called relay log;
- SQL thread that reads the events from relay log and applies them to the database.
First step to troubleshoot the replication latency is to check if the latency is either due to IO or SQL thread. As such on the replica server must be executed the following statement:
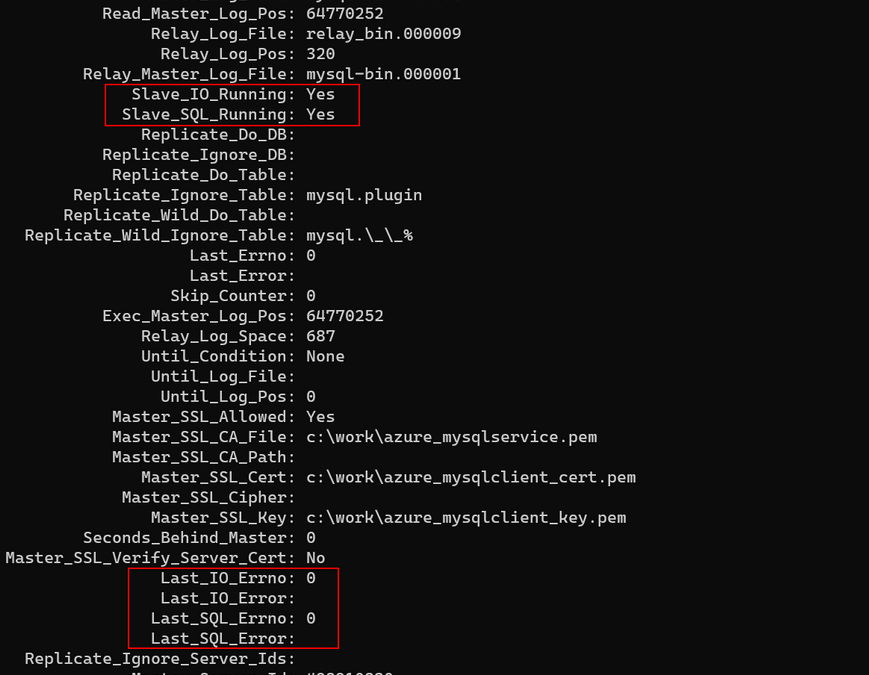
SHOW SLAVE STATUS
A typical output will look like:

Figure 1. SHOW SLAVE STATUS output
From above if Slave_IO_Running: Yes and Slave_SQL_Running: Yes then the replication is running, it is not broken. Shall be checked Last_IO_Errno/Last_IO_Error or Last_SQL_Errno/Last_SQL_Error that will hold the error number and error message of the most recent error that caused the SQL thread to stop. An error number of 0 and empty message means there is no error. Any error number not equal with 0, must be troubleshooted, can be checked as well the MySQL server error message reference for the given error number.
Replication Latency due to increase connections
A sudden spike in the number of connections increases the CPU usage for the simple fact that connections must be processed. In a situation when there is already a workload on the Azure Database for MySQL replica server and a sudden spike of connections is occurring the CPU will have to process the new connections and as a result the replication latency can increase. In such case the first step is to leverage the connectivity by using a connection pooler like ProxySQL.

Figure 2. Replication latency is increasing on new connections spike
As in most of the cases ProxySQL is implemented in a AKS cluster with multiple nodes or VM scale sets to avoid a single point of failure, sometimes connections spike can still occur. Out of the box MySQL will assign a thread for each connection, hence, thread pools that is supported from MySQL version 5.7 can be used. As such, we suggest enabling thread pooling on each MySQL replica server and properly configure thread_pool_min_threads and thread_pool_max_threads parameters based on the workload.
By default, thread_pool_max_threads = 65535 and this value simply will not gain any improvement as it will allow to create up till 65535 threads, which has no difference from the normal MySQL behavior. Instead, this parameter should be lowered to a value suitable for the workload. As an example, if this parameter is lowered to 200, even though there can be a couple of thousands of new connections, thread pool will allow to be processed a maximum of 200 connection threads.
After proper implementation of thread pools in Azure Database for MySQL replica servers, in case of a spike of connections the thread pool will limit the threads processed and the CPU will not increase, therefore replication will not be affected by the high number of new connections. We have seen big improvements in replication latency after implementing thread pool.

