This article is contributed. See the original author and article here.
Authors: Lei Sun, Neta Haiby, Cha Zhang, Sanjeev Jagtap
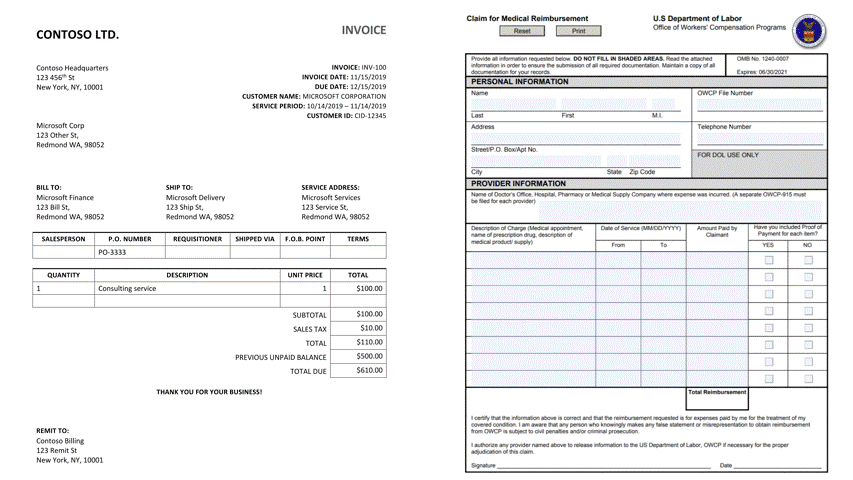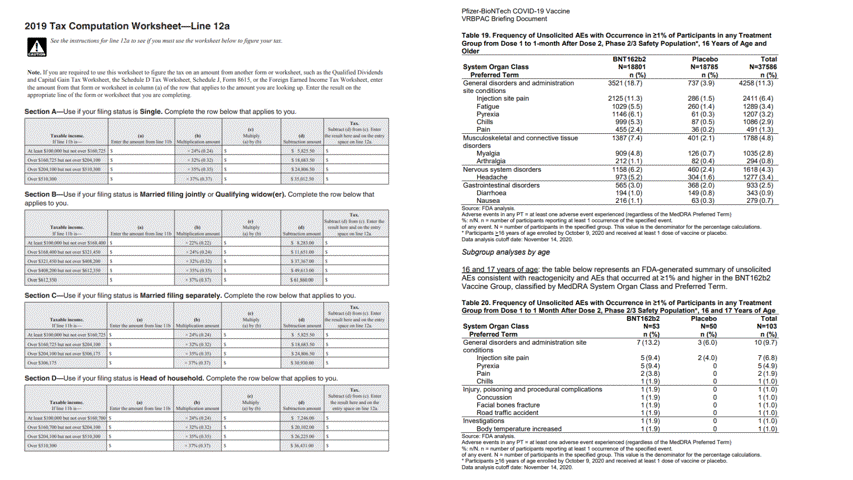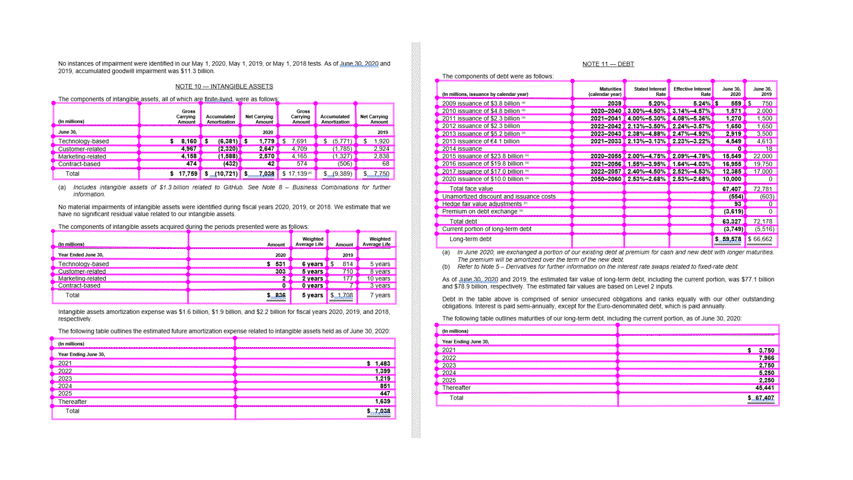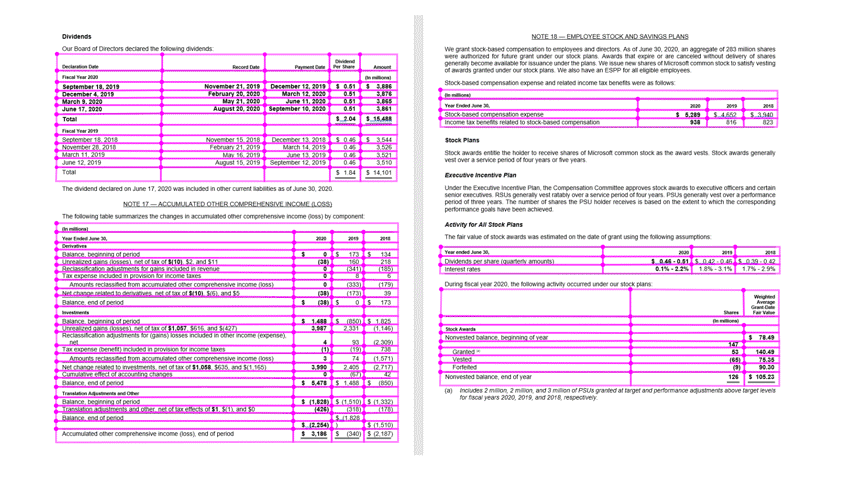
Documents containing tables pose a major hurdle for information extraction. Tables are often found in financial documents, legal documents, insurance documents, oil and gas documents and more. Tables in documents are often the most important part of the document but extracting data from tables in documents presents a unique set of challenges. Challenges include an accurate detection of the tabular region within an image, and subsequently detecting and extracting information from the rows and columns of the detected table, merged cells, complex tables, nested tables and more. Table extraction is the task of detecting the tables within the document and extracting them into a structured output that can be consumed by workflow applications such as robotic process automation (RPA) services, data analyst tools such as excel, databases and search services.
Customers often use manual processes for data extraction and digitization. However, with the new enhanced table extraction feature you can send a document (PDF or images) to Form Recognizer for extraction of all the information into a structured usable data at a fraction of the time and cost, so you can focus more time acting on the information rather than compiling it.

Table extraction challenges
Table extraction from a wide variety of document images is a challenging problem due to the heterogeneous table structures, diverse table contents, and erratic use of ruling lines. To name a few concrete examples, in financial reports and technical publications, some borderless tables may have complex hierarchical header structures, contain many multi-line, empty or spanned cells, or have large blank spaces between neighboring columns. In forms, some tables may be embedded in other more complex tabular objects (e.g., nested tables) and some neighboring tables may be very close to each other which makes it hard to determine whether they should be merged or not. In invoices, tables may have different sizes, e.g., some key-value pairs composed tables may contain only two rows/columns and some line-item tables may span multiple pages. Sometimes, some objects in document images like figures, graphics, code listings, structurally laid out text, or flow charts may have similar textures as tables, which poses another significant challenge for successful detection of tables and reduction of false alarms. To make matters worse, many scanned or camera-captured document images are of poor image quality, and tables contained in them may be distorted (even curved) or contain artifacts or noises. Existing table extraction solutions fall short of extracting tables from such document images with high accuracy, which has prevented workflow applications from effectively leveraging this technology.

Form Recognizer Table extraction
In recent years, the success of deep learning in various computer vision applications has motivated researchers to explore deep neural networks like convolutional neural networks (CNN) or graph neural networks (GNN) for detecting tables and recognizing table structures from document images. With these new technologies, the capability and performance of modern table extraction solutions have been improved significantly.
In the latest release of Form Recognizer, we created a state-of-the-art table extraction solution with cutting-edge deep learning technology. After validating that Faster/Mask R-CNN based table detectors are effective in detecting a variety of tables (e.g., bordered or borderless tables, tables embedded in other more complex tabular objects, and distorted tables) in document images robustly, we further proposed a new method to improve the localization accuracy of such detectors, and achieved state-of-the-art results on the ICDAR-2019 cTDaR table detection benchmark dataset by only using a lightweight ResNet18 backbone network (Table 1).
For the challenge of table recognition or table cell extraction, we leveraged existing CNN/GNN based approaches, which have proven to be robust to complex tables like borderless tables with complex hierarchical header structures and multi-line/empty/spanned cells. We further enhanced them to deal with distorted or even slightly curved tables in camera-captured document images, making the algorithm more widely applicable to different real-world scenarios. Figure 1 below shows a few examples to demonstrate such capabilities.

Easy and Simple to use
Try it out with the Form Recognizer Sample Tool.

Extracting tables from documents is as simple as 2 API calls, no training, preprocessing, or anything else needed. Just call the Analyze Layout operation with your document (image, TIFF, or PDF file) as the input and extracts the text, tables, selection marks, and structure of the document.
Step 1: The Analyze Layout Operation –
https://{endpoint}/formrecognizer/v2.1-preview.2/layout/analyze
The Analyze Layout call returns a response header field called Operation-Location. The Operation-Location value is a URL that contains the Result ID to be used in the next step.
Operation location –
https://cognitiveservice/formrecognizer/v2.1-preview.2/prebuilt/layout/analyzeResults/44a436324-fc4b-4387-aa06-090cfbf0064f
Step 2: The Get Analyze Layout Result Operation –
Once you have the operation location call the Get Analyze Layout Result operation. This operation takes as input the Result ID that was created by the Analyze Layout operation.
https://{endpoint}/formrecognizer/v2.1-preview.2/layout/analyzeResults/{resultId}
The output of the Get Analyze Layout Results will provide a JSON output with the extracted table – rows, columns, row span, col span, bounding box and more.
For example:

Get started
- To get started create a Form Recognizer resource in the Azure Portal and try out your tables in the Form Recognizer Sample Tool. You can also use the Form Recognizer client library or REST API.
Note tables output is included in all parts of the Form Recognizer service – prebuilt, layout and custom in the JSON output pageResults section. - For additional questions please reach out to us at formrecog_contact@microsoft.com
Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments