This article is contributed. See the original author and article here.
Azure Synapse Analytics brings the worlds of data integration, big data, and enterprise data warehousing together into a single service for end-to-end analytics—at cloud scale. In this blog post we will focus on using T-SQL to explore and analyze data.
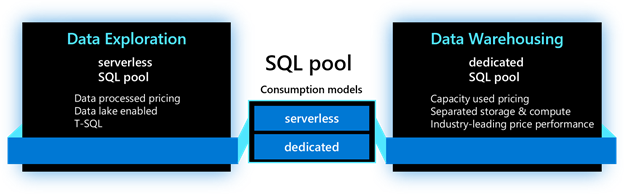
Every Synapse workspace includes a built-in serverless SQL pool designed to enable quick exploration of data stored in the data lake based on pay-per-query pricing. You can also provision one or more dedicated SQL pools to your workspace that lets you run high-performance analytics against data stored in tables with columnar storage.
Both serverless and dedicated SQL pools can be used within the same Synapse workspace, providing the flexibility to choose one or both options to cost-effectively manage your SQL analytics workloads. With Azure Synapse, you can use T-SQL to directly query data within a data lake for rapid data exploration and take advantage of the full capabilities of a data warehouse for more predictable and mission-critical workloads. With both query options available, you can choose the most cost-effective option for each of your use cases, resulting in cost savings across your business.
This post explores 2 consumption choices when exercising analytics using Synapse SQL (serverless and dedicated SQL pools) and examines the power and flexibility provided by Azure Synapse when both are used to execute T-SQL workloads. In addition, we will explore options to control cost when using both models.
Consumption choices
1. Serverless SQL pool
To enable easy exploration and transformation of data in your data lake you can use a serverless SQL pool. One can directly query external files stored in Azure storage without copying or loading data into a specialized store, all using familiar T-SQL dialect. A default, built-in, endpoint for this service is provided within every Synapse workspace and you can start querying data as soon as your workspace is created.
As the name implies, the serverless SQL pool is serverless, which means there is no infrastructure to manage, no upfront costs, and no resource reservations required to begin using the service. The serverless SQL pool follows pay-per-use model, so you are only charged for the data processed by queries you run.
- Import sample dataset from Knowledge Center
To demonstrate how easy it is to start with querying data in the data lake using a serverless SQL pool, let’s import some sample data from the Knowledge Center gallery and run some queries to explore the dataset. First, select the Data Hub from the left-hand menu in Synapse Studio, select the + (Add) icon on the Data Hub, and then select Browse gallery.

The Browse gallery link on the Data Hub’s add button menu is highlighted.
On the Gallery page, select the Datasets tab, choose the Bing COVID-19 Data sample, and then select Continue.

Within the Knowledge Center, the Datasets tab is selected, and the Bing COVID-19 Data sample dataset is highlighted.
On the Bing COVID-19 Data page, you have to opportunity to preview the sample data. Select Add dataset to initiate a background process to import the Open dataset and create a Linked Service for it within Synapse Studio.

The Bing COVID-19 Data sample dataset is displayed in the Knowledge Center preview page.
You can find the Linked Service for the downloaded sample dataset on the Linked tab within the Data Hub. It is named bing-covid-19-data and can be found under Azure Blob Storage, within the Sample datasets container.

On the Linked Services tab of the Data Hub, the bing-covid-19-data folder is highlighted under the Azure Blob Storage Sample Datasets container.
- Query files in your data lake using a serverless SQL pool
Next, we want to open the dataset using a T-SQL query. After locating Linked Service for the Bing COVID-19 sample dataset, select the Actions ellipsis next to it to display the actions menu.

The Actions menu ellipsis is highlighted next to the bing-covid-19-data sample dataset.
In the Action menu, select New SQL script and Select TOP 1000 rows.

On the Actions menu for the sample dataset, New SQL script and Select TOP 100 rows are highlighted.
The previous action results in a new SQL script tab opening within Synapse Studio. This script contains the auto-generated T-SQL code for reading the top 100 rows of data from the bing_covid-19_data.parquet file located in Azure Storage. The query uses the OPENROWSET(BULK…) function to access files within the data lake.
Azure Synapse uses the OPENROWSET(BULK…) function to enable accessing files in Azure Storage. The OPENROWSET function reads the contents of an external data source and returns its content as a set of rows. The OPENROWSET function is referenced in the FROM clause of your query, allowing it to act as if it were a table named OPENROWSET. A built-in BULK provider enables data from files to be read and returned as a rowset.
To query data in the data lake using a serverless SQL pool, ensure that your serverless SQL pool, named Built-in, is selected in the Connect to box on the SQL script tab’s toolbar.

The auto-generated T-SQL script is displayed, and the Connect to textbox containing Built-in is highlighted.
Select Run on the SQL script tab’s toolbar to execute the query using the serverless SQL pool resource.

The Run button is highlighted on the SQL script toolbar, and the results of the query execution are displayed in the Results pane.
- Execute GROUP BY query with serverless SQL pool
The previous query demonstrates how quickly you can query and explore data contained within files stored in Azure Storage. Now, let’s execute a query to perform some basic transformations on the sample dataset and calculate the average number of new daily confirmed cases and deaths by region.
Modify the code in the SQL script tab by making the following changes:
– Replace TOP 100 * with Country_region AS Region, AVG(Confirmed_change) AS AverageDailyConfirmedCases, AVG(Deaths_change) AS AverageDailyDeaths.
– Append GROUP BY Country_region to the end of the query, before the ; after [result].
Your final query should look similar to the following:
SELECT
Country_region AS Region, AVG(Confirmed_change) AS AverageDailyConfirmedCases, AVG(Deaths_change) AS AverageDailyDeaths
FROM
OPENROWSET(
BULK ‘https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/bing_covid-19_data/latest/bing_covid-19_data.parquet‘,
FORMAT = ‘parquet’
) AS [result] GROUP BY Country_region;
As you did previously, execute the updated query by selecting Run on the toolbar and observing the Results pane.

The Run button is highlighted on the SQL script toolbar, and the updated SELECT and added GROUP BY statements are highlighted within the query. The results of the transformation query are displayed in the Results pane.
The serverless SQL pool supports the whole range of GROUP BY options, giving you the ability to aggregate data stored in external files into a summary set of rows.
- Create an external table
We will end our overview of using the serverless SQL pool resource by creating a serverless SQL pool database and defining an external table. The serverless SQL pool is an interactive query service over external data in Azure storage. As such, you cannot create tables in serverless SQL pool databases. You can, however, define external tables using the CREATE EXTERNAL TABLE T-SQL command. External tables point to data located in Hadoop, Azure Storage blob, or Azure Data Lake Storage. For the serverless SQL pool, you can use external tables to query data in Azure Storage using T-SQL statements. You can also use external tables to write serverless SQL pool query results to files in Azure Storage.
As you did earlier, select the Action menu ellipsis for the bing-covid-19-data Linked Service, but this time select New SQL script and Create external table from the menu.

On the Actions menu for the sample dataset, New SQL script and Create external table are highlighted.
On the Create external table dialog, ensure Built-in is selected in the SQL pool dropdown, then select Select a database and select + New.

On the Create external table dialog, New is highlighted under Select a database.
On the Create SQL database dialog, enter ServerlessSql in the Name field and select Create.

ServerlessSql is entered into the Name box and highlighted on the Create SQL database dialog.
Back on the Create external table dialog, enter BingCovidData into the External table name field and select Create.

BingCovidData is entered into the External table name field, and the Create button is highlighted.
A new T-SQL script tab will open in Synapse Studio with the code to create an external table from the data lake file. This auto-generated script contains the three steps necessary to create an external table using serverless SQL pool.
– Create an external file format to specify the actual layout of the data referenced by the external table.
– Create an external data source, which is used to connect to your storage account.
– Create an external table to generate an external table that enables Azure Synapse to access data stored in Azure Storage.

The three steps, (1) create an external file, (2) create an external data source, and (3) create an external table, are highlighted within the auto-generated T-SQL code.
The script also contains a SELECT TOP 100 statement to query the newly created external table. Before running the query, verify the Connect to box is set to Built-in and note the value in the Use database dropdown. The database is set to the new SQL database created when you were generating the script for creating the external table.
Select Run from the toolbar to execute the query to create and query the BingCovidData external table.

Built-in is highlighted in the Connect to box, and the new ServerlessSql database is selected in the Use database dropdown. The Run button is highlighted on the toolbar.
The newly defined database and the external table will now be accessible on the Data Hub’s Workspace tab, under Databases. From here, you can query the table just like you would any table in a SQL database.

On the Data Hub’s Workspace tab, the ServerlessSql database and External tables are expanded, and the dbo.BingCovidData table is highlighted.
You may need to select the Refresh button in the top right corner of Synapse Studio to see the database.
With each of these queries, as with all queries executed using a serverless SQL pool, you are only charged for the data processed by queries you run. This pay-per-use model helps provide a cost-effective way to explore data and execute ad-hoc queries against external data.
2. Dedicated SQL pool
To exercise enterprise data warehousing features available in Azure Synapse, provision and use dedicated SQL pools. Data is stored in tables with columnar storage, significantly reducing data storage costs and improving query performance. Once information is stored, you can run analytics at a massive scale. Compared to traditional database systems, queries finish in seconds instead of minutes or hours instead of days.
After you create a dedicated SQL pool in your Synapse workspace, you can import big data using simple to use COPY statement and then use the power of the distributed query engine to run high-performance analytics.
- Add a dedicated SQL pool
There are two paths you can use to add a dedicated SQL pool to your Synapse workspace. You can create one via the Azure portal or from within Synapse Studio.
From the Azure portal, select the New dedicated SQL pool link from your Synapse workspace blade.

The new dedicated SQL pool button is highlighted on the toolbar of a Synapse workspace blade in the Azure portal.
To add a dedicated SQL pool to your Synapse workspace from within Synapse Studio, navigate to the Manage Hub, select SQL pools, and then select the New button.

In Synapse Studio, the Manage Hub and SQL pools are selected, and the New button is highlighted.
The Manage Hub in Synapse Studio allows you to view and manage your SQL pools.
The process for creating the new dedicated SQL pool is the same after that. On the Create dedicated SQL pool Basics tab, you specify a name for your dedicated SQL pool and choose your desired performance level.

The Create dedicated SQL pool dialog is displayed, with DedicatedSql entered into the SQL pool name field.
The performance level can range from DW100c to DW30000c. To learn more about resource consumption, check out the Synapse SQL resource consumption article in the Azure Synapse Analytics documentation.
You can then select Review + create, which sets the default values in the Additional settings tab. Then, select Create to provision your dedicated SQL pool.

A summary of the configure settings for the dedicated SQL pool is displayed, and the Create button is highlighted.
- Create an external table
As with serverless SQL pool, we can create external tables in dedicated SQL pool to provide pointers to external data. As you did previously for the serverless SQL pool queries, navigate to the Linked tab of the Data Hub, select the Action menu ellipsis for the bing-covid-19-data Linked Service, then select New SQL script and Create external table from the menu.

On the Actions menu for the sample dataset, New SQL script and Create external table are highlighted.
On the Create external table dialog, select your dedicated SQL pool, DedicatedSql, in the Select SQL pool dropdown, and then enter BingCovidData as the external table name, and select Create.

The create external table dialog is displayed with the dedicated SQL pool selected and BingCovidData entered into the external table name field.
Select Run on the toolbar to execute the script and create the external table. When the script execution completes, select the Workspace tab within the Data Hub and expand DedicatedSql and External Tables under databases to view the new external table.

The BingCovidData external table is highlighted in the DedicatedSql database on the Data Hub.
Select the Actions menu ellipsis next to BingCovidData and select New SQL script and Select TOP 100 rows.

Select top 100 rows is highlighted in the Actions menu.
Execute the query by selecting Run from the toolbar, as you have done previously, to view the table’s data.
- Create table in the data warehouse
The simplest and fastest way to create a table in the data warehouse is to use the CREATE TABLE AS SELECT (CTAS) statement. CTAS is one of the most important T-SQL features available in dedicated SQL pool. It creates a new table based on the output of a SELECT statement.
To demonstrate how to use the CTAS statement, let’s use it to copy aggregated data from the BingCovidData external table into a new table in the data warehouse. Select the Actions menu ellipsis next to the DedicatedSql (SQL) database, and then select New SQL script and Empty script.
In the empty SQL script pane, paste the following code:
CREATE TABLE [dbo].[CovidRegionalDailySummary]
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT
Country_region AS Region,
AVG(Confirmed_change) AS AverageDailyConfirmedCases,
AVG(Deaths_change) AS AverageDailyDeaths
FROM [dbo].[BingCovidData]
GROUP BY Country_region
With CTAS, we specify the new table name with the CREATE TABLE statement and can also specify both the distribution of the table data and the table structure type. We complete the statement with the AS SELECT statement and specify the source table in the FROM clause.
Execute the script to create the CovidRegionalDailySummary in your data warehouse. You can then find the new table under Tables in the DedicatedSql (SQL) database on the Data Hub’s Workspace tab. Select the tables Actions menu ellipsis and create a new Select TOP 100 rows query.

The CovidRegionalDailySummary table is highlighted under Tables in the dedicated SQL pool.
Execute the query and observe the results.

The results of the new aggregated data table are displayed.
Cost control
The ability to use serverless and dedicated SQL pools grants you flexibility in controlling costs. And the separation of storage and compute allows you to maintain better cost control for your resources There are also additional cost control options available from the Manage Hub in the Synapse Studio.
1. Serverless SQL pool
Serverless SQL pool is a pay per query service that automatically adjusts based on your requirements. The service frees you from managing infrastructure and needing to pick the right size for your solution.
The cost control feature for a serverless SQL pool enables you to set one or more budgets for the amount of data (in TB) that can be processed in a day, week, or month. To configure cost control for serverless SQL pool in the Synapse Studio, navigate to Manage Hub and select SQL pool under Analytics pools. As you hover over the serverless SQL pool, the cost control icon will become visible. Select this icon to open the cost control dialog.

The Cost Control icon is highlighted for the serverless SQL pool.
On the Cost Control dialog, you can select the workspace budget limit, depending on your requirements.

The Cost Control dialog and its various options are displayed.
2. Dedicated SQL pool
Controlling costs for your dedicated SQL pool is handled by pausing the SQL pool or scaling down.
To pause your dedicated SQL pool in Synapse Studio, simply navigate to Manage Hub and select SQL pool under Analytics pools. As you hover over the dedicated SQL pool, the pause icon will become visible. Select this icon to pause the dedicated SQL pool.

The pause icon is highlighted for the dedicated SQL pool.
To scale the dedicated SQL pool in the Synapse Studio, navigate to Manage Hub and select SQL pool under Analytics pools. As you hover over the dedicated SQL pool, the scale icon will become visible. Select this icon to open the scale dialog.

The scale icon is highlighted for the dedicated SQL pool.
On the Scale dialog, select the desired performance level and select Apply.

The Scale dialog for the dedicated SQL pool is displayed.
Conclusion
This post discussed using both serverless and dedicated SQL pools to perform queries and analysis on your data. The ability to use dedicated and serverless SQL pools within a single Synapse workspace empowers you to choose the most cost-effective option for each of your analytics workloads.
Try out this tutorial today by creating an Azure Synapse workspace with a dedicated SQL pool.
- Sign up for an Azure free account and receive $200 of credit to try Azure Synapse
- Create an Azure Synapse workspace in minutes to access these new features
- Embark on your Azure Synapse self-study journey with the Microsoft Learn materials
- Check this blog daily to see a roundup of all the new tutorial blogs that will be posted for the next two weeks.

Brought to you by Dr. Ware, Microsoft Office 365 Silver Partner, Charleston SC.

Recent Comments