Figure 3. CPU and Replication latency not increasing on new connections spike (thread pool enabled)
Other keynote in here is that for enabling thread pools in Azure Database for MySQL parameter thread_handling must be changed from “one-thread-per-connection” to “pool-of-threads” and as this parameter is a static one, a server restart will be required for the change to apply. Although thread_pool_max_threads is a dynamic parameter, in a special case when reducing the value, for example from 1000 to 200, the MySQL server will not enlarge the thread pool furthermore, but also already existing threads will not be terminated, thus if the thread pool already contains 1000 threads, a server restart will be needed to reflect the new settings.
Replication latency due to no Primary or Unique key on a table
Azure Database for MySQL uses Row-Based replication, meaning that the master server writes events to the binary log about individual table row change, while the SQL Thread from the replica server will execute those changes to the corresponding table rows. Having no primary or unique key on a table it is also a common cause of replication latency, as some DML queries will need to scan all table rows to apply the changes from SQL thread.
In MySQL the primary key is an associated index that ensures fast query performance as it cannot include NULL values. Also, for InnoDB storage engine, the table data is physically organized to do ultra-fast lookups and sorts based on the primary key column or columns. Therefore, to ensure that the replica is able to keep up with changes from the source, we recommend adding a primary key on tables in the source server before creating the replica server or re-creating the replica server if you already have one.
Replication latency due to long running queries
It is possible that the workload on replica server to be the cause of the latency as the SQL thread cannot keep up with the IO thread. If it is the case, the slow query log should be enabled to help troubleshooting the issue. Slow queries can increase resource consumptions or slow down the server, thus replica will not be able to catch up with the master.
On the other hand, slow queries on master server can equally contribute to the latency as well. For instance, when a long running transaction on the master will complete, the data will be propagated to the replica server, but as it already took long to execute there will be already a delay. In such a case the latency is expected, thus long running queries should be identified and where possible to reduce the timings either by optimizing the query itself or breaking into smaller queries.
Replication latency due to DDL queries
Some DDL queries, especially ALTER TABLE can require a lock on a table, therefore should be used with caution in a replication environment. Depending on the ALTER TABLE statement executed, it might allow concurrent DML operations, for more details check MySQL Online DDL Operations. Also, some operations like CREATE INDEX will only finish when all transactions that accesses the table completed. In a replication scenario first the DDL command will be executed on the master server and only when completed will be propagated to the replica server(s).
In a heavy workload on both master and read replica servers an ALTER TABLE statement on the master server could take time to complete and the size of the table might be a contribution factor as well. When the operation completes, it will be propagated to the read replica server and depending on the ALTER statement it might require a lock on the table. In case a lock is required, the binary log will not be written, obviously the replication lag will start to increase from the moment the ALTER TABLE statement was propagated to the replica till the lock will be released. In such a case, the completion time will also depend on the workload on the replica or if there are long running transactions on the table that will increase the time furthermore.
Though Index dropping, renaming and creation should use INPLACE algorithm for the ALTER TABLE it will avoid copying table data, but may rebuild the table. Typically for INPLACE algorithm concurrent DML are supported, but an exclusive metadata lock on the table may be taken briefly during preparation and execution phases of the operation. As such, for CREATE INDEX statement the clauses ALGORITHM and LOCK may be used to influence the table copying method and level of concurrency for reading and writing, nevertheless adding a FULLTEXT or SPATIAL index will still prevent DML operations. See below an example of creating an index with ALGORITHM and LOCK clauses:
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Unfortunately, for DDL statement that requires a lock, replication latency cannot be avoided, instead these types of DDL operations should be performed when less load is given, for instance during nighttime to reduce potential customer impact.
Replication latency due to replica server lower SKU
In Azure Database for MySQL read replicas are created with the same server configuration as the master. The replica server configuration can be changed after it has been created. However, if the replica server will be downgraded, the workload can cause higher resource consumption that in turn can lead to replication latency. Therefore, it is recommended that the replica server’s configuration should be kept at equal or greater values than the source to ensure the replica is able to keep up with the master.
Please reach out to the Azure Database for MySQL team at AskAzureDBforMySQL@service.microsoft.com if you have any questions
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments