by Contributed | Jun 29, 2021 | Technology
This article is contributed. See the original author and article here.
Windows Package Manager was announced at Build 2020 and has been in preview since. At Build 2021 the team announced version 1.0, you can see the Roadmap journey the team have been on over the past year and where they are heading here.
Now if you’ve never heard of Windows Package Manager before then in simplistic form it’s a tool that will help you manage the software/package/applications on your machine. It can help you install them, update them, and uninstall them. And a whole lot more. It’s an open-source project that the Microsoft team are excited to work on with the community.
What I want to do today is talk to you about how YOU can help the project.
The Windows Package Manager can help you install over 1,400+ packages or pieces of software onto your machine. If you install the Windows Package Manager and issue the command winget search <SomePackage> you will see what packages are available to install. This is where you can help. By growing that list. And today I want to talk to you about the best practices you should follow when submitting a new package into the Windows Package Manager repository.
Windows Package Manager Manifest Creator Preview
At Build 2021 the team launched another open-source tool, the Windows Package Manager Manifest Creator. This new tool will help you build out the manifest file that is needed to be able to install package or application via Windows Package Manager.
The Windows Package Manager Manifest Creator can be installed on your machine via the Windows Package Manager using the command winget install wingetcreate
Getting Involved
If you’ve ran the winget search <somepackage> command and not found the package or piece of software that you want to install, then you can help to add it to the repository to help you and others in the future.
First, you need to check the following things:
– GitHub account
– Windows Package Manager currently supports installers in the following formats: MSIX, MSI, and EXE, if the piece of software you want to install doesn’t have one of those kinds of installers it can’t be added to the repository.
– If the software comes in MSIX, MSI or EXE format it’s worth checking to see if someone else has already submitted it for consideration, you can do that by checking the current Pull Requests being worked on within the Community Repository
– If the software comes in MSIX, MSI or EXE format and someone else hasn’t already submitted it you need to make sure you have both the Windows Package Manager and Windows Package Manager Manifest Creator installed on your machine.
Now that checklist has been completed, it’s time to start to build the manifest needed.
You can start from scratch at creating your own manifest files, however there is a tool that can help you with the process that can make the whole process a lot easier.
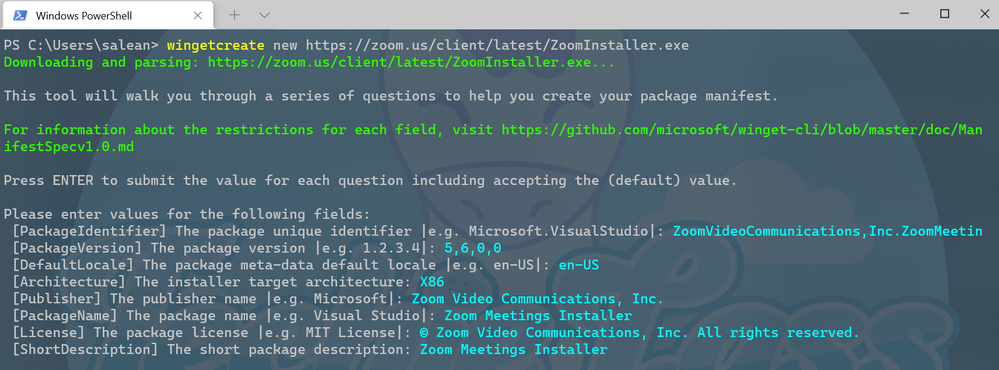
To kick start you should enter the command wingetcreate new
The tool will prompt you for the URL of the software package, this should be a publicly accessible URL and not something that is stored on your OneDrive or the like. The tool will start to query the file and pull some information out. It will start by suggesting a package identifier, package version, default language, the architecture the package will install on (think x86, x64, etc), publisher name, package name, package license and a description for the package. All this information helps people find and install the software.
WingetCreate example wizard
Custom Silent Switches
If the piece of software, you are trying to package up requires a bespoke install switch to make it install silently without any user input you can configure that within the installer.yaml file.
If we take the VMware Workstation Player as an example, we can see within its installer.yaml file it has a couple of configuration lines:
**Screenshot https://github.com/microsoft/winget-pkgs/blob/master/manifests/v/VMware/WorkstationPlayer/16.1.2/VMware.WorkstationPlayer.installer.yaml**
Tags
Another thing that can be done when submitting is adding in tags in your manifest files. Tags will help packages/software be found when folks are searching through the winget search command.
 Searching for anything that relates to audio
Searching for anything that relates to audio
 Tags inside the VLC manifest file
Tags inside the VLC manifest file
These tags help expand the search results beyond the software maker or name of the software.
Validating and Testing
Now that you’ve setup the manifest files it’s time to validate them and test they work as they should before you are ready to submit to the repository.
The first thing to do is validate the manifest files, it will check the syntax and configures it confirms to the standards that it should. If you’ve went through the wingetcreate new process and made no manual changes to the files, then it should pass validation. However, if you have made some manual changes then there might be changes you need to make to pass the validation test.
The command to use to validate your manifest is winget validate –manifest <manifest path>
The path to your manifest file will vary depending on your setup, however it should have been displayed to you at the end of the wingetcreate process.
Once you’ve had the output from the validate command and everything is okay, you can now move on to testing the manifest installs the package/piece of software that you’ve set it up to do. You might have to test this on a separate machine or uninstall the software if you already have it installed to test this properly.
The command you need to use is winget install –manifest <manifest path>
Hopefully, this will go through without any issue and install the software as it should. If there are any issues, then you will need to look at resolving them and going through the process again until it works as expected.
Submitting the manifest
Now the manifest is validated and tested it’s time to submit your contribution to the Microsoft team to check and merge into the repository for the rest of the community to take advantage of.
The first thing to do is set up a Token, that is a GitHub personal access token that can help avoid you having to put your password into the command line for authentication to GitHub. If you haven’t set up a token before you can use this great guide from the GitHub team – Creating a personal access token.
Once you have the token you need to store it into your command line tool for winget to use, you do this by issue wingetcreate –store <token>
You are now ready to submit your creation to the Microsoft team for review. To do this you should issue the command wingetcreate submit <path to manifest>
This will create a repository store within you GitHub profile and then create a pull request on the Windows Package Manager repository.
When that command is complete, it will open a browser session to the pull request (PR). Here you will be asked to complete a checklist.

It will also start to kick off some automated tests, validating the manifest and testing it does what it should do. You can close your browser and check on this later, or you can watch it update its progress.
If any issues are detected you will have to address them, otherwise someone from the Windows Package Manager will check over the submission and either approve or give feedback on improvements.
The team do have some SLA’s that they are working on to ensure that your submissions are reviewed within a timely manner.
Call to Action
So, your call to action is look at Windows Package Manager, see if any of your favourite pieces of software aren’t there and get packaging!
by Contributed | Jun 28, 2021 | Technology
This article is contributed. See the original author and article here.
“I don’t have enough relevant data for my project”! Nearly every data scientist has uttered this sentence at least once. When developing robust machine learning models, we typically require a large amount of high-quality data. Obtaining such data and more so, labelled or annotated data can be time-consuming, tedious and expensive if we have to rely on experts. Hence, there is a compelling need to generate data for modelling using an automated or a semi-automated way. Specifically, in this work, we explore how we can utilize Open AI’s Generative Pre-trained Transformer 3 (GPT-3) for generating data to build models for identifying how credible news articles are.
GPT-3
GPT-3 is a language model that leverages deep learning to generate human-like text. GPT-3 was introduced by Open AI in May 2020 as a successor to their previous language model (LM) GPT-2. It is considered to be better than GPT-2. In fact, with around 175 billion trainable parameters, OpenAI GPT-3’s full version is one of the largest models trained so far.
Fake News Generation
In this blog post, we discuss the collaborative work between Microsoft’s ACE team and the Dataclair AI lab of O2 Czech Republic, where the goal is to identify fake news. Fake news is defined as a made-up story with an intention to deceive or to mislead. The general motive to spread such news is to mislead the readers, damage the reputation of any entity, or gain from sensationalism. The creation of a dataset for identifying credible news requires skilled annotators and moreover, the task of comparing proposed news articles with the original news articles itself is a daunting task as it’s highly subjective and opinionated. This is where the recent advances in natural language modelling and those in text generation capabilities can come to the rescue. We explore how new language models such as GPT-3 can help by generating new data.
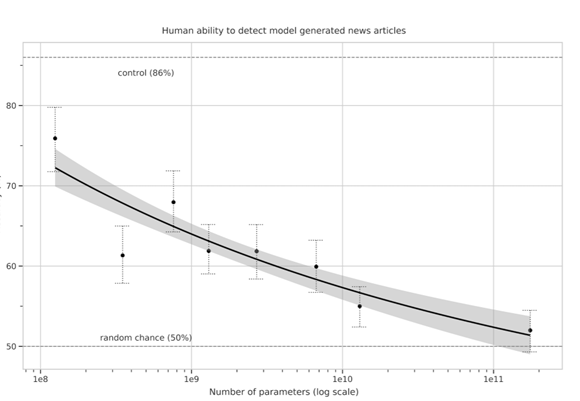
We generate fake news data using GPT-3 by providing prompts that contain a few sample fake news articles in the Czech language. Doing something like this would have been unthinkable a few years ago, but the massive advancement of text generation through language models opened doors to such experiments. As the research paper describing GPT-3 shows, GPT-3 is very good at generating news articles of high quality that even humans are not capable of detecting as computer-generated:
The plot also shows how text generating models improved via having access to more parameters. GPT-3 is the furthest to the right and the plot conveys how accurately people were able to recognize generated articles from those written by humans.
Prompt Engineering
“Prompts” are a way to get the model to produce text by specifying an instruction in natural language and showing some demonstrations of how to follow the instructions well. GPT-3 has an incredible capacity to mimic writing styles. When the prompt is set up correctly, GPT-3 adheres to the example just enough to copy those underlying elements (for example: includes or excludes citations, etc.) and introduce a new twist to the generated text. It is even capable of creating its own complex arguments. Thus, it is not just a replication of pre-existing data, but a creation of new and original articles from which the model can learn.
An example of a prompt and parameters used to generate fake news are as follows in bold. The generated text is in italics.
Generate a news article based on the headline and with the same style of writing as given in the example.
Headline: Where do leftist extremists get the audacity to speak for the nation?
Text:
My fellow Czechs, we must shake off the shame that the USA, Brussels and other countries have been forced on us with the help of our own “experts” and “journalists”. The same people who are now digging into our nation with the help of a genuine community of the USA and Brussels – the Pekarová and other forces…
Parameters:
Temperature: 0.7, Max tokens: 1000, Top p: 1, Frequency penalty: 0, Presence penalty 0
From these parameters, the most important ones are temperature and max tokens. Temperature controls randomness in the text. Therefore, a temperature of 0.7 was chosen to produce less deterministic results that still follow the structure and writing style of the example. Max token value was set to 1000 tokens (~4000 characters) because this is the average length of a news article. It should be noted that when working with GPT-3, the process of finding the right parameters is about experimentation.
Admittedly, there are still challenges to deal with. One of them is the need to manually inspect if GPT-3 returns articles that are relevant and in the right credibility category. Due to the sensitivity of the topic of article credibility, data quality checks will need to be implemented. Another minor limitation is that while GPT-3 understands many articles that it has been trained on, it has problems when analysing newer topics. For example, it is unable to fully grasp the significance of COVID-19 and it usually avoids writing about it due to not having enough knowledge about the global pandemic. Thus, it generates less realistic articles when faced with such a topic.
Nevertheless, if those obstacles are kept in mind, GPT-3 can help make dataset creation faster and more reliable. This is something that the O2 CZ team plans to utilize for their disinformation recognition AI model. “Our model extracts different features (aggressivity, clickbait etc.) from the article via smaller extraction modules. Those features are then evaluated by the deep learning classification module and subsequently transformed into one number by the ensemble method. For the system to work, we need as many articles as possible for training the classification module, which we hope to obtain with the help of GPT-3,” described by Filip Trhlik, a Data Scientist at the Dataclair AI lab.

Disinformation recognition AI model diagram
In conclusion, artificially generating new data is a very exciting use case of language models and even though the data generated requires a small amount of manual inspection, it is very beneficial for downstream modelling tasks. The ability to generate a large amount of synthetic data in a short time is very promising.
by Contributed | Jun 28, 2021 | Technology
This article is contributed. See the original author and article here.
Managing long term log retention (or any business data)
The shared responsibility model of the public cloud helps us all pass of some of the burden that needed to be solved completely in-house. A notable example of this is the protection and retention of business-critical data, whether it be the digital copies of documents sent to customer’s, financial history records, call recordings or security logs. There are many types of records and objects that we have business, compliance, or legal reasons to ensure that an original point in time copy is kept for a set period.
One of the excellent features that enable this in Azure is Immutable storage, linked with Lifecycle management rules.
Protecting Security log exports
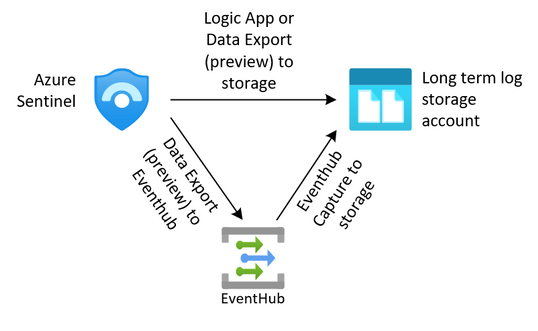
For security teams, this is often a requirement to keep the security logs from the SIEM for an extended period. We can export our data from our log analytics workspaces through several methods outlined in this article (hyperlink here). Once we have exported that data to an Azure storage account we need to protect it from change or deletion for the required time period. We also need to enforce our business rules in ensuring that data that is no longer needed is removed from the system.
The solution we are building here allows for the storage of these logs.
Immutable storage
Immutable storage for Azure Blob storage enables users to store business-critical data objects in a WORM (Write Once, Read Many) state. This state makes the data non-erasable and non-modifiable for a user-specified interval. For the duration of the retention interval, blobs can be created and read, but cannot be modified or deleted.
Immutable storage polices are two types.
- Time base Polices – These allow you to set the minimum retention period for the storage objects. During that time both writes and deletes to the object will be blocked. When the policy is locked (more on that later) the policy will also prevent the deletion of the storage account. Once the retention period has expired, the object will continue to be protected from write operations but delete operations can be executed.
- Legal Hold Policies – These polices allow for a flexible period of hold and can be removed when no longer needed. Legal hold polices need to be associated with one or more tags that are used as identifiers. These tags are often used to represent case or event ID’s. You can place a Legal Hold policy on any container, even if it already has a time-based policy.
For the purposes of this post, we are going to focus on the use of the time-based polies, but if you want to read more on legal hold polices, they can be found here.
Time based polices are implemented simply on a storage container through PowerShell, the Azure CLI or the Portal, but not through ARM templates. This article will go through the use of the portal, the PowerShell and CLI code can be found here.

When adding a new Time-based policy, you will need to specify the number of days to enforce protection, this is a number of days between 1 and 146,000 days (400 years – that’s a really long time). At the same time, you can allow for append blobs to continue to be appended to. For systems that are continually adding to a log through the use of Append Blobs (such as continuous export from Log Analytics), this allows them to keep appending to the blob while it is under the policy. Note that the retention time restarts each time a block is added. Also note that a Legal hold policy does not have this option, and thus will deny an append write if a placed on.

When a time-based policy is first created it starts in an unlocked state. In this state you can toggle the append protection and change the number of days of protection as needed. This state is for testing and ensuring all settings are set correctly, you can even delete the policy if it was created by mistake.

Once the policy settings are confirmed to be correct, it is then time to lock the policy.
Locking the policy is irreversible and after it cannot be deleted. You must delete the container completely, and this can only be done once there are no items that are protected from deletion by a policy. Once locked you can only increase the number of days in the retention setting (never decrease) five times.

Lifecycle management
While protecting the data from deletion or change is half of the problem, we must also consider enforcing removal of data in line with retention policies. We can also take additional actions to contain the costs of the storage account by altering the tiers of storage between Hot, Cool and Archive.
Lifecycle management rules of a storage account can automatically remove the storage objects we no longer need through a simple rule set.
Note: if you enable the Firewall on the storage account, you will need to allow “Trusted Microsoft Services”, otherwise the management rules will be blocked from executing. If your corporate security policy does not allow this exception, then you won’t be able to use the management rules outlined here, but you can implement a similar process though an alternate automation mechanism inside your network.
Lifecycle management rules are set at the Storage Account level and are simple enough to configure. For our logs we just want to set a rule to automatically delete the logs at the end of our retention period.
Again, we will be going through the creation using the portal, but these can be done through PowerShell or ARM template, instructions are here.
At the Storage account select Lifecycle management, and then Add a rule.

Give the rule a descriptive name and set the scope to capture all the appropriate objects that you need to manage.

Set the number of days you want to keep the object and then set the delete action.
Make sure that the number of days is longer than the immutable time-based policy otherwise the rule will not be able to delete the object.

Finally complete your rule.
The rule will continuously evaluate the storage account cleaning up any files that have past their required date.
Note: if you needed to keep some specific files for a more extended period, you could consider a Legal Hold policy on those objects that would then stop the management rule from processing them.
Long Term Costs
Storing these items for such an extended period can often lead into larger costs.
We can also add some additional rules to help us control the costs of the storage.
An important consideration here is the fact that the immutable storage policies will continue to allow us to move the storage between tiers while keeping the data protected from change or deletion.
Note: Lifecycle management rules for changing the storage tier today only apply to Block Blob, not Append Blob.
Going thought the same process as above to create a rule, though this time we set the last accessed number of days and then select the “move to cool” action. This will enable the system to move unused Block Blobs to the cool tier.

You can further enhance this with an additional rule to move the Block Blob to archive after a further date. There is no requirement to move to cold before moving to archive, so if that suits your business outcome you can move it directly to archive.

Keep in mind that analytical systems that leverage the storage system (such as Azure Data Explorer) won’t be able to interact with archived data and it must be rehydrated back to cool or hot to be used.
Timeline
With these two systems in place, we have set up our logs to be kept for our required period, manage out costs and then automatically removed at the end.

Summary
While in this article we have focused on applying the protection to the logs from the monitoring systems or SIEM, the process and protection applied here could suit any business data that needs long term retention and hold. This data could be in the form of log exports, call recordings or document images.

by Contributed | Jun 28, 2021 | Technology
This article is contributed. See the original author and article here.
The Azure Percept is a Microsoft Developer Kit designed to fast track development of AI (Artificial Intelligence) applications at the Edge.
Percept Specifications
At a high level, the Percept Developer kit has the following specifications;
Carrier (Processor) Board:

- NXP iMX8m processor
- Trusted Platform Module (TPM) version 2.0
- Wi-Fi and Bluetooth connectivity
Vision SoM:

- Intel Movidius Myriad X (MA2085) vision processing unit (VPU)
- RGB camera sensor
Audio SoM:

- Four-microphone linear array and audio processing via XMOS Codec
- 2x buttons, 3x LEDs, Micro USB, and 3.5 mm audio jack
Percept Target Verticals
The Percept is a Developer Kit with a variety of target industries in mind. As such, Microsoft have created some pre-trained AI models aimed at those markets.

These models can be deployed to the percept to quickly configure the Percept to recognise objects in a set of environments, such as;
- General Object Detection
- Items on a Shelf
- Vehicle Analytics
- Keyword and Command recognition
- Anomaly Detection etc
Azure Percept Studio
Microsoft provide a suite of software to interact with the Percept, centred around Azure Percept Studio, an Azure based dashboard for the Percept.
Azure Percept Studio is broken down into several main sections;
Overview:

This section gives us an overview of Percept Studio, including;
- A Getting Started Guide
- Demos & Tutorials,
- Sample Applications
- Access to some Advanced Tools including Cloud and Local Development Environments as well as setup and samples for AI Security.
Devices:

The Devices Page gives us access to the Percept Devices we’ve registered to the solution’s IoT Hub.
We’re able to click into each registered device for information around it’s operations;

This area is broken down into;
- A General page with information about the Device Specs and Software Version
- Pages with Software Information for the Vision and Speech Modules deployed to the device as well as links to Capture images, View the Vision Video Stream, Deploy Models and so on
- We’re able to open the Device in the Azure IoT Hub Directly
- View the Live Telemetry from the Percept
- Links with help if we need to Troubleshoot the Percept
Vision:

The Vision Page allows us to create new Azure Custom Vision Projects as well as access any existing projects we’ve already created.
Speech:

The Speech page gives us the facility to train Custom Keywords which allow the device to be voice activated;

We can also create Custom Commands which will initiate an action we configure;

Percept Speech relies on various Azure Services including LUIS (Language Understanding Intelligent Service) and Azure Speech.
Other Resources
by Contributed | Jun 28, 2021 | Technology
This article is contributed. See the original author and article here.
Hello everyone, we are adding on to the Configuration Manager and the Microsoft cloud platform integration video series. Here is part 12 of the series. This series is recorded by Steve Rachui, a Microsoft principal customer engineer.
This session focuses on the ability to leverage ConfigMgr as the authority for synchronizing collections to Azure AD groups. The tutorial demonstrates how to configure this capability and demonstrates the synchronization in action. Steve discusses reasons why this capability is beneficial.
Posts in the series
Go straight to the playlist

Recent Comments