This article is contributed. See the original author and article here.
The purpose of this series of articles is to describe some of the details of how High Availability works and how it is implemented in Azure SQL Managed Instance in both Service Tiers – General Purpose and Business Critical.
In this post, we shall introduce some of the high availability concepts and then dive into the details of the General Purpose service tier.
Introduction to High Availability
The goal of a high-availability solution is to mask the effects of a hardware or software failure and to maintain database availability so that the perceived downtime for users is minimized. In other words, high availability is about putting a set of technologies into place before a failure occurs to prevent the failure from affecting the availability of data.
The two main requirements around high availability are commonly known as RTO and RPO.
RTO – stands for Recovery Time Objective and is the maximum allowable downtime when a failure occurs. In other words, how much time it takes for your databases to be up and running.
RPO – stands for Recovery Point Objective and is the maximum allowable data-loss when a failure occurs. Of course, the ideal scenario is not to lose any data, but a more realistic (and also ideal) scenario is to not lose any committed data, also known as Zero Committed Data Loss.
In SQL Managed Instance the objective of the high availability architecture is to guarantee that your database is up and running 99.99% of the time (financially backed up by an SLA) minimizing the impact of maintenance operations (such as patching, upgrades, etc.) and outages (such as underlying hardware, software, or network failures) that might occur.
High Availability in the General Purpose service tier
General Purpose service tier uses what is called the Standard Availability model. This architecture model is based on a separation of compute and storage. It relies on the high availability and reliability provided by the remote storage tier. This architecture is more suitable for budget-oriented business applications that can tolerate some performance degradation during maintenance activities.
The Standard Availability model includes two layers:
A stateless compute layer that runs the sqlservr.exe process and contains only transient and cached data, such as tempdb database, that resides on the attached SSD Disk, and memory structures such as the plan cache, the buffer pool, and columnstore pool that resides on memory.
It also contains a stateful data layer where the user database data & log files reside in an Azure Blob storage. This type of repository has built-in data availability and redundancy features (Local Redundant Storage or LRS). It guarantees that every record in the log file or page in the data file will be preserved even if sqlservr.exe process crashes.
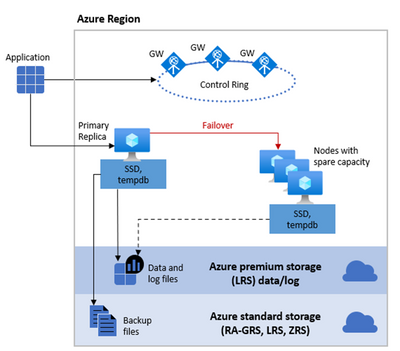
The behavior of this architecture is similar to an SQL Server FCI (SQL Server Failover Cluster Instance) but without all the complexity that we currently have on-premises or in an Azure SQL VM. In that scenario we would need to first create and configure a WSFC (Windows Server Failover Cluster) and then create an SQL Server FCI (SQL Server Failover Cluster Instance). All of this is done behind the curtains for you when you provision an Azure SQL Managed Instance, so you don’t need to worry about it. As you can see from the diagram on the picture above, we have a shared storage functionality (again like in an SQL Server FCI), in this case in Azure premium storage, and also we have a stateless node, operated by Azure Service Fabric. The stateless node not only initializes sqlservr.exe process but also monitors & controls the health of the node and, if necessary, performs the failover to another node from a pool of spare nodes.
All the technical aspects and fine-tuning of a cluster (i.e. quorum, lease, votes, network issues, avoiding split-brain, etc.) are covered & managed transparently by the Azure Service Fabric. The specific details of Azure Service Fabric go beyond the scope of this article, but you can find more information in the article Disaster recovery in Azure Service Fabric.
From the point of view of an application connected to an Azure SQL Managed Instance, you don’t have the concept of Listener (like in an Availability Groups implementation) or Virtual Name (like in an SQL Server FCI) – you connect to an endpoint via a Gateway. This is also an additional advantage since the Gateway is in charge of “redirecting” the connection to the Primary Node or a new Node in case of a Failover, so you don’t have to worry about changing the connection string or anything like that. Again, this is the same functionality that the Virtual Name or Listener provides, but more transparently to you. Also, notice in the Diagram above that we have redundancy on the Gateways to provide an additional level of availability.
Below is a diagram of the connection architecture, in this case using the Proxy connection type, which is the default:

In the Proxy connection type, the TCP session is established using the Gateway and all subsequent packets flow through it.
Storage
Regarding Storage, we use the same concept of “Shared Storage” that is used in a FCI but with additional advantages. In a traditional FCI On-Prem the Storage becomes what is known as a “Single Point of Failure” meaning that if something happens with the Storage – your whole Cluster solution goes down. One of the possible ways customers could work around this problem is with “Block Replication” technologies of the Storage (SAN) Providers replicating this shared Storage to another Storage (typically between a long distance for DR purposes). In SQL Managed Instance we provide this redundancy, using Azure Premium Storage for Data and Log files, with Local Redundancy Storage (LRS) and also separating the Backup Files (following our Best Practices) in an Azure Standard Storage Account also making them redundant using RA-GRS (Read Access Geo Redundant Storage). To know more about redundancy of backups files take a look at the post on Configuring backup storage redundancy in Azure SQL.
For performance reasons, the tempdb database is kept local in an SSD where we provide 24 GB per each of the allocated CPU vCores.
The following diagram illustrates this storage architecture:

It is worth mentioning that Locally Redundant Storage (LRS) replicates your data three times within a single data center in the primary region. LRS provides at least 99.999999999% (11 nines) durability of objects over a given year.

To find out more about redundancy in Azure Storage please see the following article in Microsoft documentation – https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy.
Failover
The process of Failover is very straightforward and of course you can have either a “planned failover” – such as a user-initiated manual failover or a system-initiated failover taking place because of a database engine or operating system upgrade operation, and an “unplanned failover” taking place due to a failure detection (i.e. hardware, software, network failure, etc.).
Regarding an “unplanned” or an “unexpected” failover, when there are critical errors in the Azure SQL Managed Instance functioning, an API call is made to communicate the Azure Service Fabric that a Failover needs to happen. Of course, the same happens when other errors (like a faulty node) are detected. In this case, the Azure Service Fabric will move the stateless sqlservr.exe process to another stateless compute node with sufficient free capacity. Data in Azure Blob storage is not affected by the move, and the data/log files are attached to the newly initialized sqlservr.exe process. After that a Recovery Process on the Databases is initiated. This process guarantees 99.99% availability, but a heavy workload may experience some performance degradation during the transition since the new sqlservr.exe process starts with cold cache.
Since a Failover can occur unexpectedly, customer might need to determine if such event took place and for that purpose customer can determine the timestamp of the last Failover with the help of T-SQL as described in the article How-to determine the timestamp of the last SQL MI failover from the SQL MI how-to series.
Also, you could see the Failover event listed in the Activity Log using the Azure Portal.
Below is a diagram of the failover process:

As you can see from the diagram, on the picture above, the Failover process will introduce a brief moment of unavailability while a new node from the Pool of spares nodes is allocated. In order to minimize the impact of a failover you would need to incorporate in your application a retry-logic. This is normally accomplished detecting the transient errors during a failover (4060, 40197, 40501, 40613, 49918, 49919, 49920, 11001) within a try-catch block of code, waiting a couple of seconds and then retrying the connection (re-connect). Alternatively, you could use the Microsoft.Data.SqlClient v3.0 Preview NuGet package in your application that have already incorporated a retry logic. To know more about this driver see the following article: Introducing Configurable Retry Logic in Microsoft.Data.SqlClient v3.0.0
Notice that that currently that only one failover call is allowed every 15 minutes.
In this article we have introduced the concepts of high availability and explained how it is implemented for the General Purpose service tier. In the second part of where we will cover High Availability in the Business Critical service tier.
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments