This article is contributed. See the original author and article here.
Memory errors during data extraction from SAP using Azure Data Factory SAP Table connector
Azure Data Factory (ADF) is a fully managed data integration service for cloud-scale analytics in Azure. ADF provides more than 90 out of the box connectors to integrate with your source and target system. When we think about enterprise systems, SAP play a major role.
ADF has six different connectors to integrate with your SAP systems. Here are the connectors for ADF.
- SAP BW Open Hub
- SAP BW MDX
- SAP HANA
- SAP Table
- SAP C4C (Cloud for Customer)
- SAP ECC
You can read more about these connectors, when to use which one, support scenarios and more details here: https://github.com/Azure/Azure-DataFactory/blob/master/whitepaper/SAP%20Data%20Integration%20using%20Azure%20Data%20Factory.pdf
In this bog, we focus on memory error during data extraction from SAP using Azure Data Factory SAP Table connector. The SAP table depends on three layers of implementation:
- The SAP RFC Function module (/SAPDS/RFC_READ_TABLE2 or custom one)
- The SAP Driver – SAP Nco
- ADF SAP Table Runtime – Compile the partition queries/Trigger the SAP connection/calls/Wash the data/put the data into the downstream ADF runtime/sinks
In the recent customer engagement, we learned that while creating ADF Pipeline and transferring data, the following error occurs on a specific table.
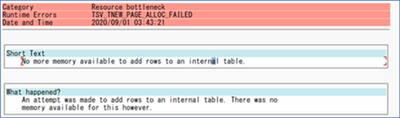
Operation on target Copy_z0z failed: ‘Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Failed to invoke function /SAPDS/RFC_READ_TABLE2 with error: SAP.Middleware.Connector.RfcAbapRuntimeException, message: No more memory available to add rows to an internal table., stacktrack: at SAP.Middleware.Connector.RfcConnection.ThrowRfcErrorMsg() at SAP.Middleware.Connector.RfcConnection.ReadBytes(Byte* buffer, Int32 count) at SAP.Middleware.Connector.RfcConnection.ReadRfcIDBegin(Int32& length) at SAP.Middleware.Connector.RfcConnection.ReadUpTo(RFCGET readState, RfcFunction function, RFCID toRid) at SAP.Middleware.Connector.RfcConnection.RfcReceive(RfcFunction function) at SAP.Middleware.Connector.RfcFunction.RfcDeserialize(RfcConnection conn, IRfcIOStream stream) at SAP.Middleware.Connector.RfcFunction.RfcCallReceive(RfcConnection conn, IRfcIOStream stream, RFCID rid) at SAP.Middleware.Connector.RfcFunction.Invoke(RfcDestination destination) at Microsoft.DataTransfer.Runtime.SapRfcHelper.SapRfcClient.InvokeFunctionInternal(IRfcFunction function, Boolean initStatefulSession, Boolean checkForErrors) at Microsoft.Practices.TransientFaultHandling.RetryPolicy.<>c__DisplayClass1.<ExecuteAction>b__0() at Microsoft.Practices.TransientFaultHandling.RetryPolicy.ExecuteAction[TResult](Func`1 func) at Microsoft.DataTransfer.Runtime.SapRfcHelper.SapRfcClient.InvokeFunction(IRfcFunction function, Boolean initStatefulSession, Boolean checkForErrors).,Source=Microsoft.DataTransfer.Runtime.SapRfcHelper,”Type=SAP.Middleware.Connector.RfcAbapRuntimeException,Message=No more memory available to add rows to an internal table.,Source=sapnco,’
This message also generated the short dump (ST22) in the SAP system. If you run a transaction ST22 in SAP application, you can see below error indicates SAP memory allocation to user is not enough.

This obviously means, you are extracting a way too much data that your SAP application with current memory configuration can handle. It does not mean, you server or VM running SAP is not capable, it just that you have restricted SAP application instance to restrict the memory. Now, logically there are a few possible solutions:
- Increase the memory parameters to high value in your application instance so it can handle more load.
- Use ABAP program RSMEMORY to adjust memory dynamically in the SAP application server. Temporary fix and reboot of app servers is not necessary.
- This can be done by adjusting the PHYS_MEMSIZE parameter to high value. You set this parameter in application instance profile, and it requires an SAP application instance where the parameter is configured, to be restarted (not a VM reboot)
- Reduce the data extraction size.
- This may be possible when you are doing incremental or delta extract. However, if you are doing a full pull it may not be possible.
- Reduce the data at source itself!
- This is sometimes possible by archiving or deleting the data from the source system itself. Be careful and ensure your decision of archiving/deleting before you do it.
Note: When you extract for the first time, you may have tons of data to load and need a lot of memory, and later with incremental load, you may reduce that memory footprint.
With the above recommendations, you did the first aid, and it may already solve your problem. However, you can further tune it for optimal performance.
Let’s take a look.
Sometimes, this can be a code issue, which can be an SAP standard code, or a Customer Code (aka Z programs)?
This usually results from reading in a dataset into an Internal Table, and trying to process it. This works for smaller source data. But if you try to do this and read from a database table that has grown beyond the size that a single work process is allowed to allocate, this error will result. The program needs to be able to handle the data in smaller chunks, Otherwise you will end up in a situation where you will progressively need to increase these parameters and will lead to poor performance over time. This is where you work with basis and dev team to run traces to look memory usage, runtime etc. One of the useful tools to assess SAP ABAP program is ABAP Runtime Analysis (transaction SE30).
For performance issues and ABAP runtime terminations due to data size, tracing the load using ST12 is a good starting point. It will give you additional insights on ABAP code, reading type, Programs and function module involved. Additionally, it is important to do a Table Analysis to identify which field can be used for range calculation, transaction DB05 can be used to analyze the distinct values of a table.
For huge SAP tables, the analysis should be started in a background task. The result is stored in the spool of background job TABLE_ANALYSIS_<table name>.

Recommendation
Here are some recommendations to consider while using SAP table connectors with ADF:
- Use the latest SHIR: Changing protocol from RFC to BASXML in runtime (which should be part of recent runtime anyway) not only helped to handle the bigger size data, but performance was improved significantly.
- Optimize the SAP application instance memory. Sometimes this could take several iterations to get the optimal memory value.
- Review the program code. For SAP program causing performance issues, often you have SAP OSS note to fix it. For customer codes (aka Z programs), dev team can trace and optimize it. Avoid using “Select *” in your extraction.
- Trigger extraction using a batch job. Often, dialog process has session expiration limit and cause process to fail.
- When planning Data extraction or replication scenarios, review the following:
- Table size
- Change rate.
- Memory and CPU requirements on the source, target and middleware layer
The classification of tables according to their size (Small, Medium and Large) and change rate derives proper sizing of the of all components involved.
- If the volume is quite large and there is column that can be used for partitioning, it is recommended to leverage the partitioning setting of the SAP Table source which will bring three main benefits:
- It can alleviate the memory consumption on the SAP instance
- It can help alleviate the memory burden on the SHIR machine as well
- Besides, it will be best for your performance since we offer the capabilities to retrieve data in parallel. The Unit of each processing is the partition you defined using the partition settings. For example, there is a table with 10 million rows, if you can have some partition settings to split it into 100 partitions which means each partition will have around 100K rows. With the parallelCopies set to 10(once partition Option is set with some NONE value, the default is 4. We are also enhancing the auto-Tuning logic to also increase based on the IR nodes number) then there will be 10 partitions processed at the same time. Suppose each thread has 3 M/s throughput, in ideal case, we can get 3 M/s * 10 = 30 M/s throughput.
- Currently we support 4 types of partitions: Int, Year(yyyy), CalendarMonth(yyyyMM) and CalendarDate(yyyyMMdd)
Thank you Damien Rodriguez, Wenbo Fu, Roman Broich, Morgan Deegan, Hitoshi Ikemoto, and Chan Uk Jin for your contribution to this blog.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments