This article is contributed. See the original author and article here.
Return of the join in Power BI with Kusto
Summary
If you are not interested in all the details:
- You can add to the source statement in Power Query for dimension tables the clause: IsDimension=true
- You can use both dimensions and fact tables in Direct Query mode, and create relationships between them after you add this setting
- You can see an example in the attached PBI file
Before
The experience of many users, trying out Power BI with Kusto/ADX data was not always great.
Kusto’s main claim to fame is great performance with very large tables.
Trying to use such tables in PBI using Direct Query was not always fast and sometimes failed with errors about not enough memory to perform the query.
The reason behind this problem in many cases was the use of joins between tables.
Joins in Kusto
You can read about joins here.
One of the important recommendations is when joining a large table (Fact) with a much smaller table (Dimension), is to mention the small table first:
Customers | join kind=rightouter FactSales on CustomerKey
It is also recommended in such cases to add a hint:
Customers | join hint.strategy=broadcast kind=rightouter FactSales on CustomerKey
The hint allows the join to be fully distributed using much less memory.
Joins in PBI
When you create a relationship between two tables from Kusto, and both tables use Direct Query, PBI will generate a join between the two tables.
The join will be structured in this way:
FactSales | join Customers on CustomerKey
This is exactly the opposite of the recommended way mentioned above.
Depending on the size of the fact table, such a join can be slow, use a lot of memory or fail completely.
Recommended strategies until now
In blogs and presentations, we recommended few workarounds.
I’m mentioning it here because I would like to encourage you to revisit your working PBI reports and reimplement the joins based on the new behavior that was just released.
Import the dimension tables
If the dimension tables are imported, no joins will be used.
Any filters based on a dimension table will be implemented as a where based on the column that is the base of the relationship. In many cases this where statement will be very long:
| where CustomerKey in (123,456,678,…) .
If you filter on the gender F and there are 10,00 customers with F in the gender column, the list will include 10,000 keys.
This is not optimal an in extreme cases it may fail.
Join the table in a Kusto function and use the function in PBI
This solution will have good performance, but it requires more understanding of KQL and is different from the way normal PBI tables behave
Join the tables on ingestion using an update policy
Same as the previous method but requires even a deeper understanding of Kusto.
New behavior
Starting from the September version of PBI desktop, the Kusto connector was updated, and you can use relationships between dimension tables and fact table like with any other source with a few changes:
- In every table that is considered a dimension add IsDimension=true to source step so it will look like

- The data volume of the dimension tables (The columns you will use) should not exceed 10 megabytes.
- Relationships between two tables from Kusto will be identified by PBI as M:M. You can leave it as M:M but be sure to set the filtering direction to single from the dimension to the fact.
- When the relationship is M:M, the join kind will be inner. If you want a rightouter join (because you are not sure you have full integrity) you need to force the relationship to be 1:1. You can edit the model using Tabular editor (V2 is enough)
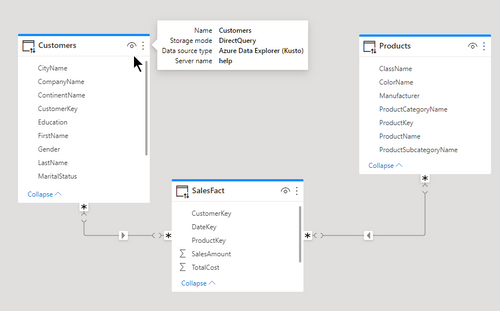
Before and after
In the attached example you can see two dimension tables with relationships to a fact table. The relationships are M:M and you can see the generated KQL in the text box.
The query as shown takes 0.5 seconds of CPU and uses 8MB of memory
The same query without the new setting takes 1.5 seconds of CPU and 478MB of memory.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments